·题目附件:
1
2
3
4
| 通过百度网盘分享的文件:ylctf.rar
链接:https://pan.baidu.com/s/14EabOzqDfV1QCff9bjRchQ?pwd=59hg
提取码:59hg
--来自百度网盘超级会员V3的分享
|
misc
[Round 1] hide_png
下载附件
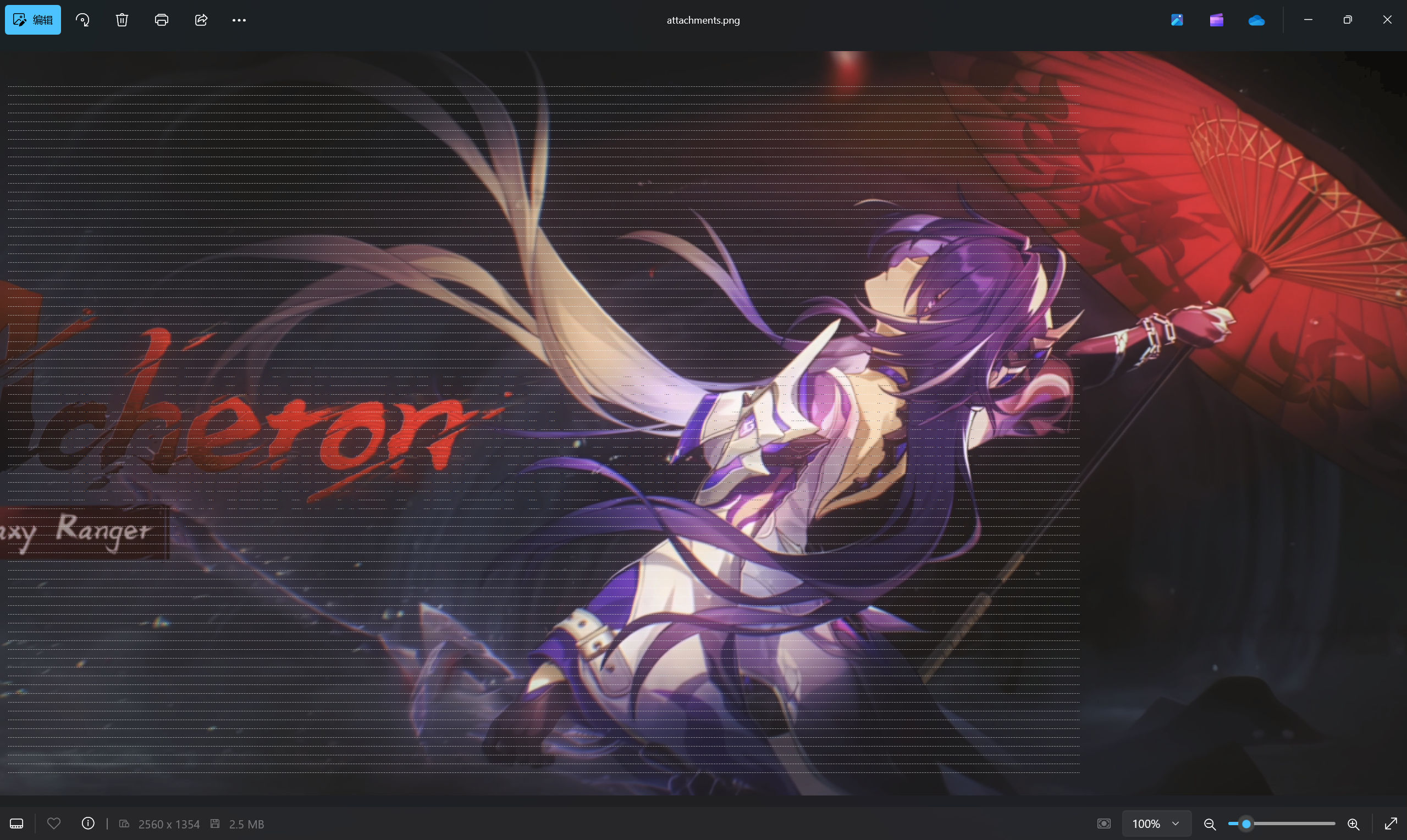
但是看不出具体是什么,放大查看像素的关系,可以发现这样一个式子【从左上角第一个点算作(0,0),其位置为(15,64),最终可得到对应位置的式子(i+5)*3,(j+4)*16】
需要再统计一下,内嵌的这个图片的长宽像素各有多少【最右下角为 (1968,1312) 对应i j 为 651,78 所以共652x79个】,然后编写脚本来读取各个点的像素。
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| from PIL import Image
f = Image.open('E:\\脚本合集\\赛题脚本\\YLCTF\\读取像素\\attachments.png')
img = Image.new("RGB", (652,79))
for i in range(650):
for j in range(79):
t = f.getpixel(((i+5)*3,(j+4)*16))
img.putpixel((i,j),(t))
img.show()
img.save('E:\\脚本合集\\赛题脚本\\YLCTF\\读取像素\\output.png')
|
运行得到
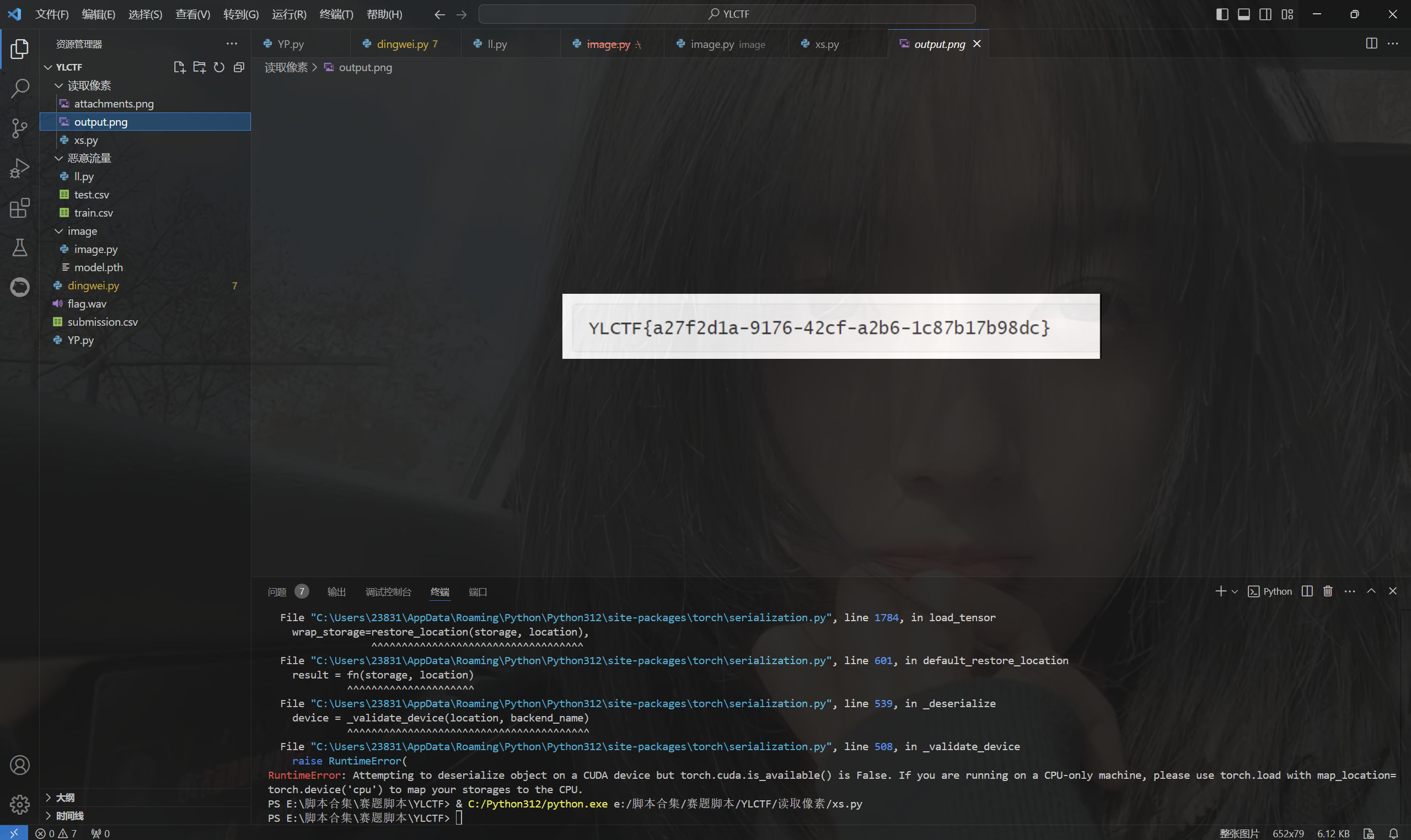
最后flag为YLCTF{a27f2d1a-9176-42cf-a2b6-1c87b17b98dc}
[Round 1] plain_crack
下载附件
本题使用 pyminizip 对文件进行了加密压缩
那么明文爆破需要一个压缩类型一样且压缩后crc32一样的zip才可以进行爆破。
脚本压缩build.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| # -*- coding:utf8 -*-
import pyminizip
from hashlib import md5
import os
def create(files, zfile):
pyminizip.compress_multiple(files,[], zfile, None, 0)
pass
if __name__ == '__main__':
files = ['build.py']
zfile = 'build.zip'
create(files, zfile)
|
运行得到

明文攻击

保存文件
改后缀zip查看
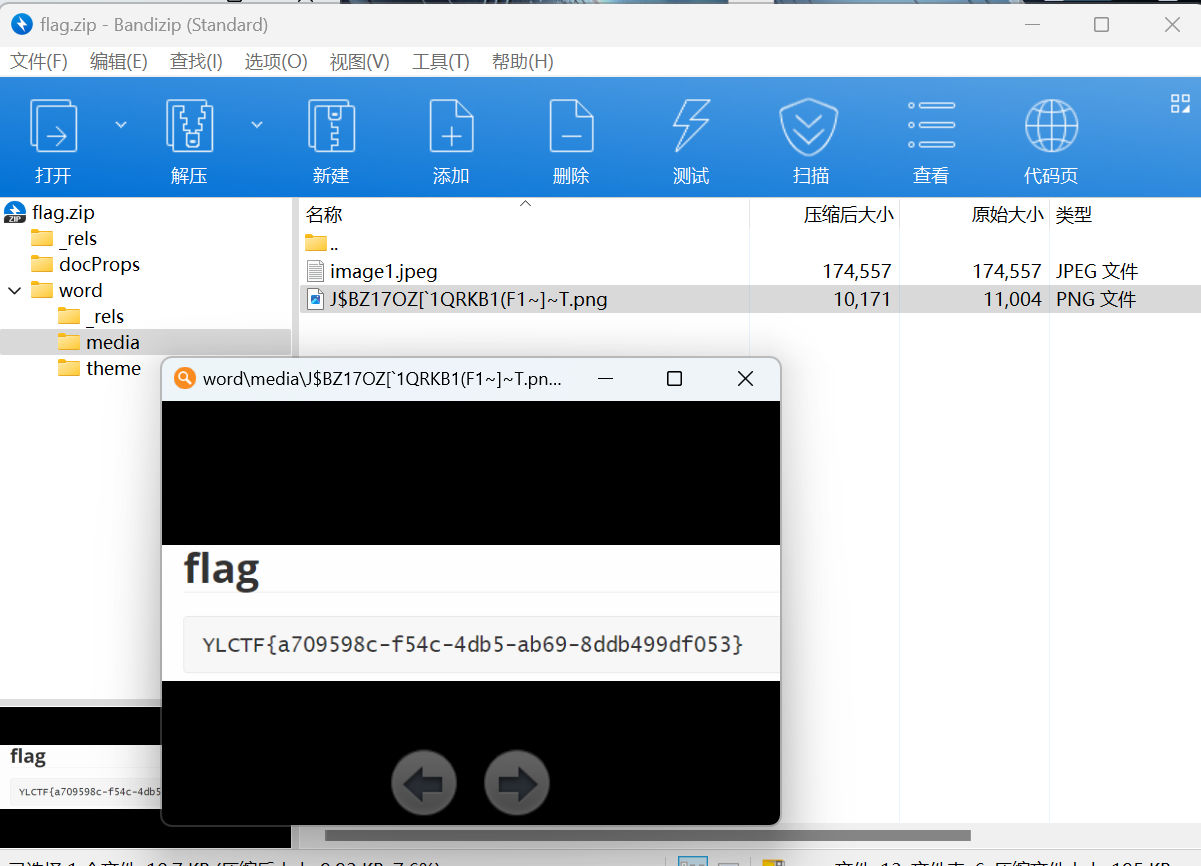
最后flag为YLCTF{a709598c-f54c-4db5-ab69-8ddb499df053}
[Round 1] pngorzip
下载附件

stegsolve工具来查看隐写
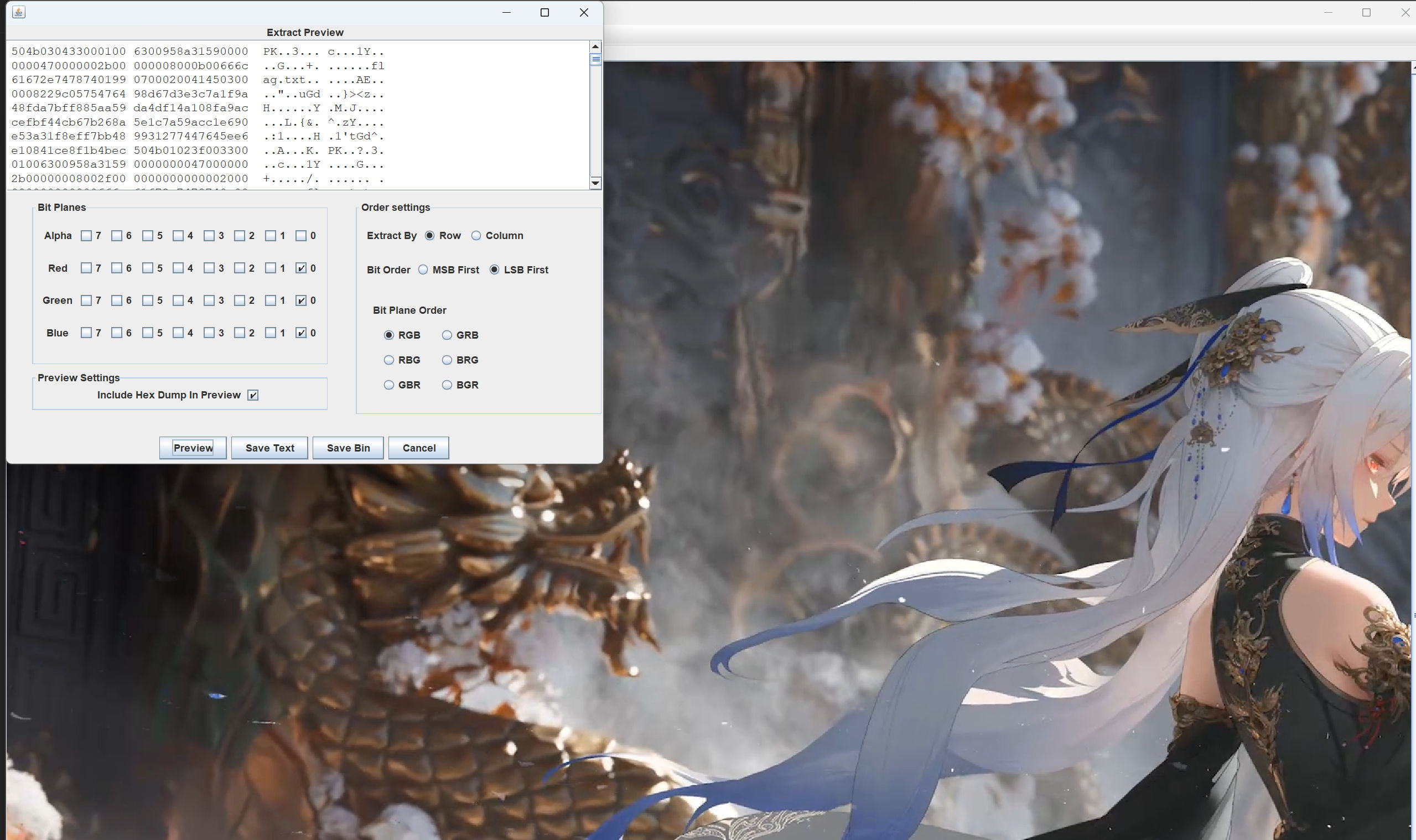
发现藏有压缩包,导出
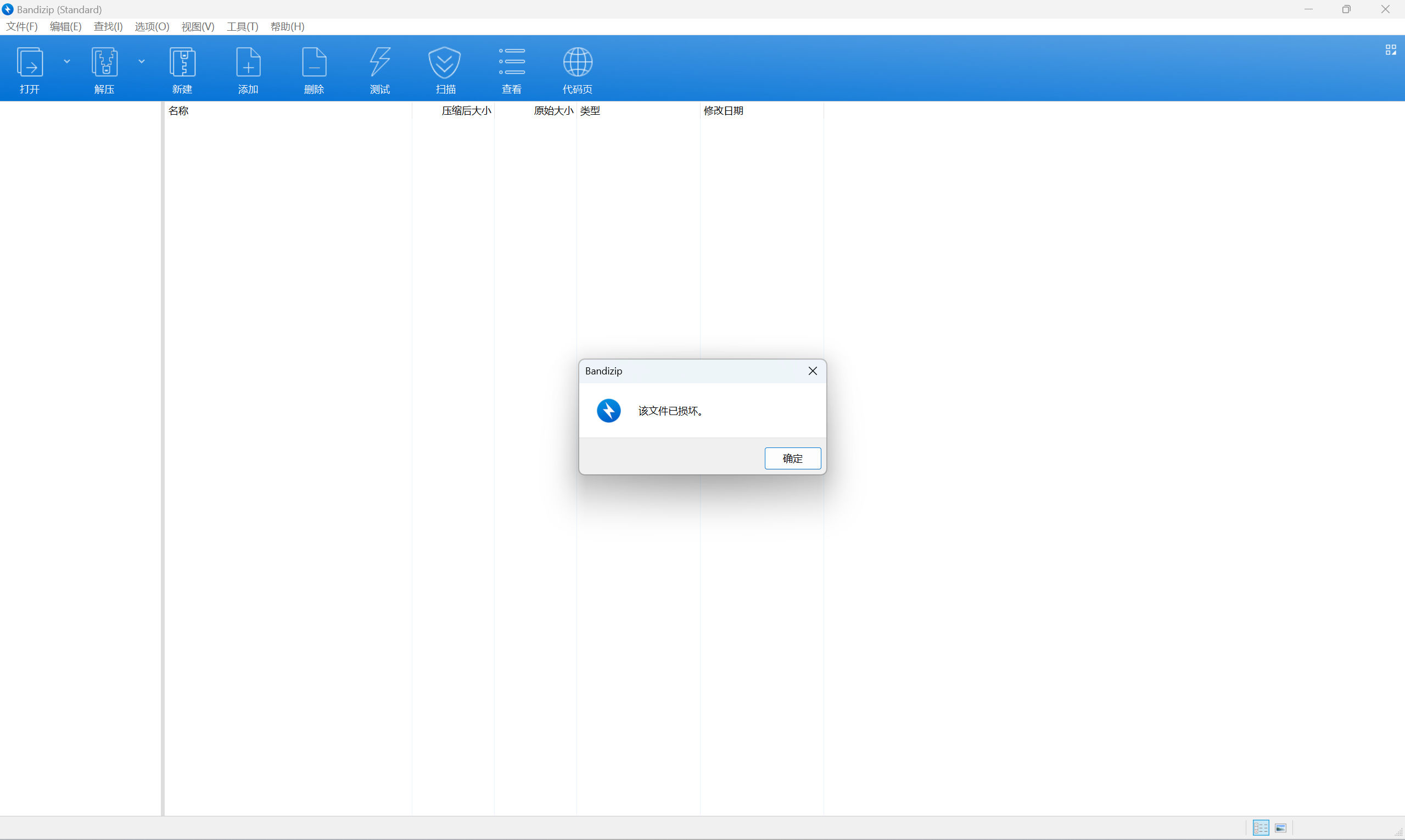
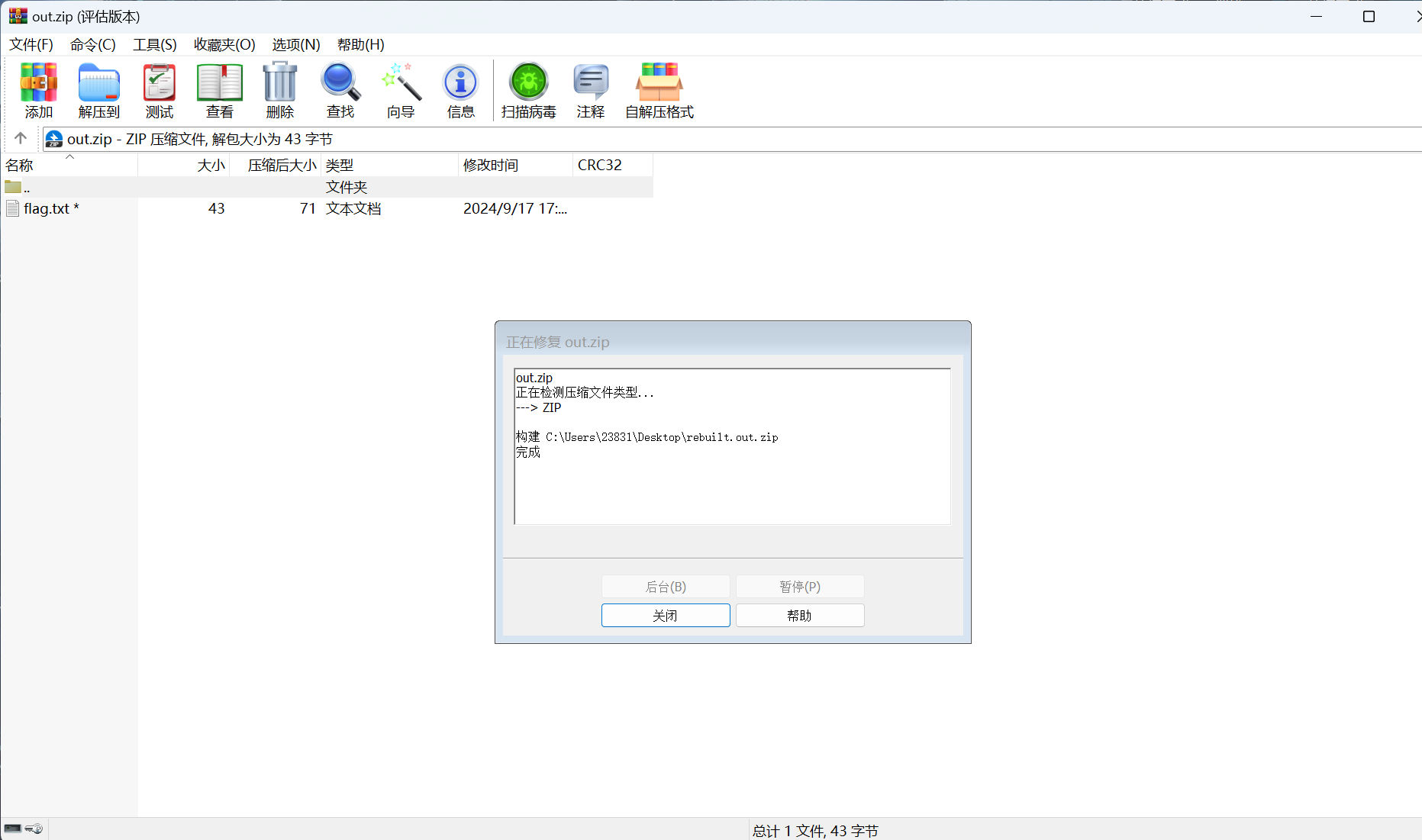
winrar修复文件
根据提示
掩码爆破
解压压缩包
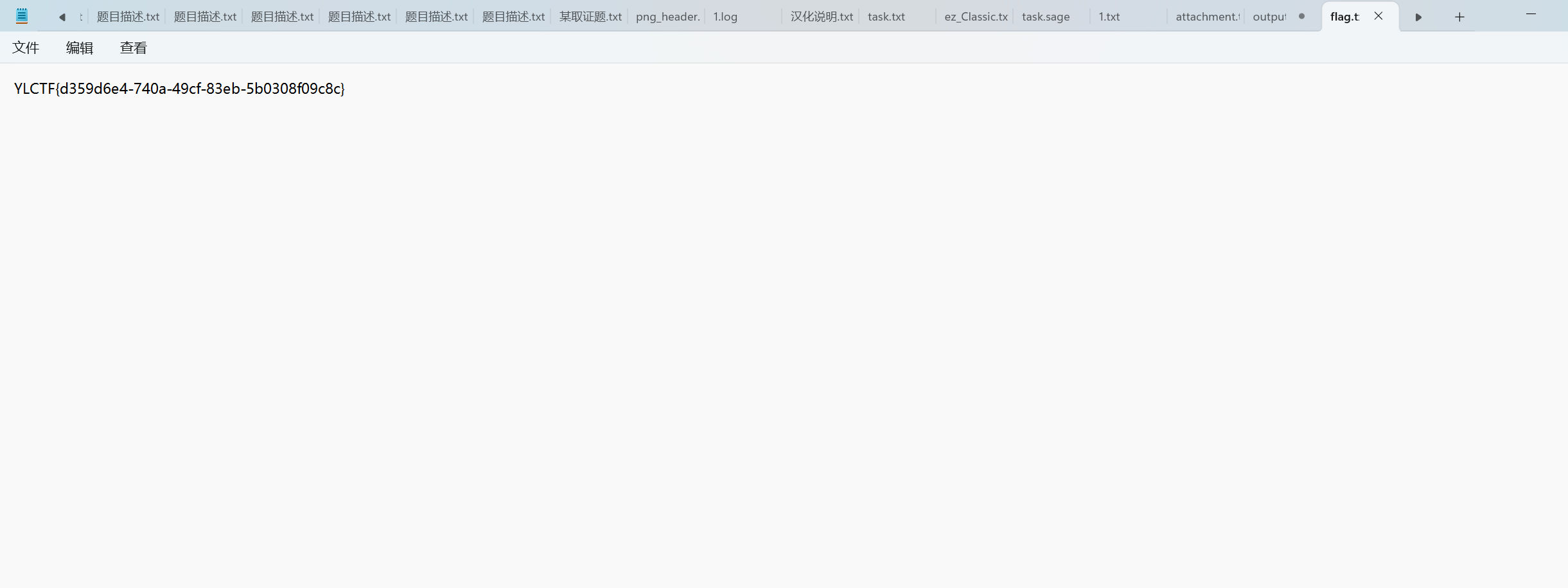
最后flag为YLCTF{d359d6e4-740a-49cf-83eb-5b0308f09c8c}
[Round 1] trafficdet
附件
本题为恶意流量分类识别
因为给的train有一点点太全了,稍微拟合于test,所以采用了99%的acc作为判断,如果用f1的话有点离散了,不太合适。
有很多的算法可以用于流量分类,但是由于数据比较多,选用随机森林算法处理这类问题实际上会比深度学习的方法好很多,所以可以使用sklearn的随机森林库进行建模,然后自己手动筛出掉一些无用特征即可。
如果发现acc可能差的不多,可以调整一下决策树数量,虽然一般来说越多决策树越好,但是对于0.001%~0.01%级别的acc来说,使用越大的决策树可能会导致acc降低。包括随机数seed和训练的时候的分割比例等。
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
# 加载数据
train_df = pd.read_csv("E:\脚本合集\赛题脚本\YLCTF\恶意流量\\train.csv")
test_df = pd.read_csv("E:\脚本合集\赛题脚本\YLCTF\恶意流量\\test.csv")
# 删除不必要的列
train_df.drop('Src Port', axis=1, inplace=True)
test_df.drop('Src Port', axis=1, inplace=True)
# 分离特征和标签
X = train_df.drop('Label', axis=1)
y = train_df['Label']
# 特征缩放
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_test_scaled = scaler.transform(test_df)
# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_scaled, y)
# 预测测试集
y_test_pred = model.predict(X_test_scaled)
# 创建提交文件
submission_df = pd.DataFrame({'id': test_df.index, 'Label': y_test_pred})
submission_df.to_csv('submission.csv', index=False)
|
运行得到的文件上传环境
最后flag为YLCTF{461e6440-9149-4c16-b0dd-57ad6fbae2f0}
[Round 1] whatmusic
下载附件
拿到一个有密码的压缩包,压缩包里面有一个password的文件。
我们拖进010中查看,发现文件的最末尾有PNG%的倒置,考虑可能是byte翻转
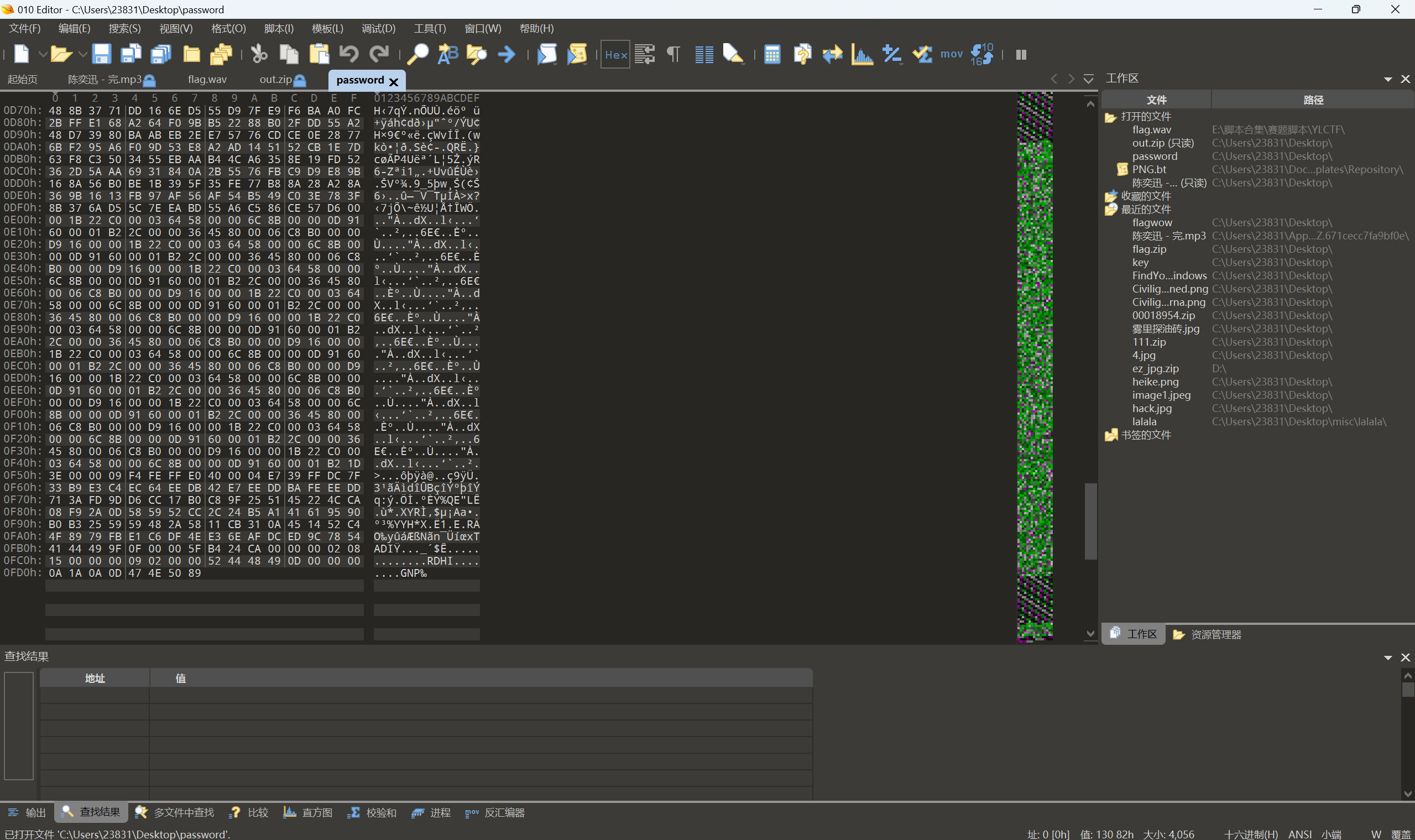
反转脚本
1
2
3
4
5
| with open('E:\\脚本合集\\赛题脚本\\YLCTF\\反转\\password','rb') as f:
with open('E:\\脚本合集\\赛题脚本\\YLCTF\\反转\\flag','wb') as g:
g.write(f.read()[::-1])
|
得到
将flag放进010
保存打开
宽高一把梭得到
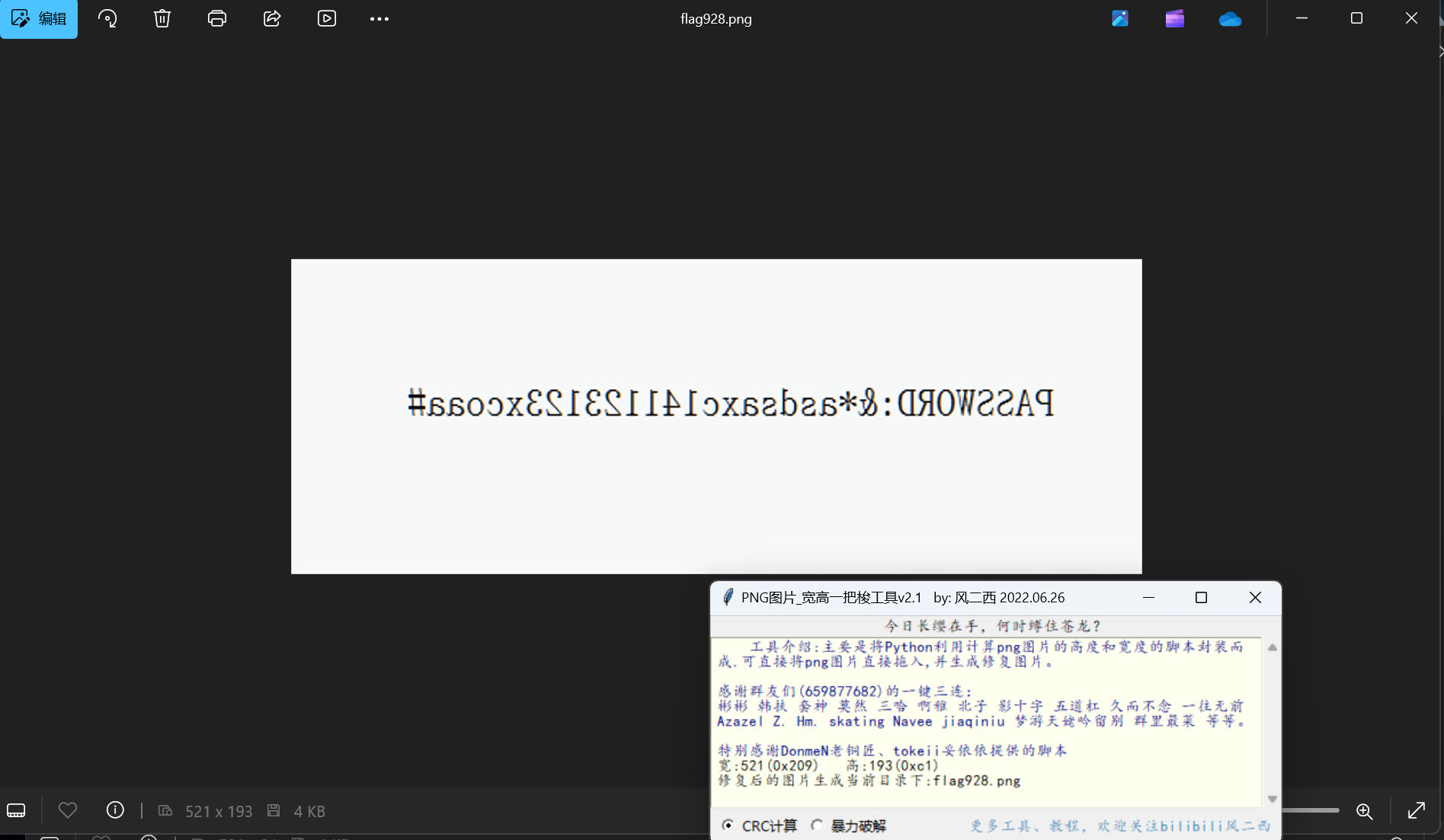
水平翻转
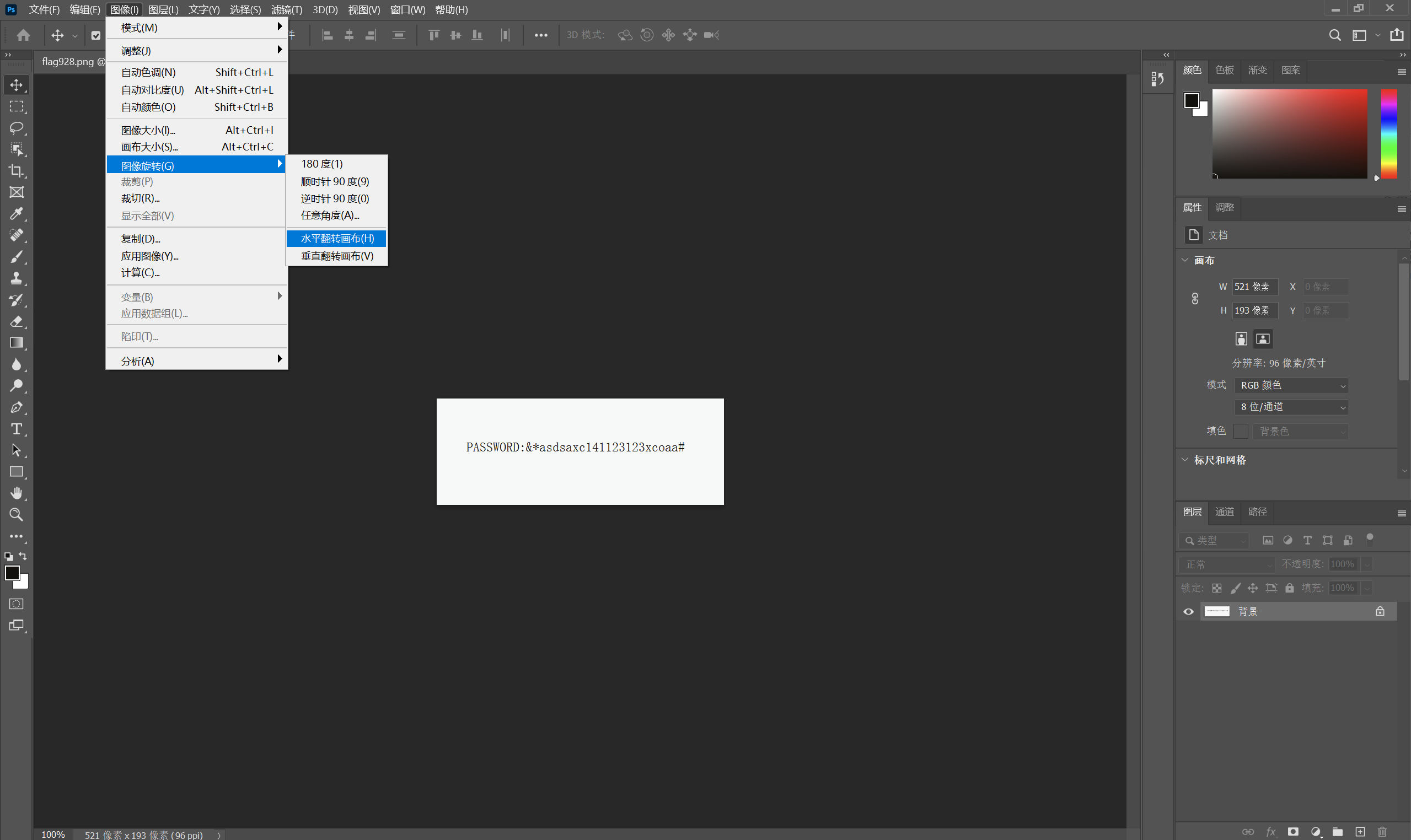
得到压缩包密码:&*asdsaxc141123123xcoaa#
打开压缩包后,还是把flag拖进010中,根据hint1的提示,看到lyra字眼,这是google的一个压缩音频的项目。(https://github.com/google/lyra)
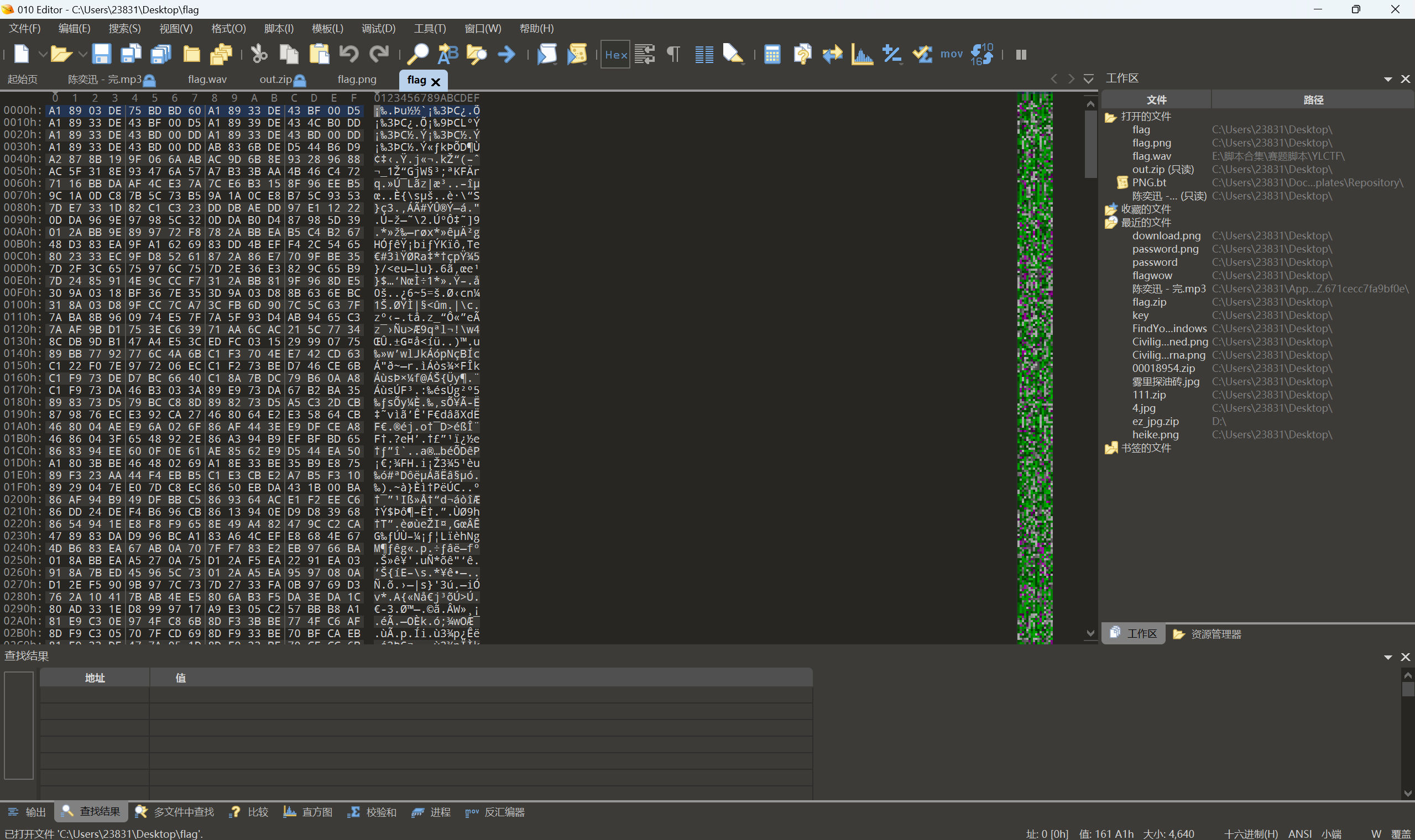
解密
1
| bazel-bin/lyra/cli_example/decoder_main --encoded_path=$HOME/temp/flag.lyra --output_dir=$HOME/temp/
|
得到一段音频后,发现他念了一串东西,而且语速有点快,考虑可以使用语音识别等操作。通过0.25倍速或0.5倍速听可得到YLCTF的flag。
[Round 1] 乌龟子啦
下载附件

base转图片
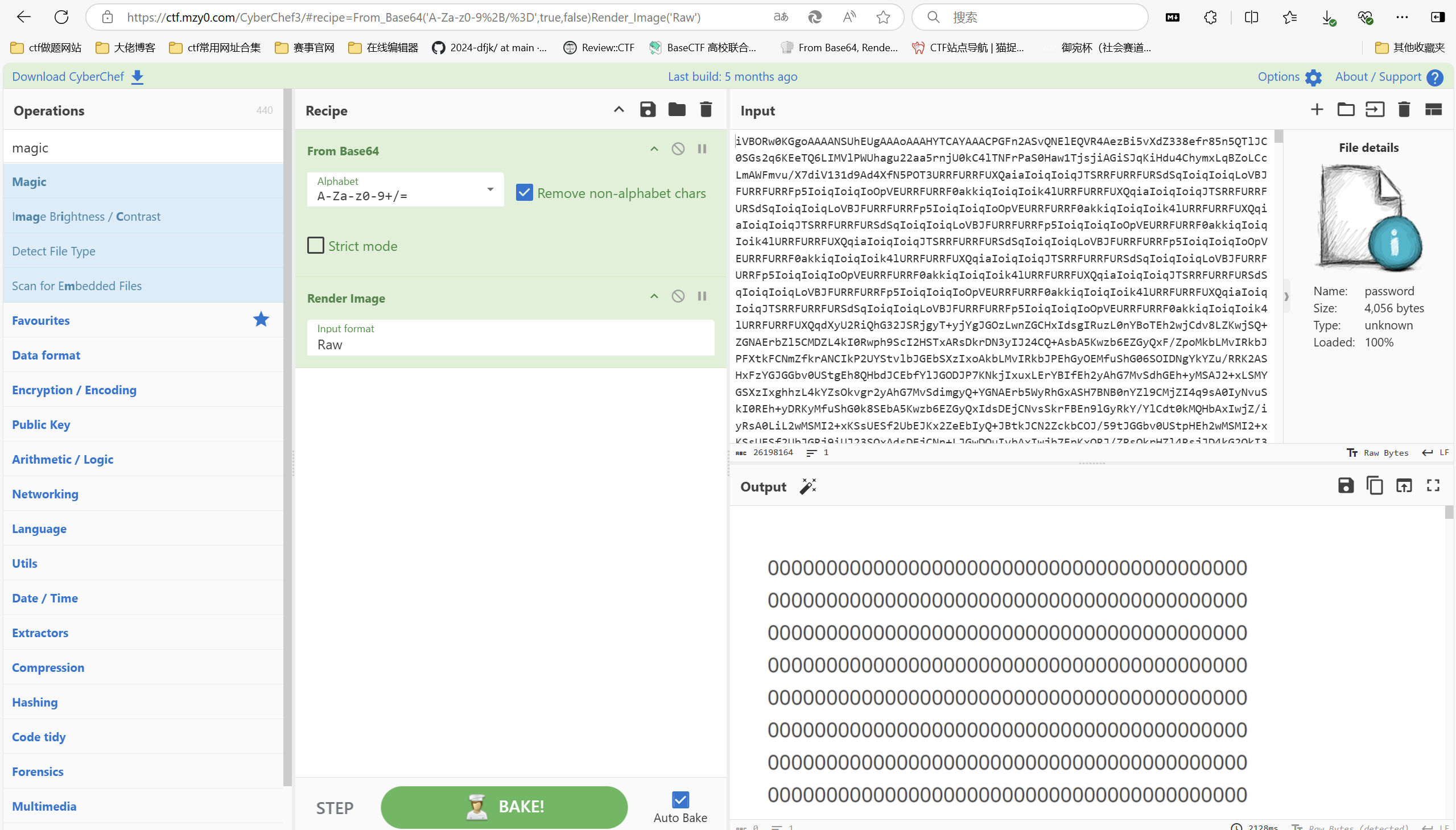
保存图片
在线ocr:图片转文字在线 - 图片文字提取 - 网页OCR文字识别 - 白描网页版 (baimiaoapp.com)
01转二维码

借用大佬图片
扫描二维码
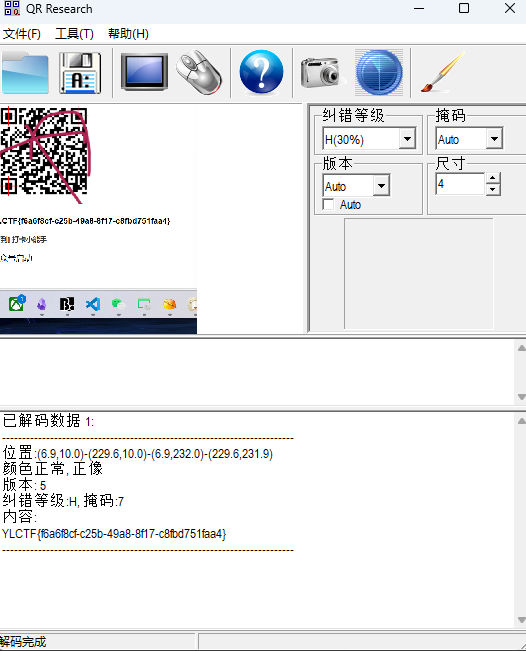
最后flag为YLCTF{f6a6f8cf-c25b-49a8-8f17-c8fbd751faa4}
[Round 1]SinCosTan
下载附件

010查看文件
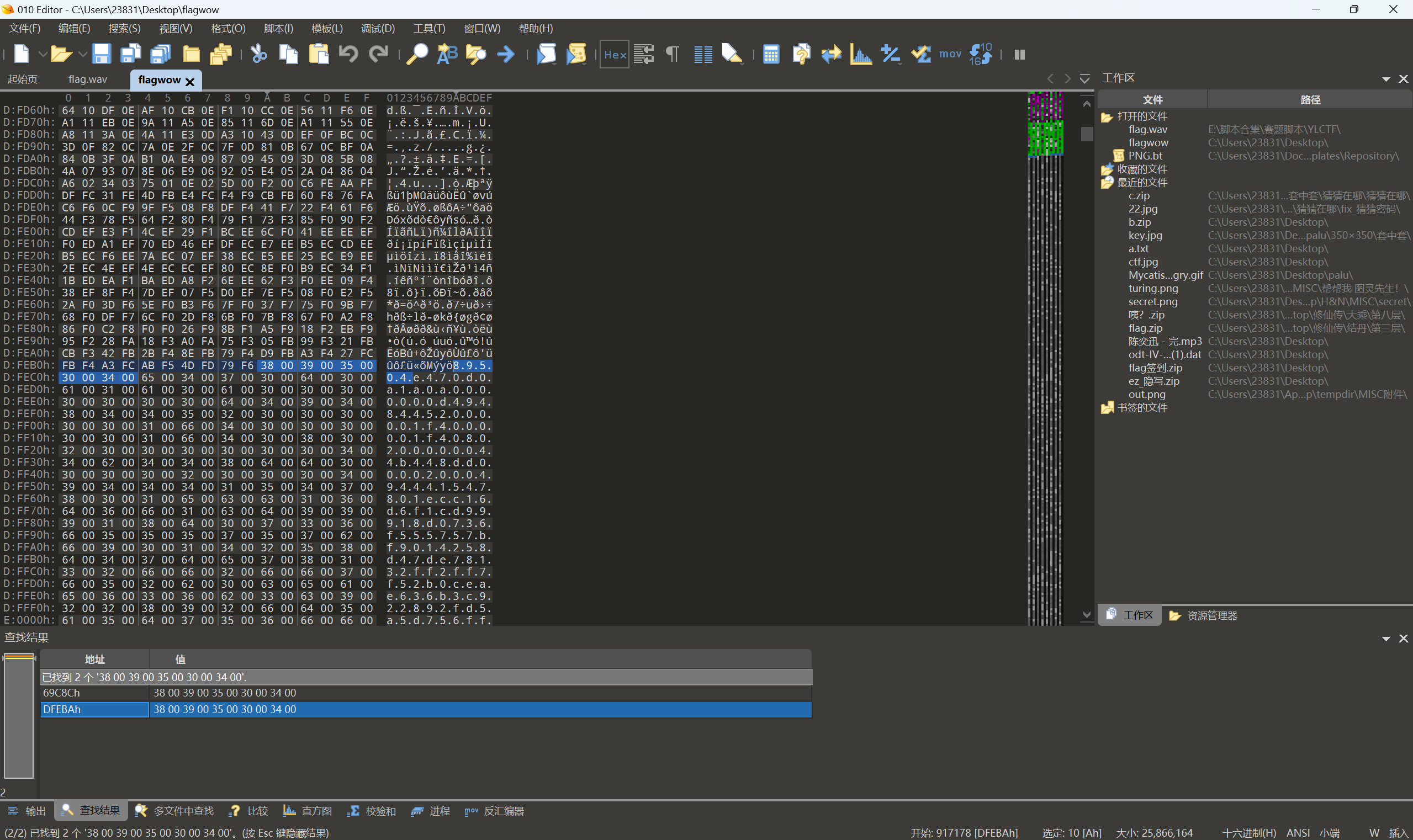
拿到俩个png图片和一个zip文件
zip文件中是一个hint.txt(我们需要修复一下zip文件)
hint内容:
零宽隐写得到seed=114514
双图盲水印seed=114514得到flag
1
| python bwmforpy3.py decode 2.png 1.png flag1.png --seed 114514
|
[Round 2] Trace

下载附件
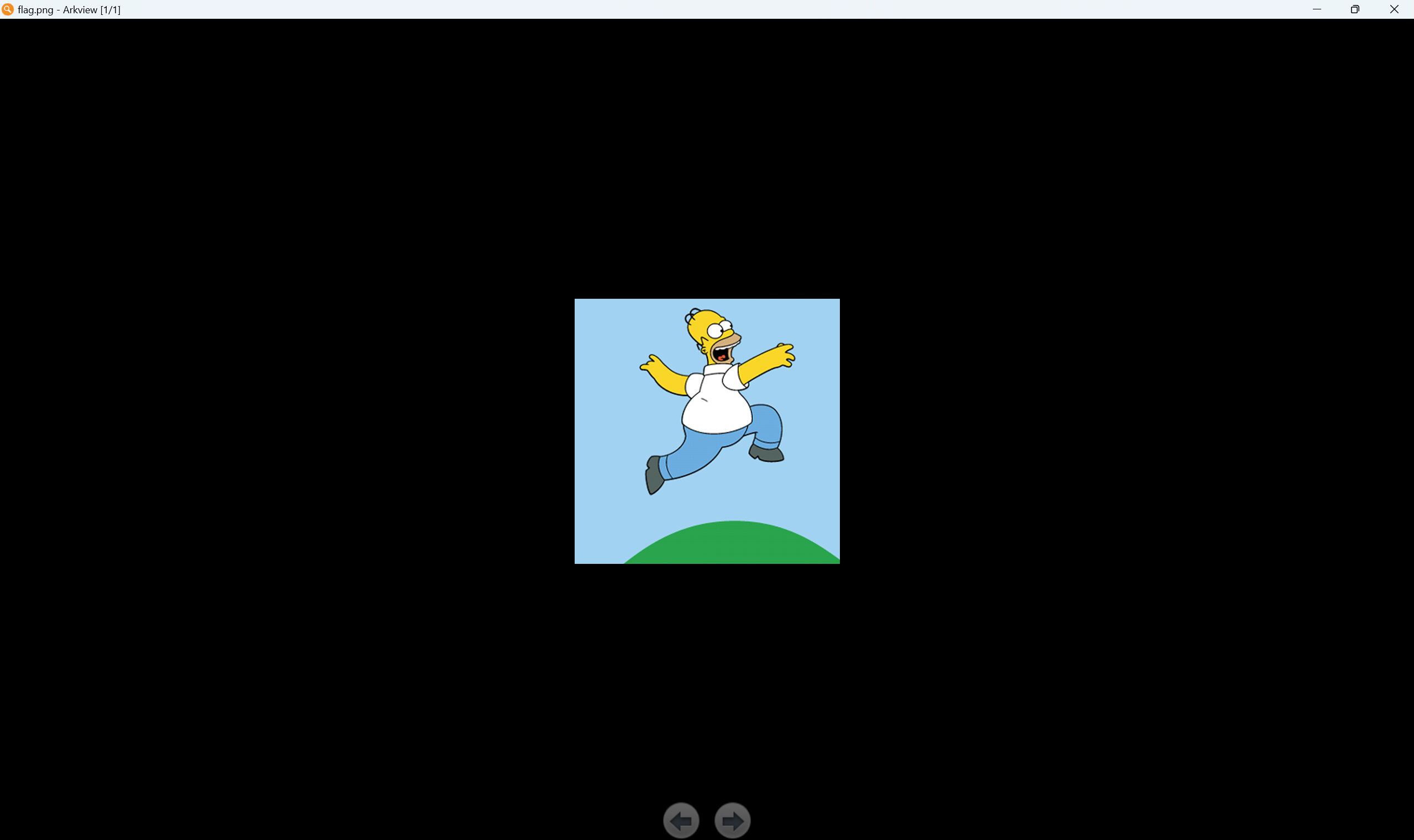
010查看文件
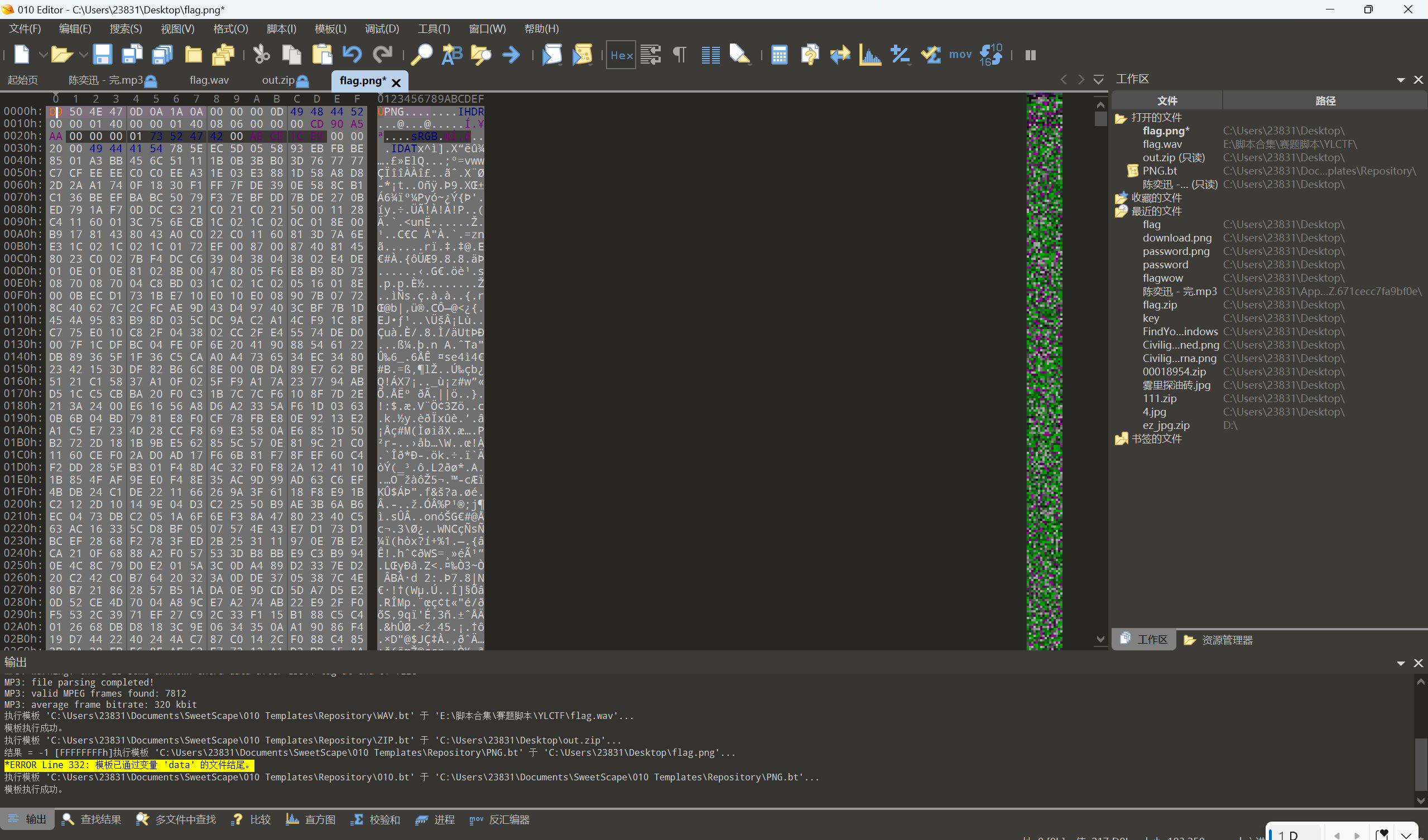
发现base编码,解密
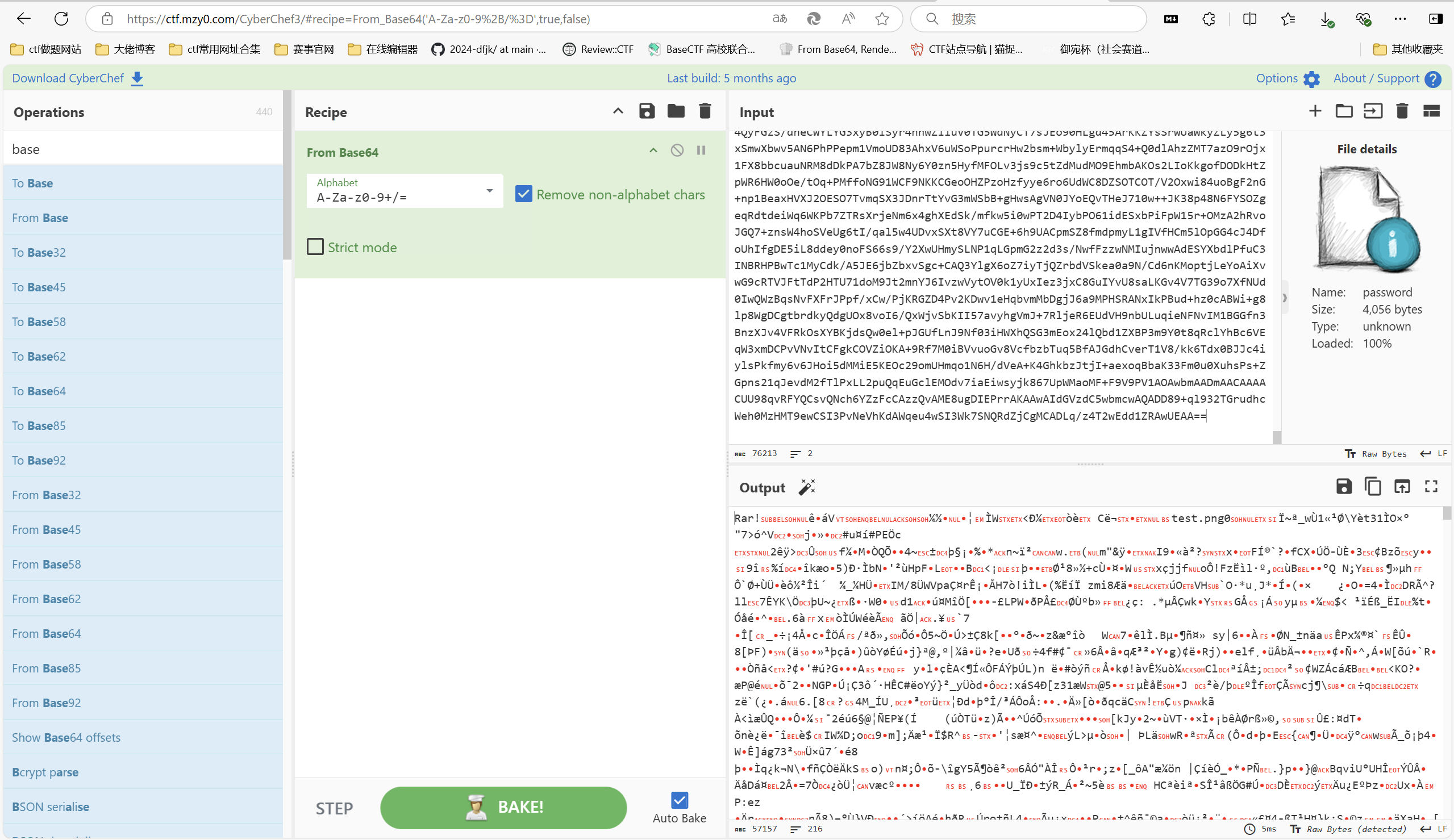
发现是rar文件,保存
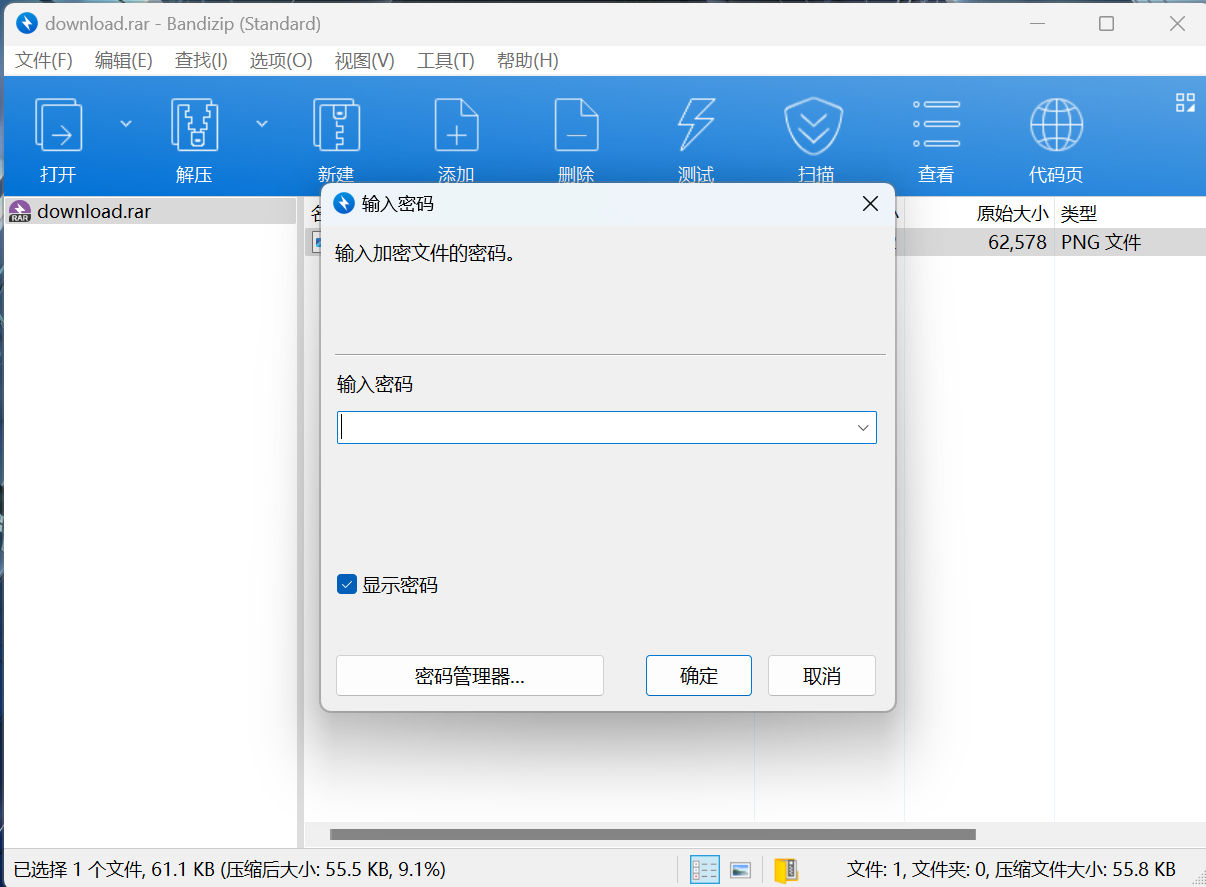
根据提示爆破密码
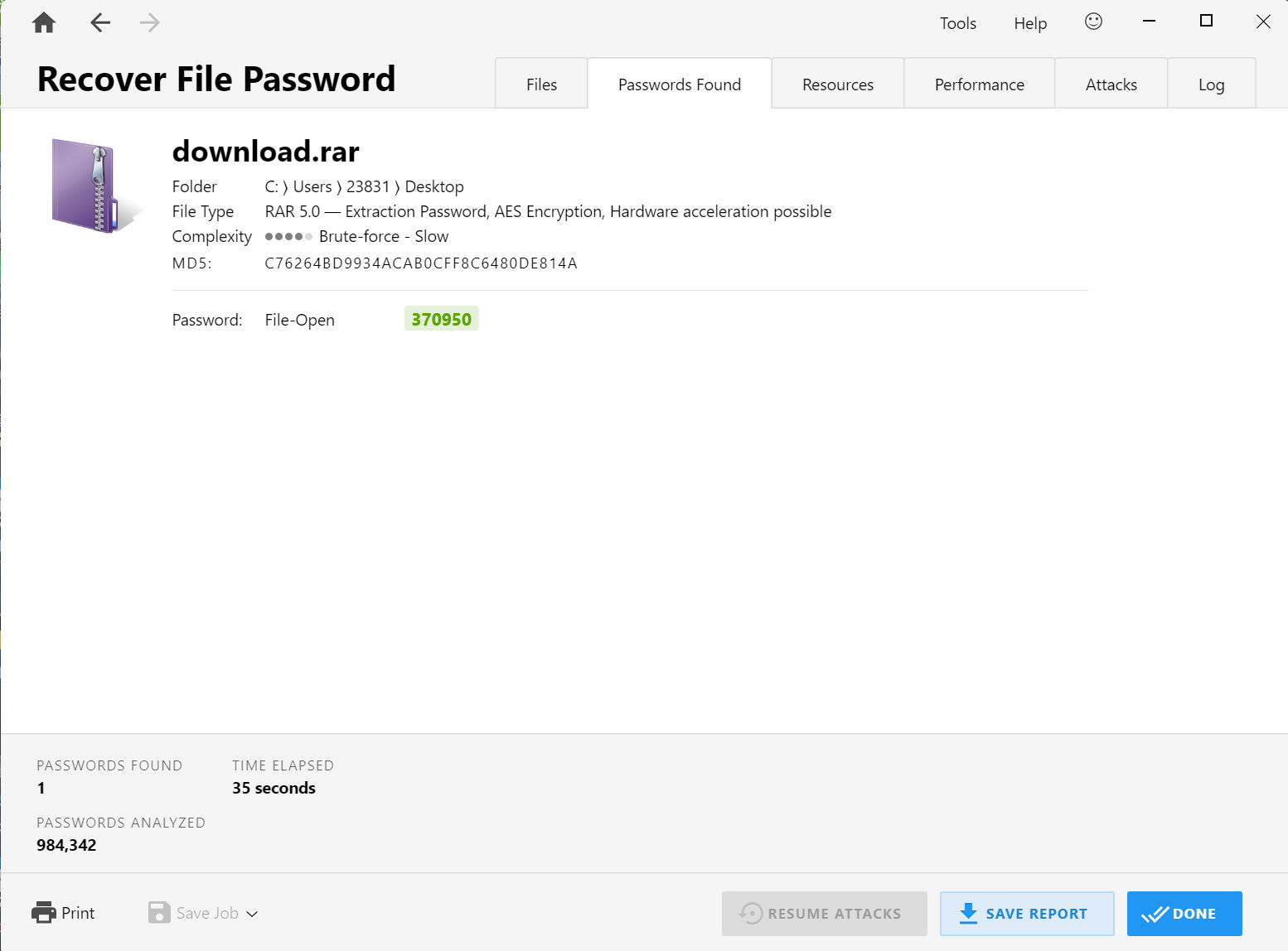
密码为370950,解压压缩包
一眼猫脸变换
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| def arnold_encode(image, shuffle_times=10, a=1, b=1, mode='1'):
image = np.array(image)
arnold_image = np.zeros(shape=image.shape, dtype=image.dtype)
h, w = image.shape[0], image.shape[1]
N = h
for _ in range(shuffle_times):
for ori_x in range(h):
for ori_y in range(w):
new_x = (1*ori_x + b*ori_y)% N
new_y = (a*ori_x + (a*b+1)*ori_y) % N
if mode == '1':
arnold_image[new_x, new_y] = image[ori_x, ori_y]
else:
arnold_image[new_x, new_y, :] = image[ori_x, ori_y, :]
return Image.fromarray(arnold_image)
import numpy as np
from PIL import Image
def arnold_decode(image, shuffle_times=10, a=1, b=1, mode='1'):
image = np.array(image)
decode_image = np.zeros(shape=image.shape, dtype=image.dtype)
h, w = image.shape[0], image.shape[1]
N = h
for _ in range(shuffle_times):
for ori_x in range(h):
for ori_y in range(w):
new_x = ((a*b+1)*ori_x + (-b)* ori_y)% N
new_y = ((-a)*ori_x + ori_y) % N
if mode == '1':
decode_image[new_x, new_y] = image[ori_x, ori_y]
else:
decode_image[new_x, new_y, :] = image[ori_x, ori_y, :]
return Image.fromarray(decode_image)
img = Image.open('E:\\脚本合集\\赛题脚本\\YLCTF\\猫脸变换\\test.png')
decode_img = arnold_decode(img)
decode_img.save('E:\\脚本合集\\赛题脚本\\YLCTF\\猫脸变换\\flag-output.png')
|
运行得到
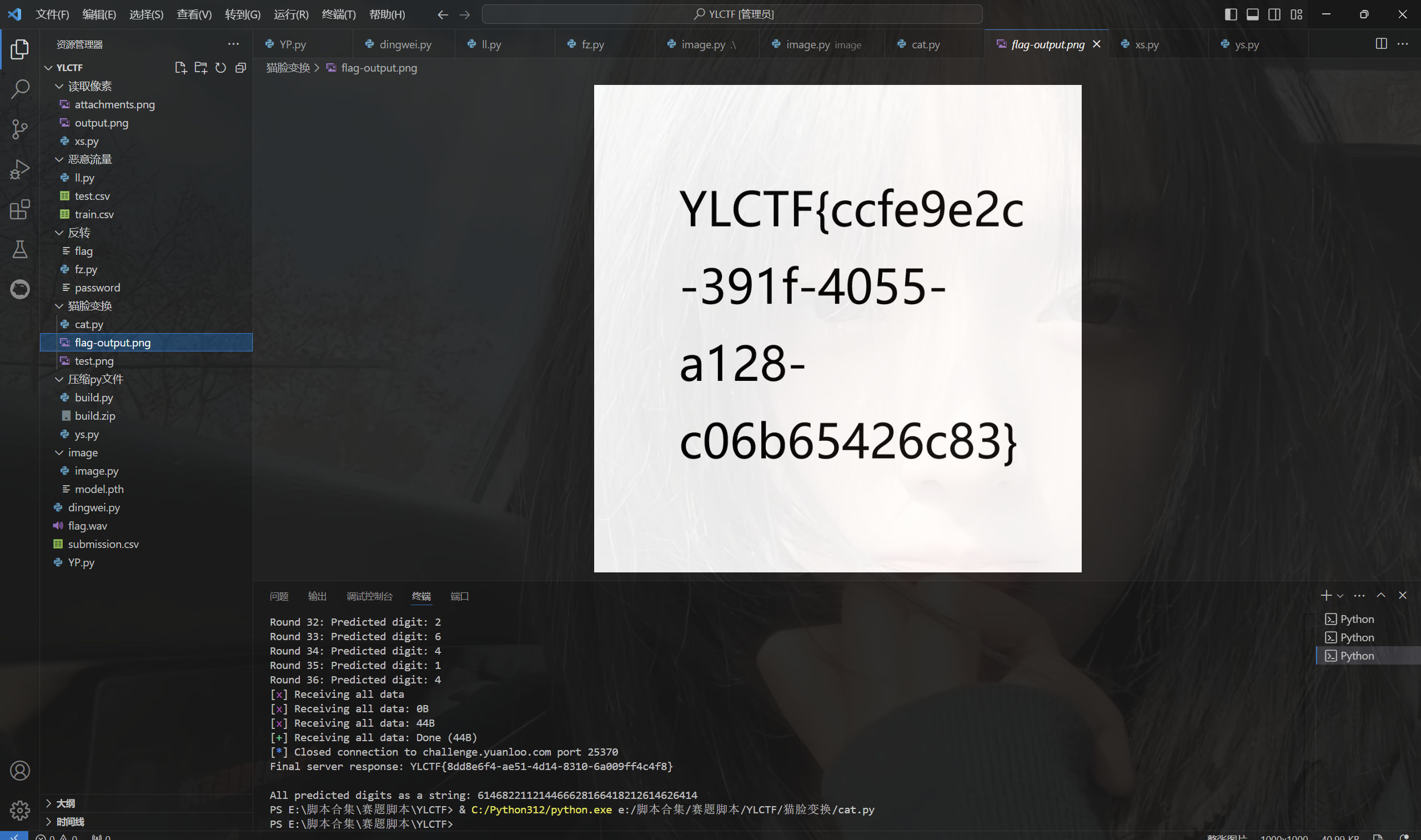
最后flag为YLCTF{ccfe9e2c-391f-4055-a128-c06b65426c83}
[Round 2] IMGAI
下载附件
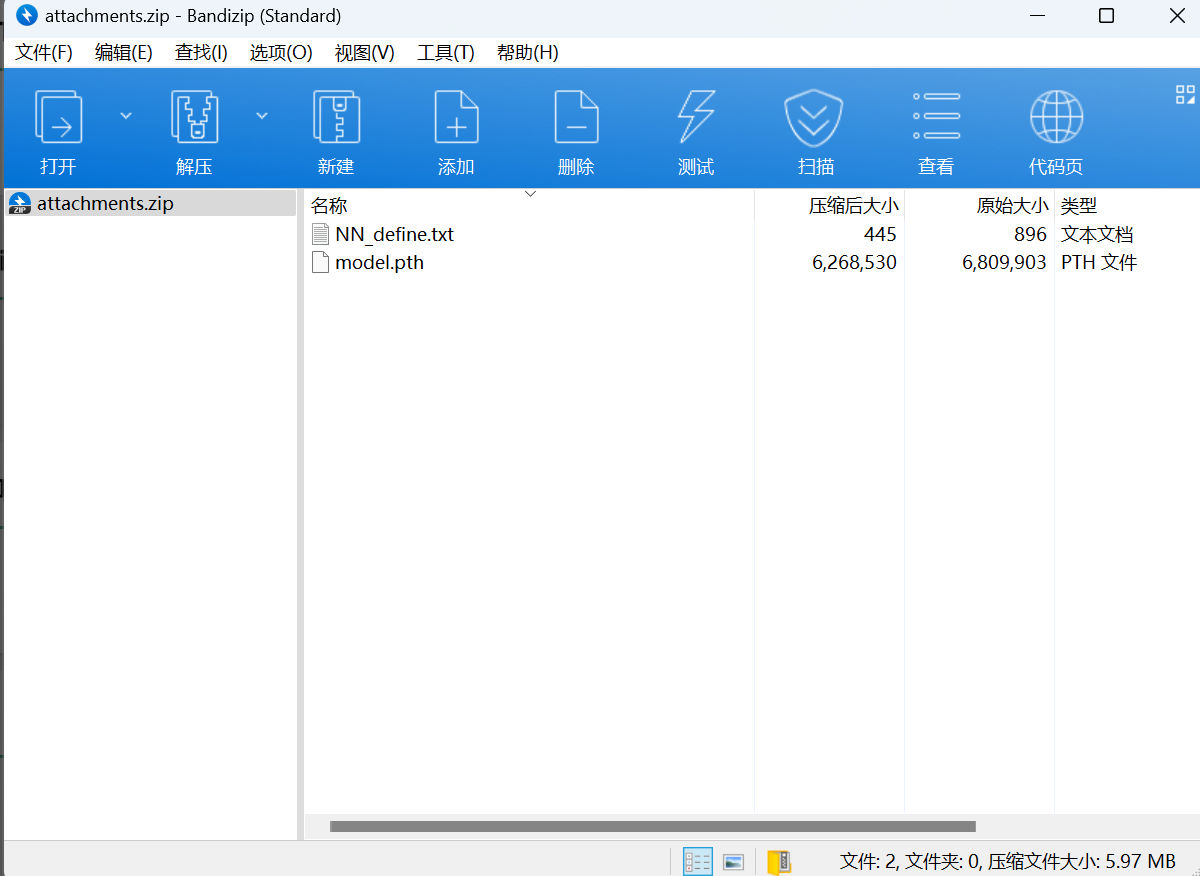
按照这个替换表来实现数据替换。
远程服务端实现了一个图片输出的功能,将36张640x480的图片输出成2进制。
所以需要通过pwntools的recv来读取二进制信息,再通过PIL将二进制信息转换成图片,再将图片进行预测,最后使用pwntools的sendline与终端进行交互。
给出了一个CNN定义,需要将这个定义写入test脚本中,后面直接利用model.pth进行预测就行了。
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
| from pwn import *
import torch
import torch.nn as nn
from torchvision import transforms
from PIL import Image
import numpy as np
import re
class MNISTCNN(nn.Module):
def __init__(self):
super(MNISTCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=5, padding=2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=5)
self.fc1 = nn.Linear(64 * 5 * 5, 1024)
self.fc2 = nn.Linear(1024, 10)
self.pool = nn.MaxPool2d(2, 2)
self.relu = nn.ReLU()
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = x.view(-1, 64 * 5 * 5)
x = self.relu(self.fc1(x))
return self.fc2(x)
def load_model(model_path):
model = MNISTCNN()
model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))
model.eval()
return model
def preprocess_image(binary_data):
image_array = np.array([int(pixel) for pixel in binary_data]).reshape(480, 640)
image = Image.fromarray(np.uint8(image_array * 255), mode='L')
transform = transforms.Compose([
transforms.Resize((28, 28)),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
return transform(image).unsqueeze(0)
def predict_digit(model, image):
with torch.no_grad():
output = model(image)
return torch.max(output, 1)[1].item()
def main():
try:
p = remote("challenge.yuanloo.com", 39732)
model = load_model('E:\\脚本合集\\赛题脚本\\YLCTF\\image\\model.pth')
predictions = []
for i in range(36):
try:
data = p.recvuntil(f"input num {i + 1} \n".encode(), timeout=3)
binary_data = re.findall(r"[01]+", data.decode())
if not binary_data:
print(f"No binary data found in round {i + 1}. Exiting...")
break
image = preprocess_image(binary_data[0].strip())
predicted = predict_digit(model, image)
predictions.append(predicted)
p.sendline(str(predicted).encode())
print(f"Round {i + 1}: Predicted digit: {predicted}")
except EOFError:
print(f"Connection closed unexpectedly in round {i + 1}")
break
except Exception as e:
print(f"Error in round {i + 1}: {str(e)}")
break
final_data = p.recvall(timeout=5)
print("Final server response:", final_data.decode())
predicted_string = ''.join(map(str, predictions))
print("All predicted digits as a string:", predicted_string)
except Exception as e:
print(f"An error occurred: {str(e)}")
finally:
if 'p' in locals():
p.close()
if __name__ == "__main__":
main()
|
运行得到
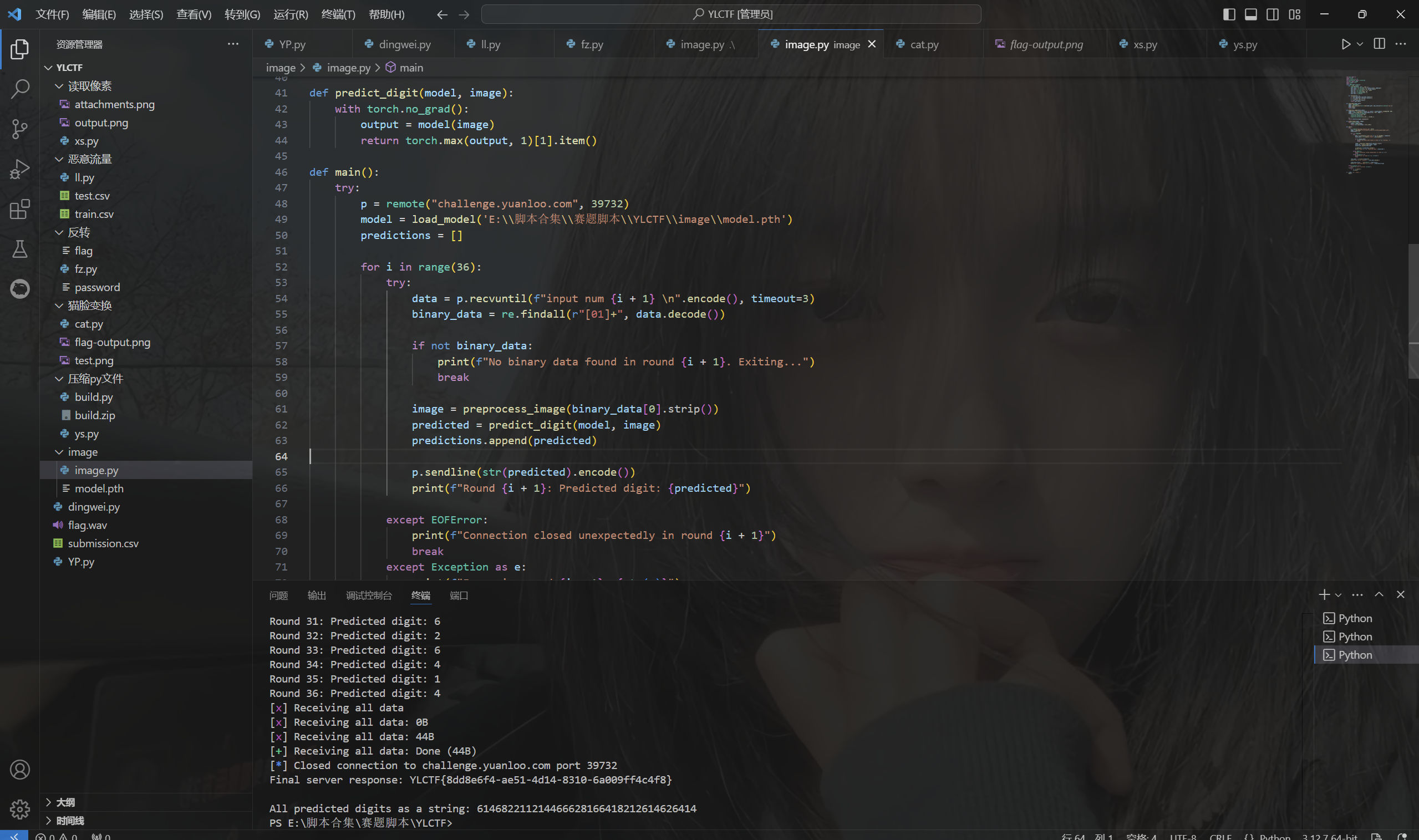
最后flag为YLCTF{8dd8e6f4-ae51-4d14-8310-6a009ff4c4f8}
[Round 2] LiteOS
不会
[Round 2] 听~
下载附件
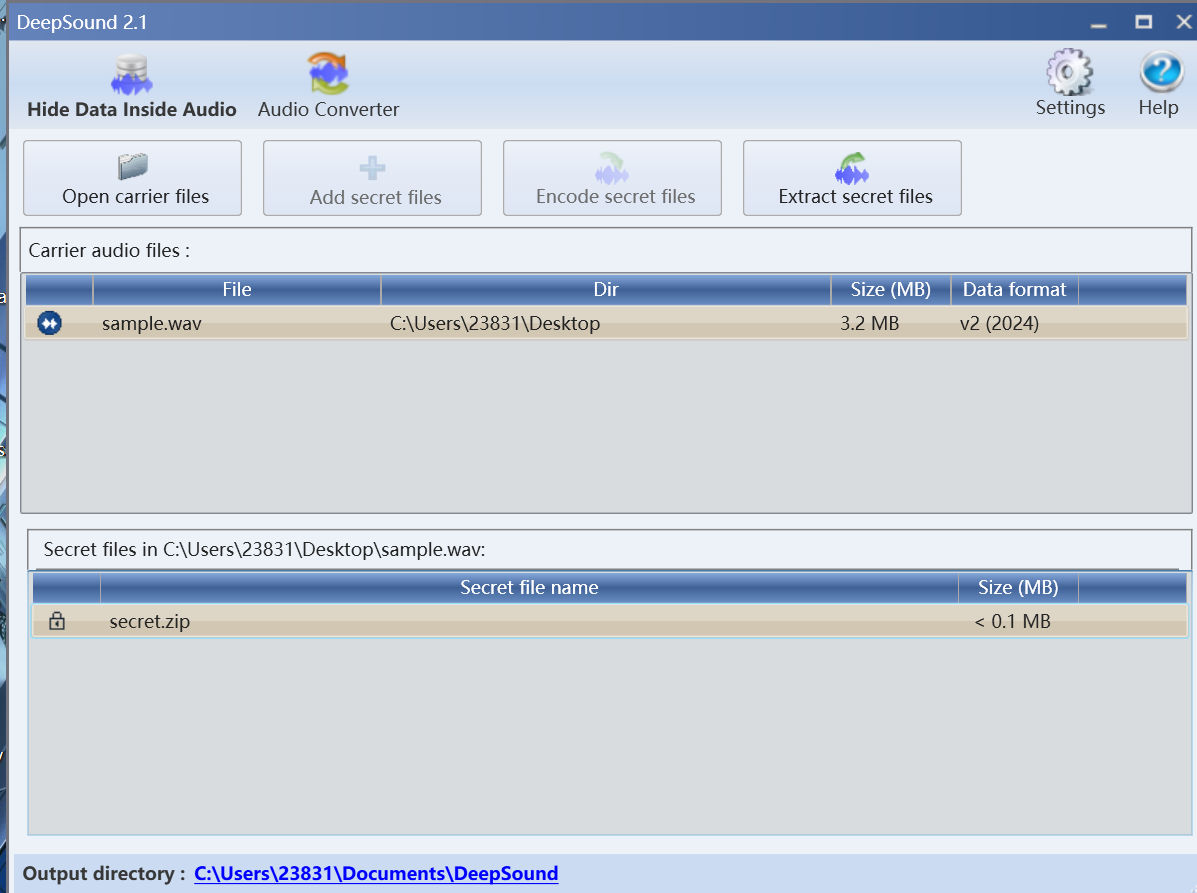
放进deepsond
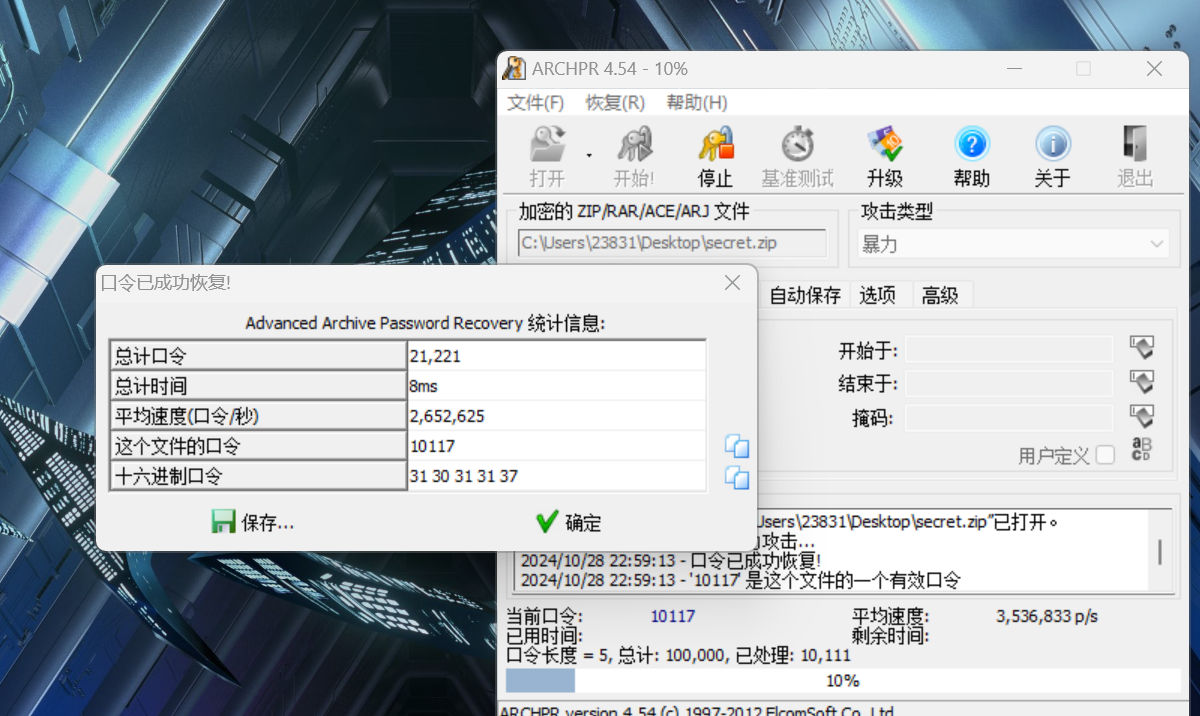
该压缩包存在加密,通过爆破得到压缩包口令
解压压缩包得到
stegsolve
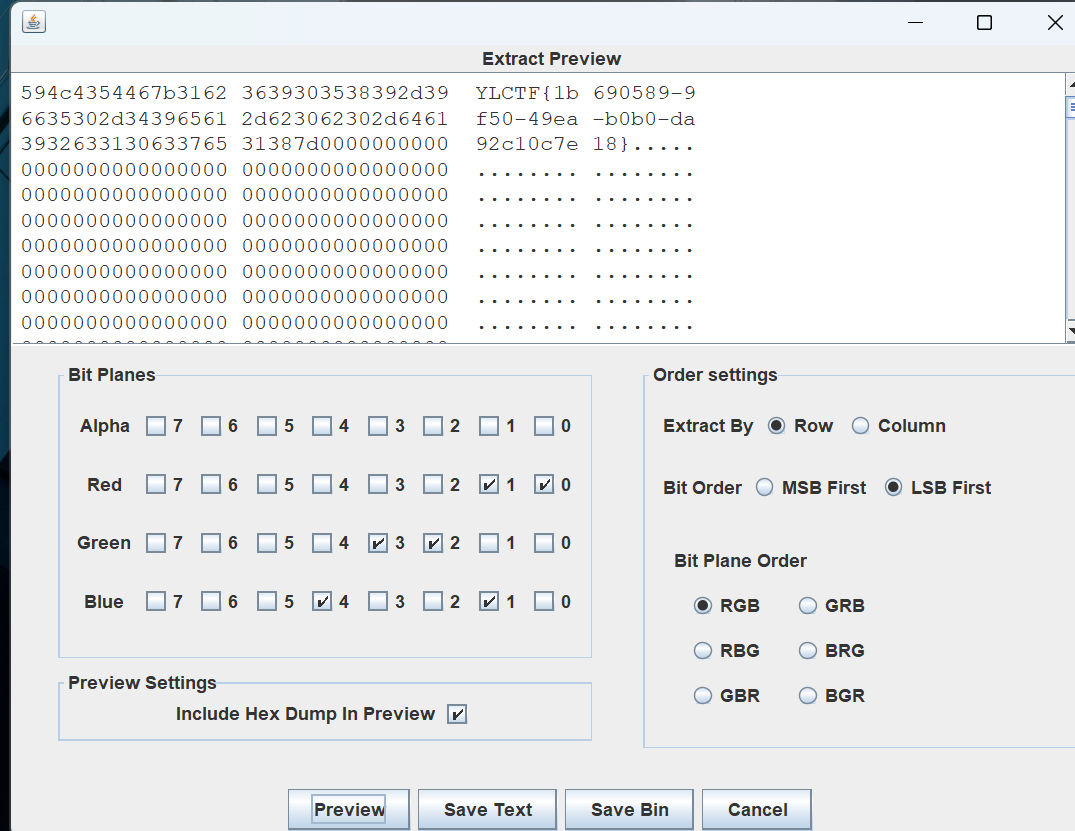
最后flag为YLCTF{1b690589-9f50-49ea-b0b0-da92c10c7e18}
[Round 2] 滴答滴
下载附件

010查看文件
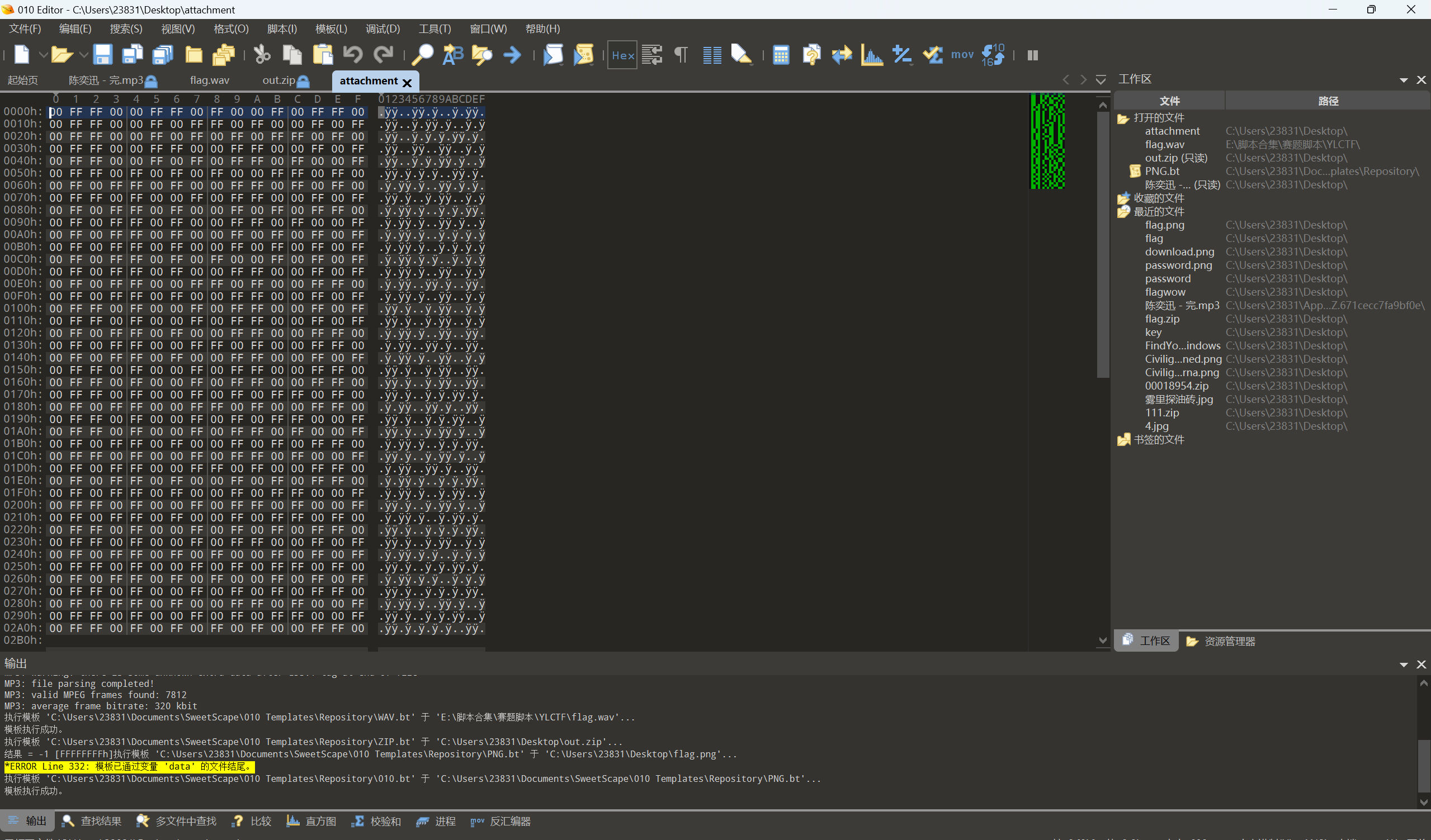
使用010打开文件可以发现全部都是 00 和 FF,一般来说这是可以用于表示电平信号
题目描述给了 man~,考虑曼彻斯特编码
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| def read_from_file(filename):
# 从文件中读取二进制数据
with open(filename, 'rb') as file:
return file.read()
def manchester_to_binary(manchester_data):
# 将曼切斯特编码的数据转换回二进制字符串
binary_str = ''
i = 0
while i < len(manchester_data):
if manchester_data[i] == 0 and manchester_data[i+1] ==255:
binary_str += '0'
elif manchester_data[i] == 255 and manchester_data[i+1] == 0:
binary_str += '1'
i += 2 # 每次处理两个字节
return binary_str
def binary_to_char(binary_str):
# 将二进制字符串转换回ASCII字符
return ''.join([chr(int(binary_str[i:i+8], 2)) for i in range(0, len(binary_str), 8)])
# 示例使用
filename = "E:\\脚本合集\\赛题脚本\\YLCTF\\曼彻斯特\\attachment" # 输入文件名
manchester_data = read_from_file(filename)
binary_str = manchester_to_binary(manchester_data)
print(binary_str)
ascii_str = binary_to_char(binary_str)
print(f"解码后的ASCII字符串: {ascii_str}")
|
运行得到

最后flag为YLCTF{7d160084-4dd5-4eec-bf1f-12f3ad8c8a6b}
[Round 3] Blackdoor

下载附件
d盾查杀
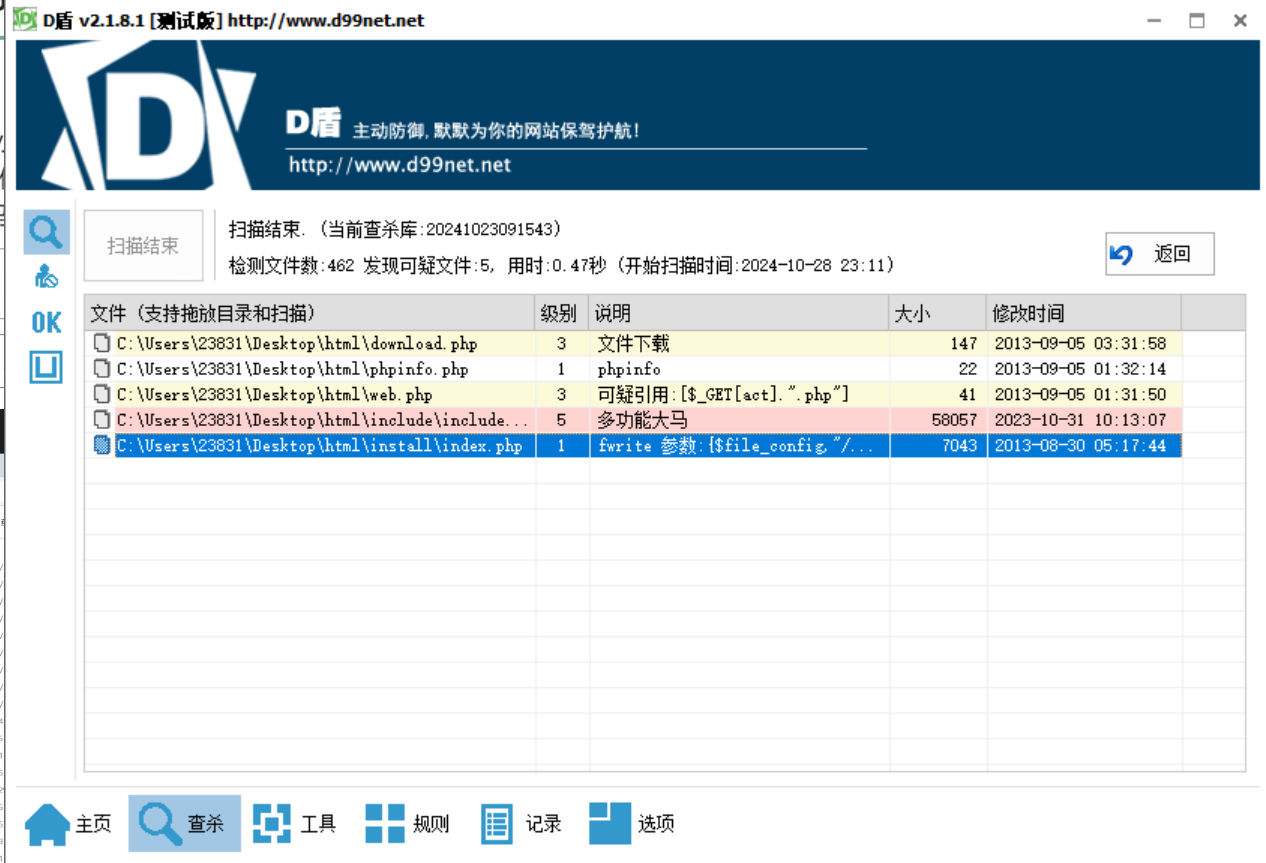
查看可疑木马搜索pass字符串

最后flag为YLCTF{e2bae51b981c707eb28302fe22d60340}
[Round 3] CheckImg

下载附件

仔细查看发现 Red plane 0 通道有明显隐写

Green plane 0给了提示,注意细节

先把 Red plane 0 通道的数据给提取出来
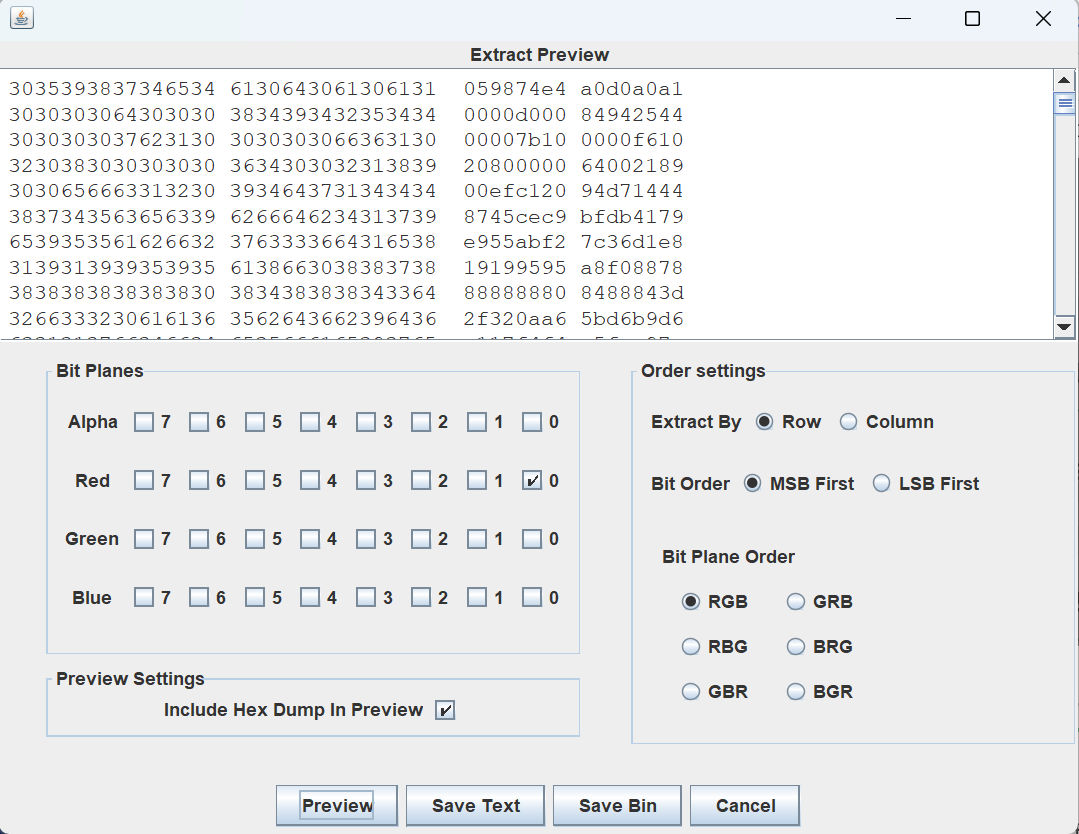
检查隐写的数据,发现是以俩位俩位的转
010导入十六进制后保存,加上.png使用b神工具反转
zsteg一把梭
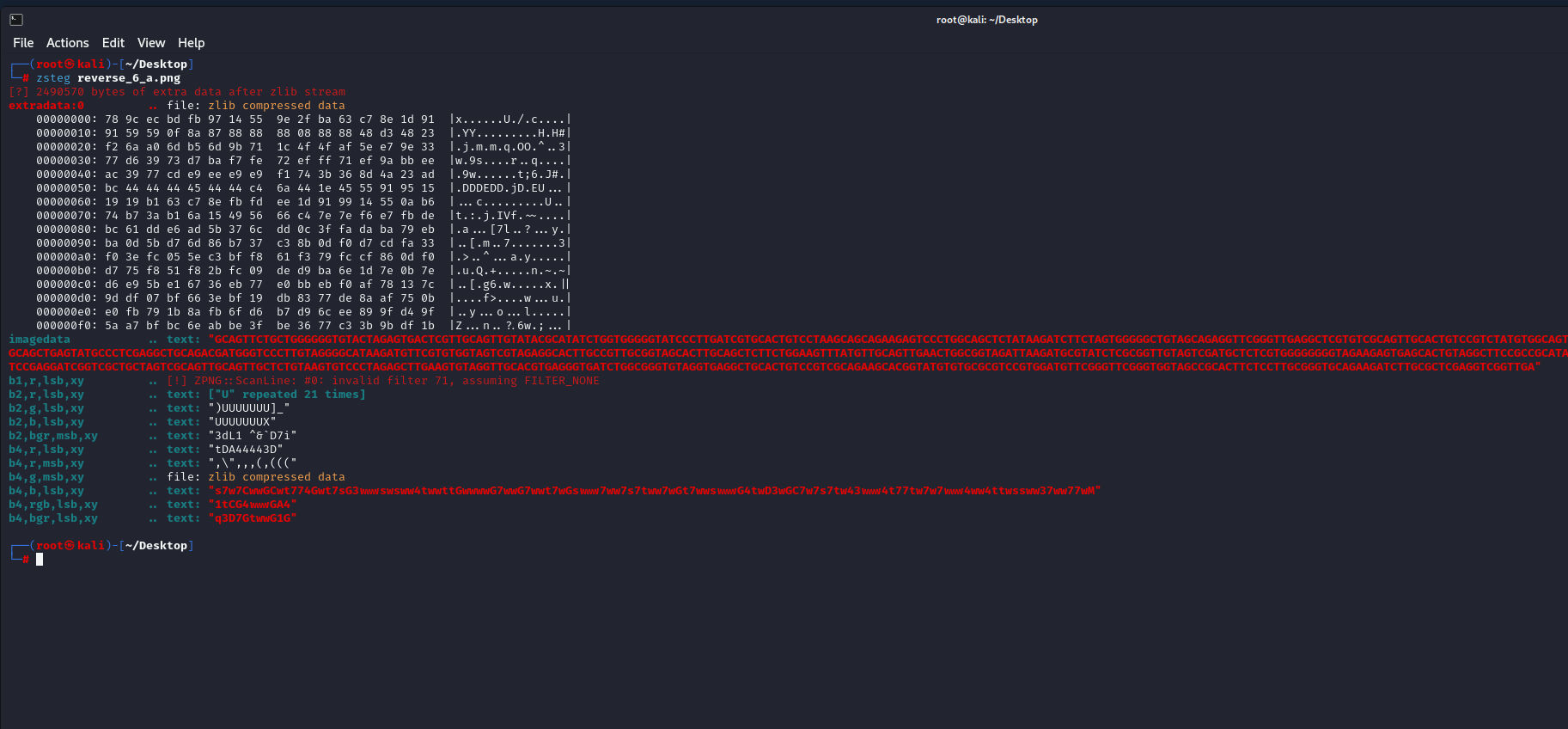
DNA编码
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| import sys
bin_dna = {'00':'A','10':'C','01':'G','11':'T'}
mapping = {
'AAA':'a','AAC':'b','AAG':'c','AAT':'d','ACA':'e','ACC':'f', 'ACG':'g','ACT':'h','AGA':'i','AGC':'j','AGG':'k','AGT':'l','ATA':'m','ATC':'n','ATG':'o','ATT':'p','CAA':'q','CAC':'r','CAG':'s','CAT':'t','CCA':'u','CCC':'v','CCG':'w','CCT':'x','CGA':'y','CGC':'z','CGG':'A','CGT':'B','CTA':'C','CTC':'D','CTG':'E','CTT':'F','GAA':'G','GAC':'H','GAG':'I','GAT':'J','GCA':'K','GCC':'L','GCG':'M','GCT':'N','GGA':'O','GGC':'P','GGG':'Q','GGT':'R','GTA':'S','GTC':'T','GTG':'U','GTT':'V','TAA':'W','TAC':'X','TAG':'Y','TAT':'Z','TCA':'1','TCC':'2','TCG':'3','TCT':'4','TGA':'5','TGC':'6','TGG':'7','TGT':'8','TTA':'9','TTC':'0','TTG':' ','TTT':'.'}
def bin_2_code(string):
string = string.replace(" ","")
string = string.replace("\n","")
final=""
for j in range(0,len(string),2):
final+=bin_dna[string[j:j+2]]
return final
def decode_dna(string):
final=""
for i in range(0,len(string),3):
final+=mapping[string[i:i+3]]
return final
print(decode_dna("GCAGTTCTGCTGGGGGGTGTACTAGAGTGACTCGTTGCAGTTGTATACGCATATCTGGTGGGGGTATCCCTTGATCGTGCACTGTCCTAAGCAGCAGAAGAGTCCCTGGCAGCTCTATAAGATCTTCTAGTGGGGGCTGTAGCAGAGGTTCGGGTTGAGGCTCGTGTCGCAGTTGCACTGTCCGTCTATGTGGCAGTTGACGTGTAAGGTTATTAAGAAGGTGAGGTTGTAGTTGTAGCTGATTATGATCTTGAGGGGGCAGCTGAGTATGCCCTCGAGGCTGCAGACGATGGGTCCCTTGTAGGGGCATAAGATGTTCGTGTGGTAGTCGTAGAGGCACTTGCCGTTGCGGTAGCACTTGCAGCTCTTCTGGAAGTTTATGTTGCAGTTGAACTGGCGGTAGATTAAGATGCGTATCTCGCGGTTGTAGTCGATGCTCTCGTGGGGGGGGTAGAAGAGTGAGCACTGTAGGCTTCCGCCGCATAGTCCCTCCTGGTCGCATAAGCATGACTGCTGGGGGTCGTACTAGAAGATCTCCTTGCGGTGTCCGAGGATCGGTCGCTGCTAGTCGCAGTTGCAGTTGCTCTGTAAGTGTCCCTAGAGCTTGAAGTGTAGGTTGCACGTGAGGGTGATCTGGCGGGTGTAGGTGAGGCTGCACTGTCCGTCGCAGAAGCACGGTATGTGTGCGCGTCCGTGGATGTTCGGGTTCGGGTGGTAGCCGCACTTCTCCTTGCGGGTGCAGAAGATCTTGCGCTCGAGGTCGGTTGA"))
|
运行得到
1
| KVEEQRSCI5DVKVSXKZEUQS2FJBKE2WKKGI2EKNCWJFCUQNSKIVAVINBTKVKE2TZUKVHUWRZWGRIVSVSNJZJFIQKNIZLDINKHJQ2FSQKWJVBUSTSIKFLVMSKFKNFEGVZVKVGEMSJWJMZDMVSTJNDUQQSGI5KEYN2LKY2DETKWK5EEQTSCGJDFMU2IJA3ECTKVKVNEWU2CIFGUYVKBIRJEMRSRINKE2TKGKAZU6M2UJVAVAUSLKFDFMRKGJFMDITR5
|
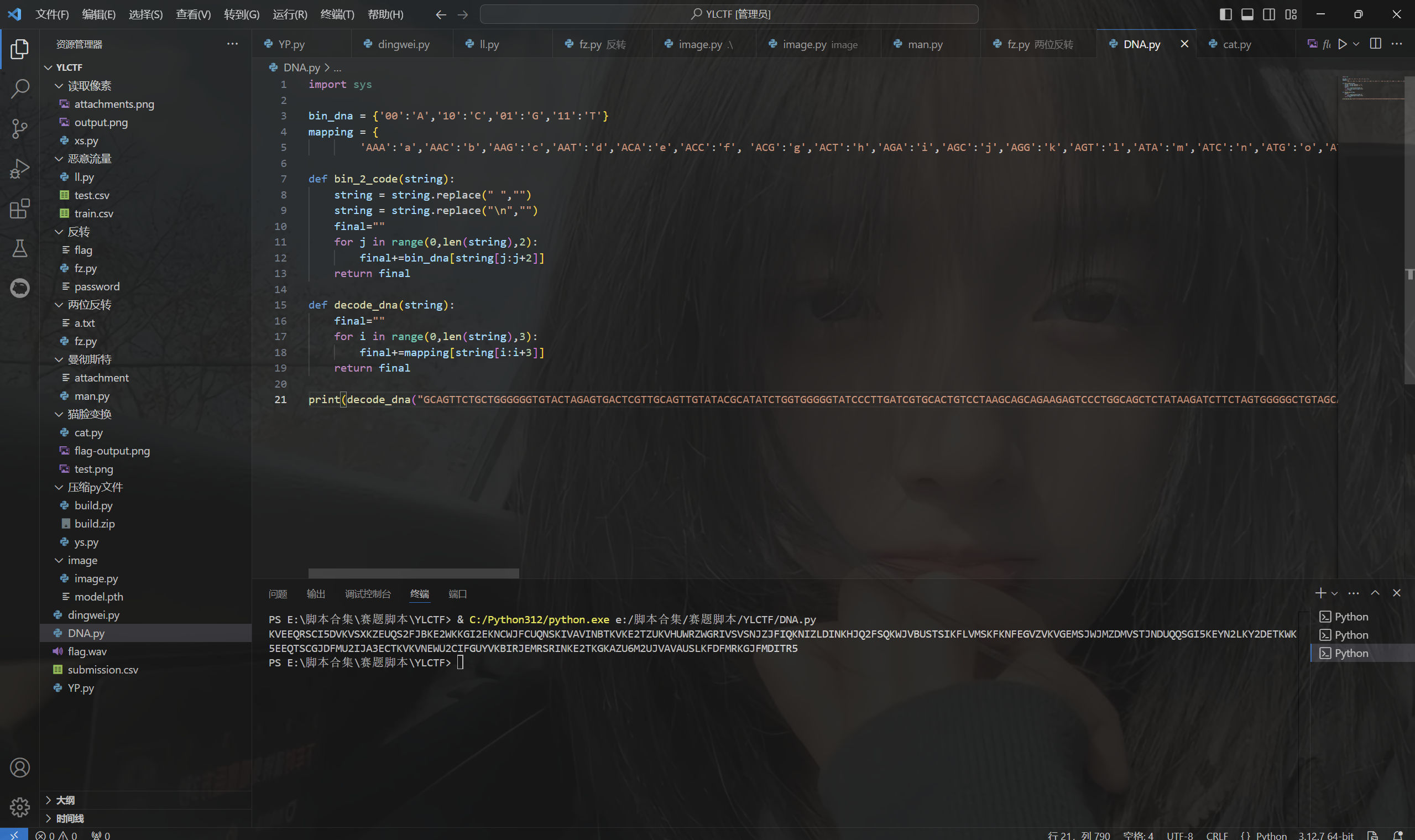
base32解码
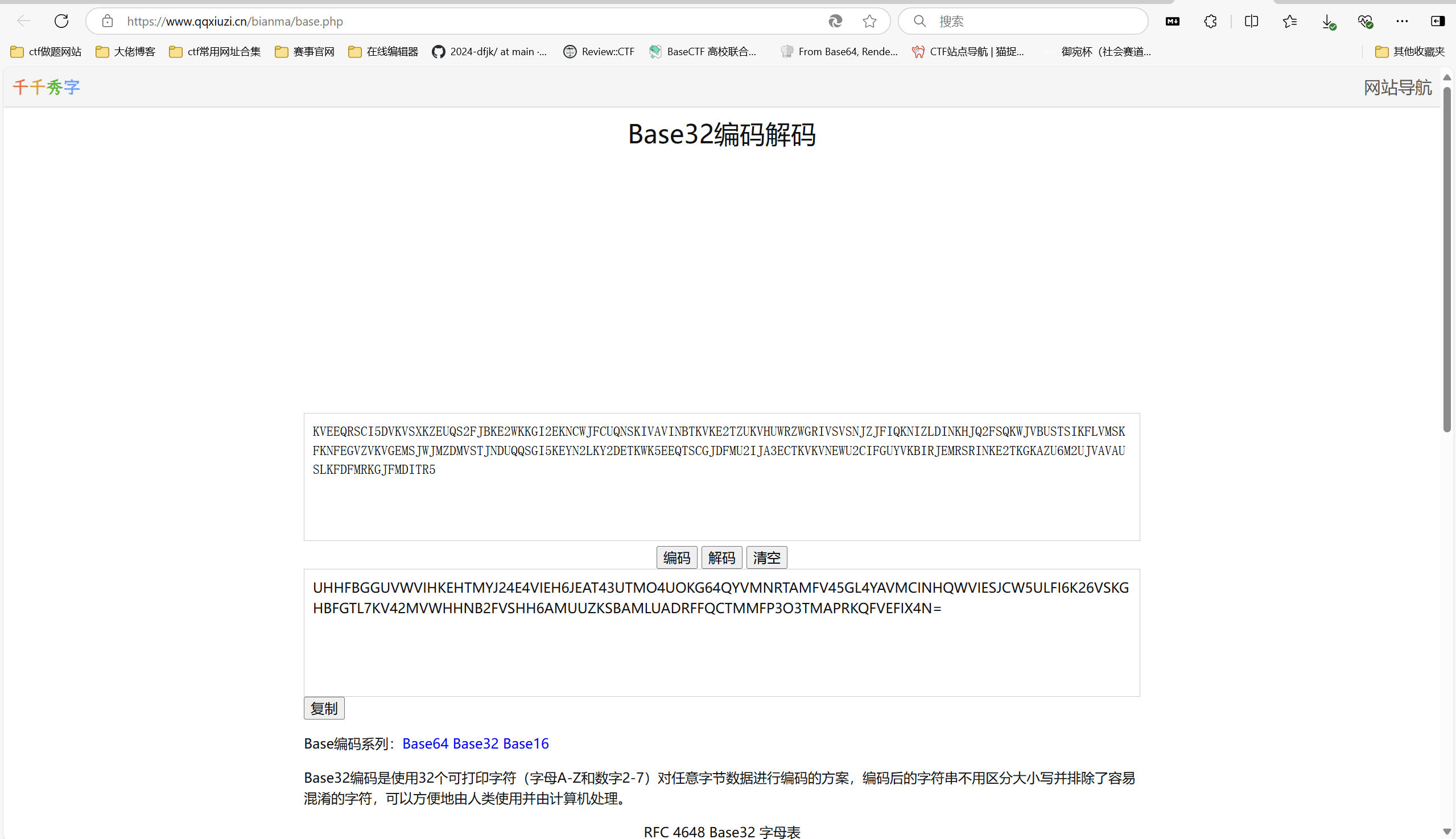
ciphey一把梭

最后flag为YLCTF{beaHfLVG-LfTL-ZTfa-TVHL-cATRdeTfHReT}
[Round 3] Tinted
下载附件
利用取色器
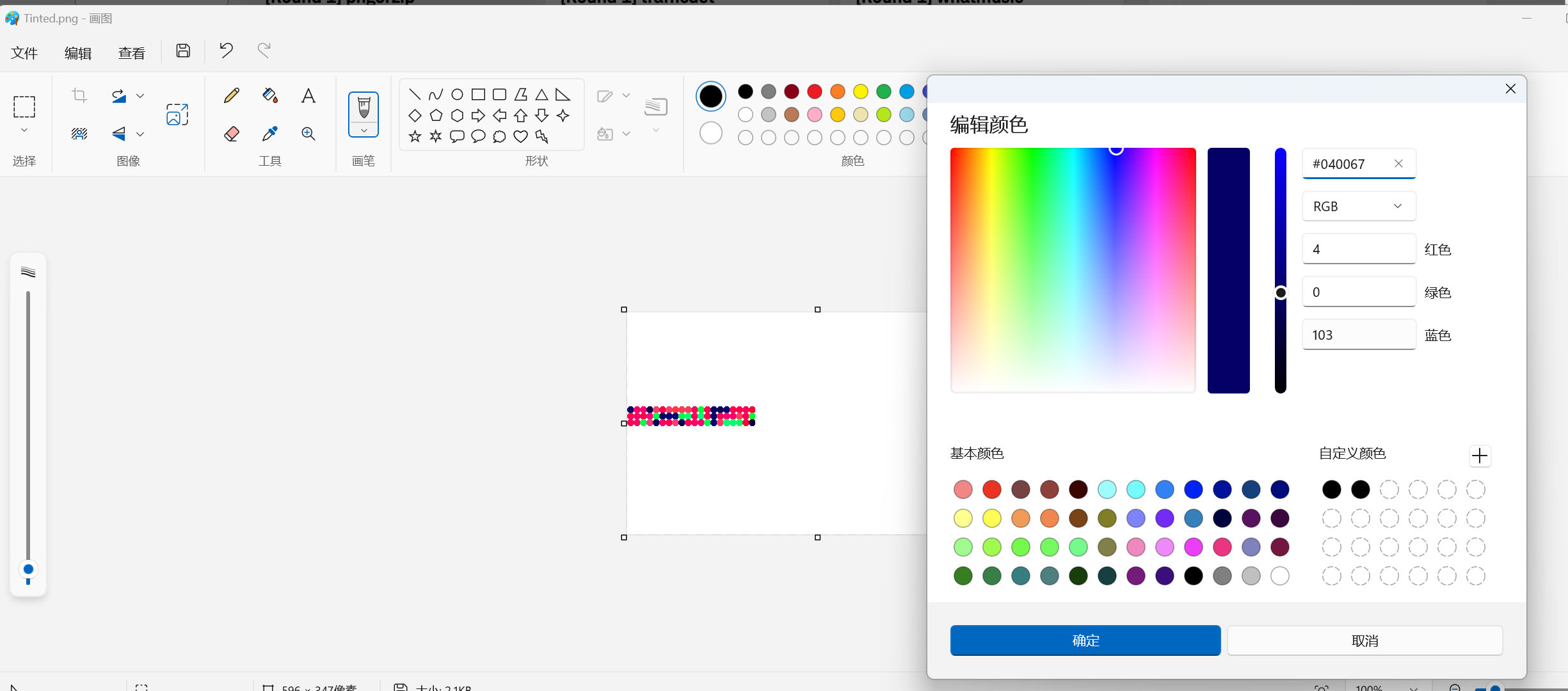
提取结果
1
| #040067,#ff0065,#ff0072,#040049,#ff3c66,#ff004a,#ff3c6a,#ff3c42,#ff3c52,#ff3c5a,#ff0066,#00ff31,#ff0052,#040067,#040062,#040074,#ff0052,#ff004c,#ff0052,#ff0039,#ff0054,#ff0064,#ff004a,#ff0075,#00ff52,#040063,#040075,#040075,#00ff53,#00ff74,#ff0057,#00ff75,#ff0051,#040067,#ff004a,#ff0074,#ff0069,#ff3c5a,#ff0057,#00ff39,#ff0054,#ff0067,#00ff4a,#ff3c7a,#040054,#ff0064,#ff0052,#ff3c76,#040054,#ff004c,#ff0069,#ff0075,#00ff52,#040074,#ff3c62,#00ff71,#00ff70,#00ff62,#ff0035,#040035
|
根据上述的颜色代码进行分析,发现在最后两位存在问题,可以通过16进制转换,编写脚本进行提取,代码如下:
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| import binascii
a = ['#040067', '#ff0065', '#ff0072', '#040049', '#ff3c66', '#ff004a', '#ff3c6a', '#ff3c42', '#ff3c52', '#ff3c5a',
'#ff0066', '#00ff31', '#ff0052', '#040067', '#040062', '#040074', '#ff0052', '#ff004c', '#ff0052', '#ff0039',
'#ff0054', '#ff0064', '#ff004a', '#ff0075', '#00ff52', '#040063', '#040075', '#040075', '#00ff53', '#00ff74',
'#ff0057', '#00ff75', '#ff0051', '#040067', '#ff004a', '#ff0074', '#ff0069', '#ff3c5a', '#ff0057', '#00ff39',
'#ff0054', '#ff0067', '#00ff4a', '#ff3c7a', '#040054', '#ff0064', '#ff0052', '#ff3c76', '#040054', '#ff004c',
'#ff0069', '#ff0075', '#00ff52', '#040074', '#ff3c62', '#00ff71', '#00ff70', '#00ff62', '#ff0035', '#040035']
res = ''
for i in a:
# print(i, i[5:])
res += i[5:]
print(binascii.unhexlify(res))
|
运行得到
判断以上为某一种编码类型,经过fuzz测试可以得到为 base64 换表且为 CyberChef 的默认表。
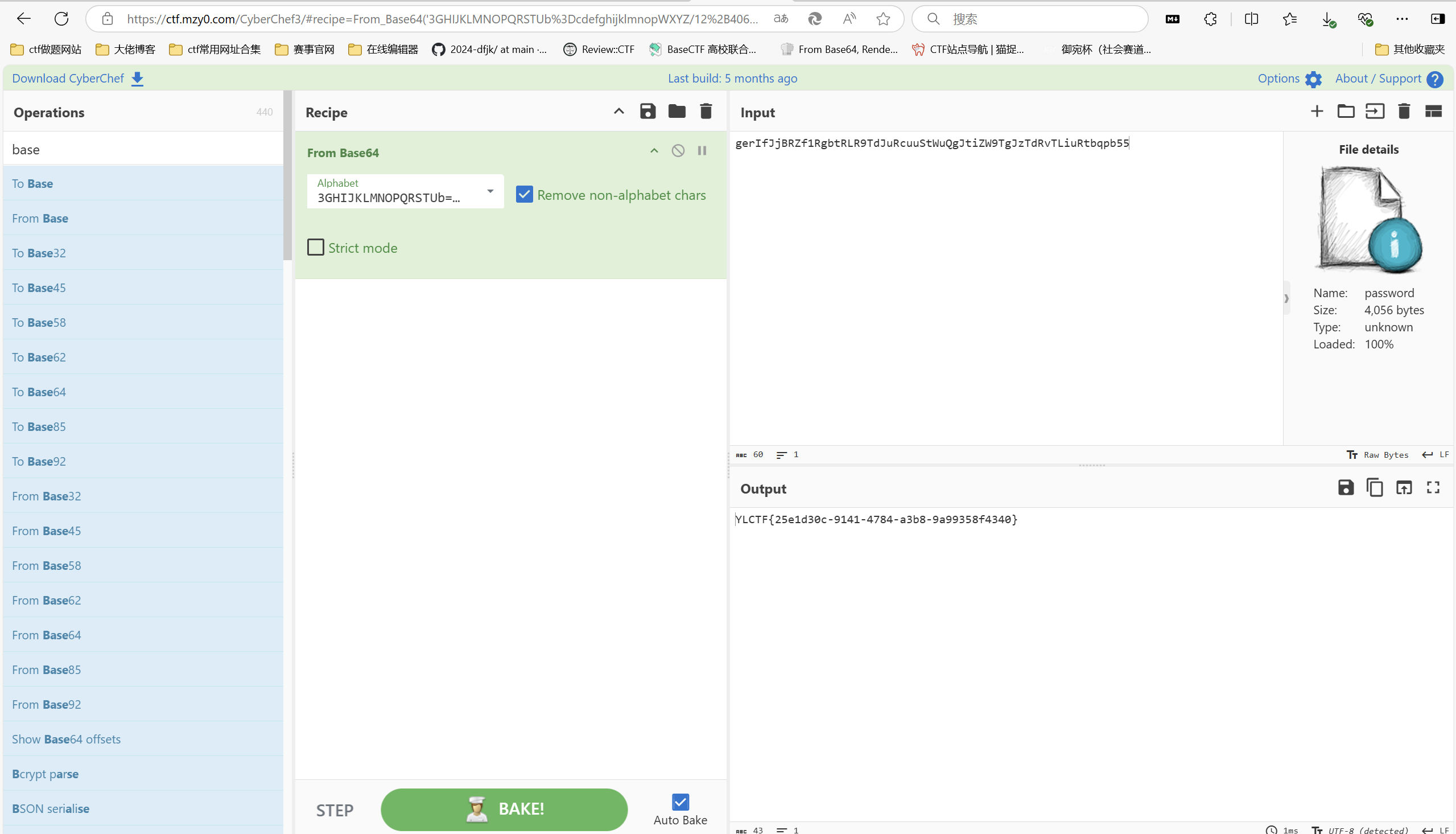
最后flag为YLCTF{25e1d30c-9141-4784-a3b8-9a99358f4340}

下载附件
010查看文件
观察最后面的数据,发现存在类似于 png 文件头的格式,对该数据进行反转
保存为 png ,发现为一张折线图:
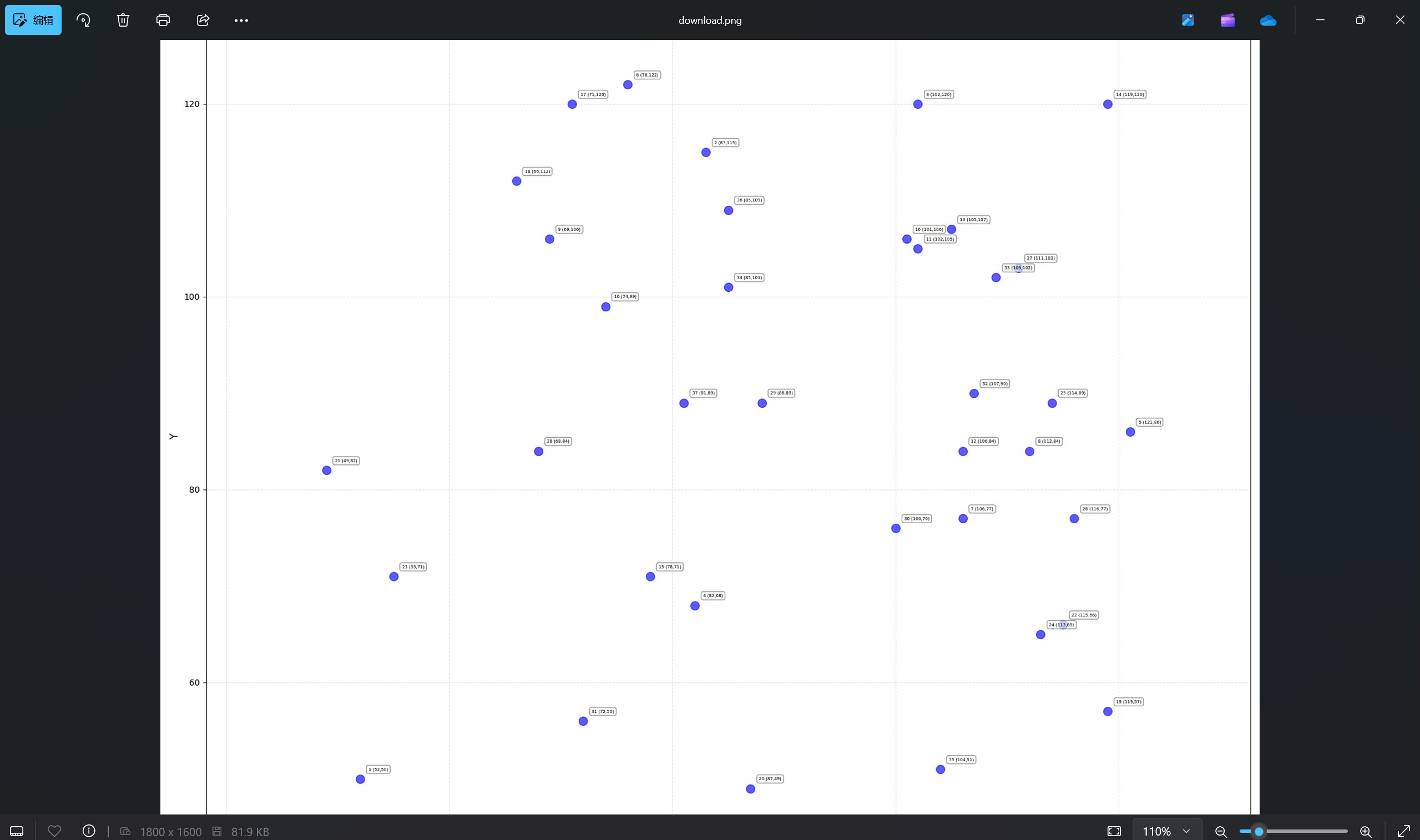
图中标注了点的坐标与序号,对其进行摘抄,发现如下:
1
| [(52, 50), (83, 115), (102, 120), (82, 68), (121, 86), (76, 122), (106, 77), (112, 84), (69, 106), (74, 99), (102, 105), (106, 84), (105, 107), (119, 120), (78, 71), (101, 106), (71, 120), (66, 112), (119, 57), (87, 49), (49, 82), (115, 66), (55, 71), (113, 65), (114, 89), (116, 77), (111, 103), (68, 84), (88, 89), (100, 76), (72, 56), (107, 90), (109, 102), (85, 101), (104, 51), (85, 109), (81, 89)]
|
结合判断这里应该要考察的是坐标隐写,x坐标为前一半数据,y坐标为后一半数据整合一下,然后在利用ascii 进行转换,结果如下:
1
| 4SfRyLjpEJfjiwNeGBwW1s7qrtoDXdHkmUhUQYm3efZ8LYTgMYAGBR19pxjGxkTicjTMzVDxs2
|
栅栏13
1
| 4jiwrHQZM1GcVSpwWtkY8Y9xjDfEN1ommLApkTxRJesDU3YGxTMsyfG7XheTBjiz2LjBqdUfgR
|
base58
1
| .XQ1^F\FQ"12&L#BP(LV1,Lak@qT=->V]c!2I&(J@5TksAi*mS11s>
|
base85
1
| *{r%uL2b2h43hf\_242\cgd2\2bd6\4ba542f4`72gN
|
rot47
1
| YLCTF{a3a9cb97-0aca-485a-a35e-c32dca7c1fa8}
|
最后flag为YLCTF{a3a9cb97-0aca-485a-a35e-c32dca7c1fa8}



