nepctf2023 与AI共舞的哈夫曼 题目描述:
下载附件
查看源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 import heapq import os class HuffmanNode: def __init__(self, char, freq): self.char = char self.freq = freq self.left = None self.right = None def __lt__(self, other): return self.freq < other.freq def build_huffman_tree(frequencies): heap = [HuffmanNode(char, freq) for char, freq in frequencies.items()] heapq.heapify(heap) while len(heap) > 1: left = heapq.heappop(heap) right = heapq.heappop(heap) merged = HuffmanNode(None, left.freq + right.freq) merged.left = left merged.right = right heapq.heappush(heap, merged) return heap[0] def build_huffman_codes(node, current_code, huffman_codes): if node is None: return if node.char is not None: huffman_codes[node.char] = current_code return build_huffman_codes(node.left, current_code + '0', huffman_codes) build_huffman_codes(node.right, current_code + '1', huffman_codes) def compress(input_file, output_file): with open(input_file, 'rb') as f: data = f.read() frequencies = {} for byte in data: if byte not in frequencies: frequencies[byte] = 0 frequencies[byte] += 1 root = build_huffman_tree(frequencies) huffman_codes = {} build_huffman_codes(root, '', huffman_codes) compressed_data = '' for byte in data: compressed_data += huffman_codes[byte] padding = 8 - len(compressed_data) % 8 compressed_data += '0' * padding with open(output_file, 'wb') as f: # Write frequency information f.write(bytes([len(frequencies)])) for byte, freq in frequencies.items(): f.write(bytes([byte, (freq >> 24) & 0xFF, (freq >> 16) & 0xFF, (freq >> 8) & 0xFF, freq & 0xFF])) # Write compressed data for i in range(0, len(compressed_data), 8): byte = compressed_data[i:i+8] f.write(bytes([int(byte, 2)])) if __name__ == "__main__": input_file = 'input.txt' compressed_file = 'compressed.bin' decompressed_file = 'decompressed.txt' # 压缩文件 compress(input_file, compressed_file) # 解压缩文件 decompress(compressed_file, decompressed_file)
霍夫曼压缩,直接让ai分析
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 import heapq import os class HuffmanNode: def __init__(self, char, freq): self.char = char self.freq = freq self.left = None self.right = None def __lt__(self, other): return self.freq < other.freq def build_huffman_tree(frequencies): heap = [HuffmanNode(char, freq) for char, freq in frequencies.items()] heapq.heapify(heap) while len(heap) > 1: left = heapq.heappop(heap) right = heapq.heappop(heap) merged = HuffmanNode(None, left.freq + right.freq) merged.left = left merged.right = right heapq.heappush(heap, merged) return heap[0] def build_huffman_codes(node, current_code, huffman_codes): if node is None: return if node.char is not None: huffman_codes[node.char] = current_code return build_huffman_codes(node.left, current_code + '0', huffman_codes) build_huffman_codes(node.right, current_code + '1', huffman_codes) def compress(input_file, output_file): with open(input_file, 'rb') as f: data = f.read() frequencies = {} for byte in data: if byte not in frequencies: frequencies[byte] = 0 frequencies[byte] += 1 root = build_huffman_tree(frequencies) huffman_codes = {} build_huffman_codes(root, '', huffman_codes) compressed_data = '' for byte in data: compressed_data += huffman_codes[byte] padding = 8 - len(compressed_data) % 8 compressed_data += '0' * padding with open(output_file, 'wb') as f: # Write frequency information f.write(bytes([len(frequencies)])) for byte, freq in frequencies.items(): f.write(bytes([byte, (freq >> 24) & 0xFF, (freq >> 16) & 0xFF, (freq >> 8) & 0xFF, freq & 0xFF])) # Write compressed data for i in range(0, len(compressed_data), 8): byte = compressed_data[i:i+8] f.write(bytes([int(byte, 2)])) def decompress(compressed_file, decompressed_file): with open(compressed_file, 'rb') as f: # 读取频率信息 num_symbols = int.from_bytes(f.read(1), byteorder='big') frequencies = {} for _ in range(num_symbols): byte, freq1, freq2, freq3, freq4 = f.read(5) freq = (freq1 << 24) | (freq2 << 16) | (freq3 << 8) | freq4 frequencies[byte] = freq # 构建哈夫曼树 root = build_huffman_tree(frequencies) # 解压缩数据 current_node = root decompressed_data = bytearray() while True: bit = f.read(1) if not bit: break bit = int.from_bytes(bit, byteorder='big') for i in range(7, -1, -1): if current_node.char is not None: decompressed_data.append(current_node.char) current_node = root if (bit >> i) & 1 == 1: current_node = current_node.right else: current_node = current_node.left # 写入解压缩后的数据 with open(decompressed_file, 'wb') as output_f: output_f.write(decompressed_data) if __name__ == "__main__": input_file = 'input.txt' compressed_file = 'E:\\脚本合集\\赛题脚本\\nepctf\\霍夫曼压缩\\compressed.bin' decompressed_file = 'E:\\脚本合集\\赛题脚本\\nepctf\\霍夫曼压缩\\decompressed.txt' # 解压缩文件 decompress(compressed_file, decompressed_file)
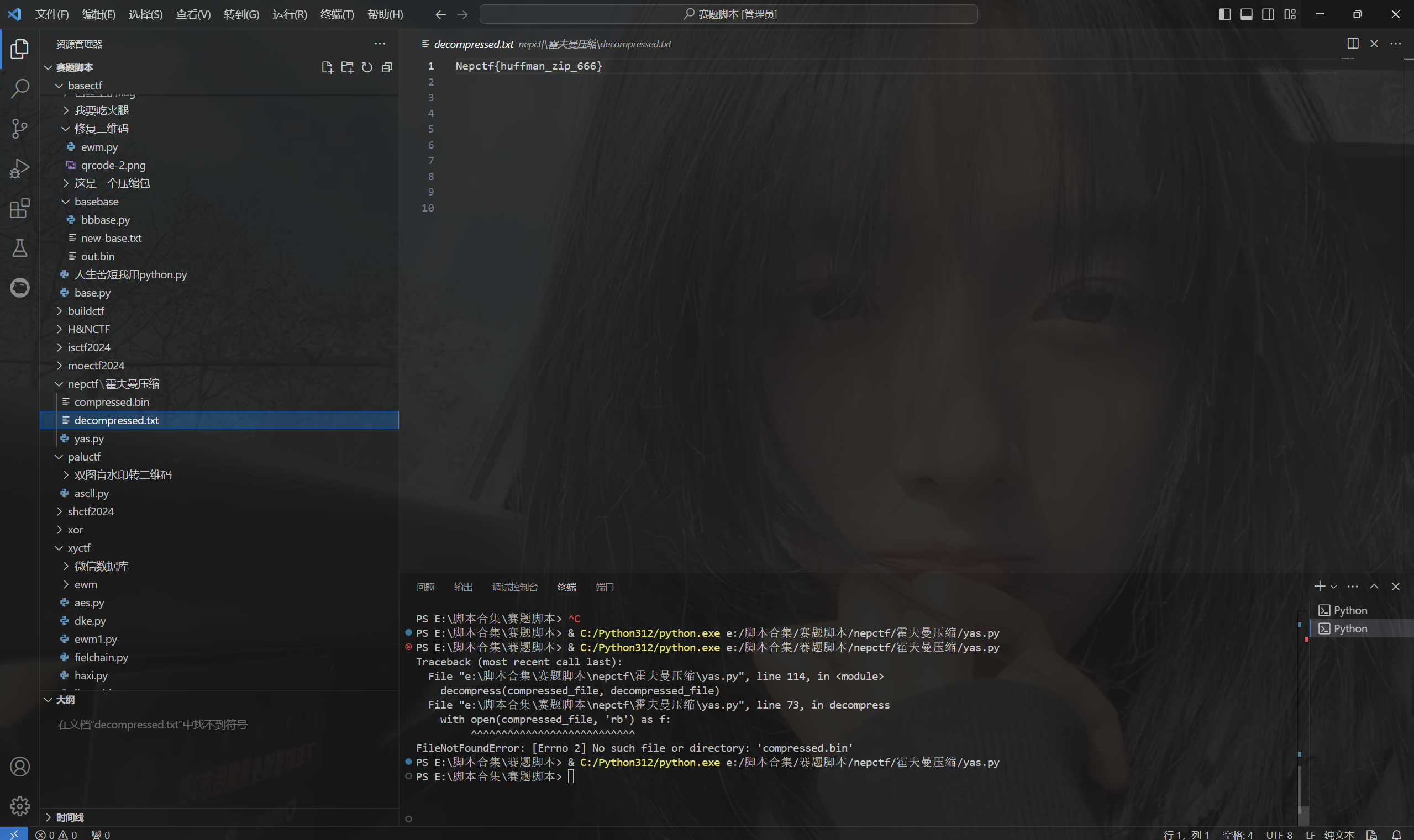
运行得到
最后flag为Nepctf{huffman_zip_666}
陌生的语言 题目描述:
1 2 3 4 5 A同学在回学校的路上捡到了一张纸条,你能帮帮她吗? flag格式:NepCTF{XX_XX} hint:A同学的英文名为“Atsuko Kagari” hint:flag格式请选手根据自身语感自行添加下划线
下载附件
根据hint1得知是《小魔女学园》女主角
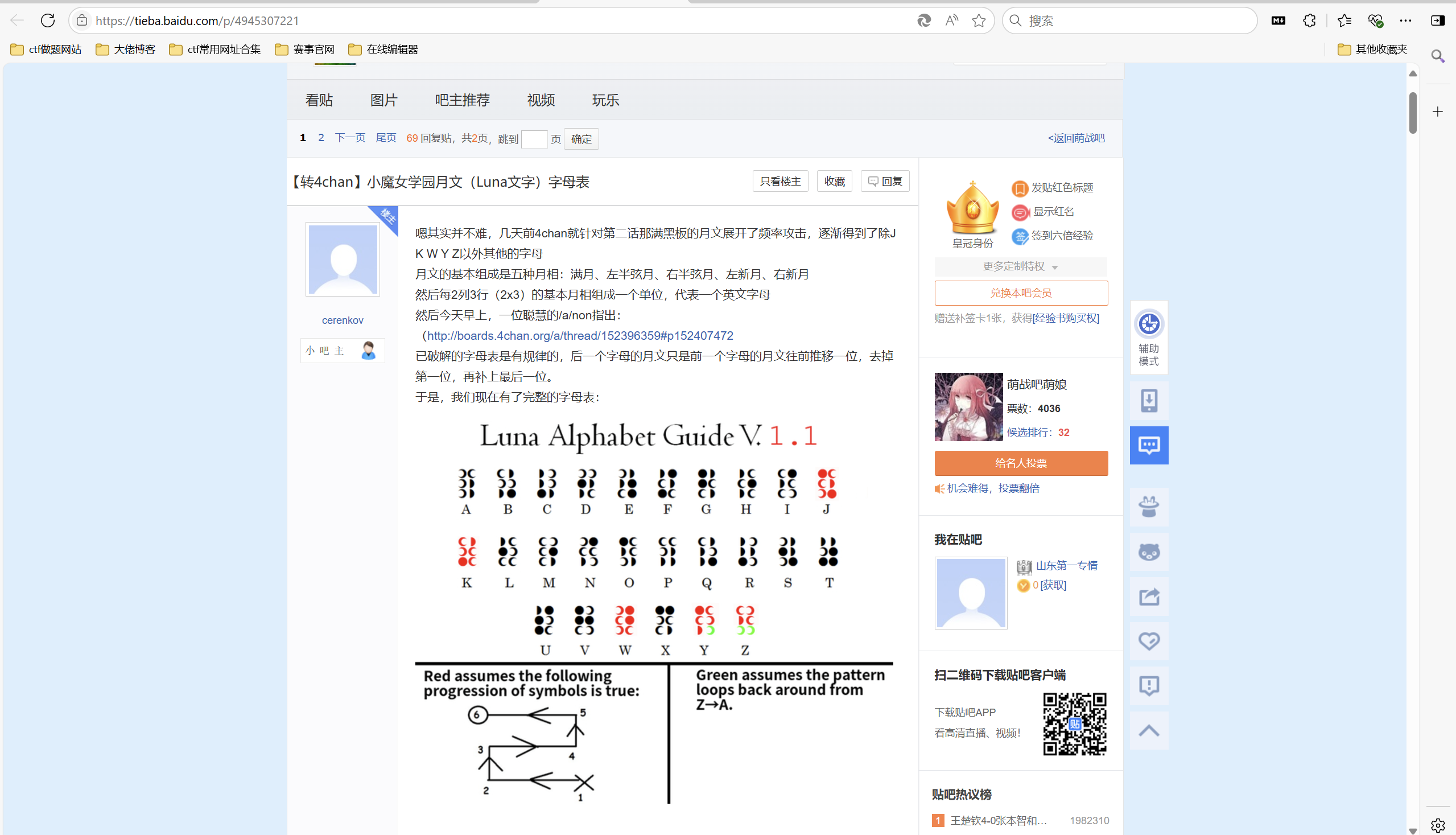
顺着思路找到是新月文字
https://tieba.baidu.com/p/4960864131?fid=7825124&pid=103320700708#103320700708
https://tieba.baidu.com/p/4945307221
对照得到后半段
图片上还有很多箭头,搜到是古龙语
对照得
最后flag为NepCTF{NEPNEP_A_BELIEVING_Heart_is_your_magic}
小叮弹钢琴 题目描述:
下载附件
midi文件是数字音乐接口 电子乐器、合成器等演奏设备之间的一种即时通信协议
使⽤synthesia打开
前半部分是摩斯电码,后半部分是用形状表示的十六进制数字
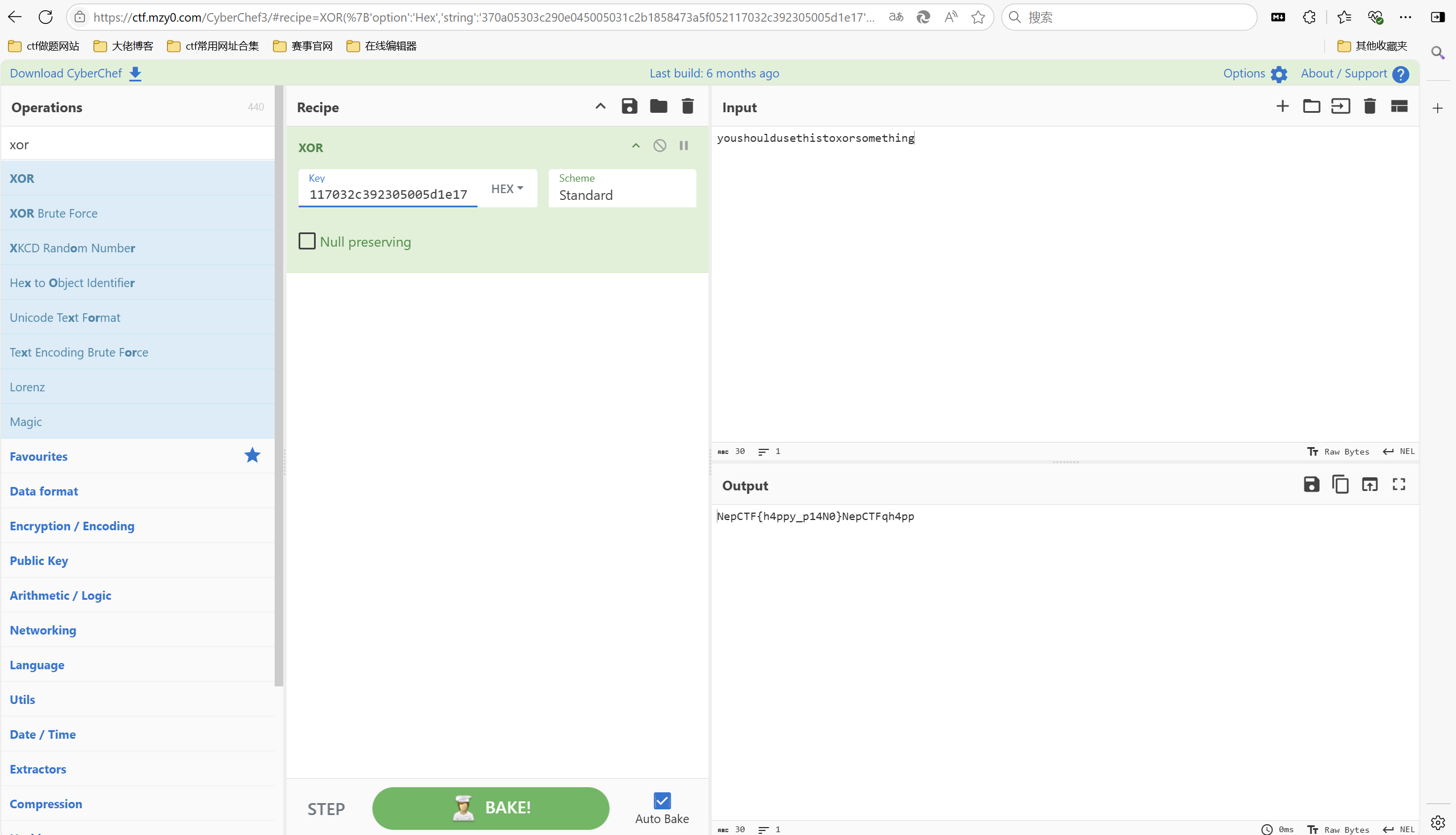
1 2 youshouldusethistoxorsomething 0x370a05303c290e045005031c2b1858473a5f052117032c392305005d1e17
xor直接赛博厨子一把梭
最后flag为NepCTF{h4ppy_p14N0}
你也喜欢三月七么 题目描述:
1 2 3 4 5 6 Nepnep星球如约举办CTF大赛,消息传播至各大星球,开拓者一行人应邀而来 ——————————————————————————————————————— 三月七:耶,终于来到Nepnep星球啦,让我看看正在火热进行的Hacker夺旗大赛群聊。啊!开拓者,这群名看起来怪怪的诶。 (伸出脑袋,凑近群名,轻轻的闻了一下)哇,好咸诶,开拓者你快来看看! 开拓者(U_id):(端着下巴,磨蹭了一下,眼神若有所思)这好像需要经过啥256处理一下才能得到我们需要的关键。 三月七:那我们快想想怎么解开这个谜题! flag格式:NepCTF{+m+}
下载附件
查看Have you ever played Star Railway.txt内容
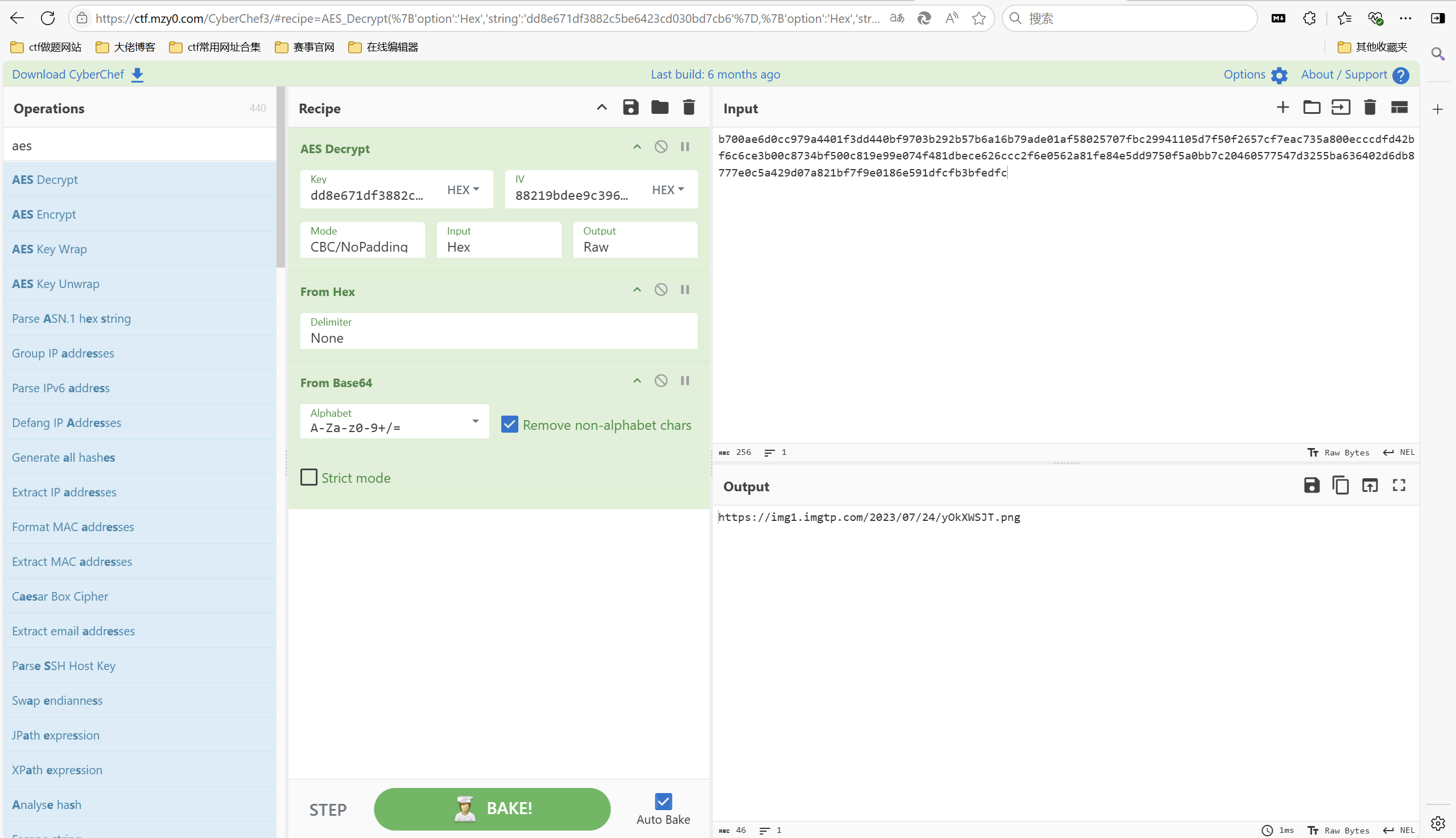
1 2 3 4 salt_lenth= 10 key_lenth= 16 iv= 88219bdee9c396eca3c637c0ea436058 #原始iv转hex的值 ciphertext= b700ae6d0cc979a4401f3dd440bf9703b292b57b6a16b79ade01af58025707fbc29941105d7f50f2657cf7eac735a800ecccdfd42bf6c6ce3b00c8734bf500c819e99e074f481dbece626ccc2f6e0562a81fe84e5dd9750f5a0bb7c20460577547d3255ba636402d6db8777e0c5a429d07a821bf7f9e0186e591dfcfb3bfedfc
赛博厨子AES解密
访问网址得到
玩过星穹铁道的一眼就知道是宇宙通用文
文字对照表 - 星穹铁道列车智库 - 灰机wiki - 北京嘉闻杰诺网络科技有限公司
对照得到 HRP_always_likes_March_7th
最后flag为NepCTF{HRP_always_likes_March_7th}
nepctf2024 NepMagic —— CheckIn 题目描述:
1 简单的签到游戏(真的签到,不是签到来砍我),正常游玩即可在最后获得flag
下载附件
开始新游戏
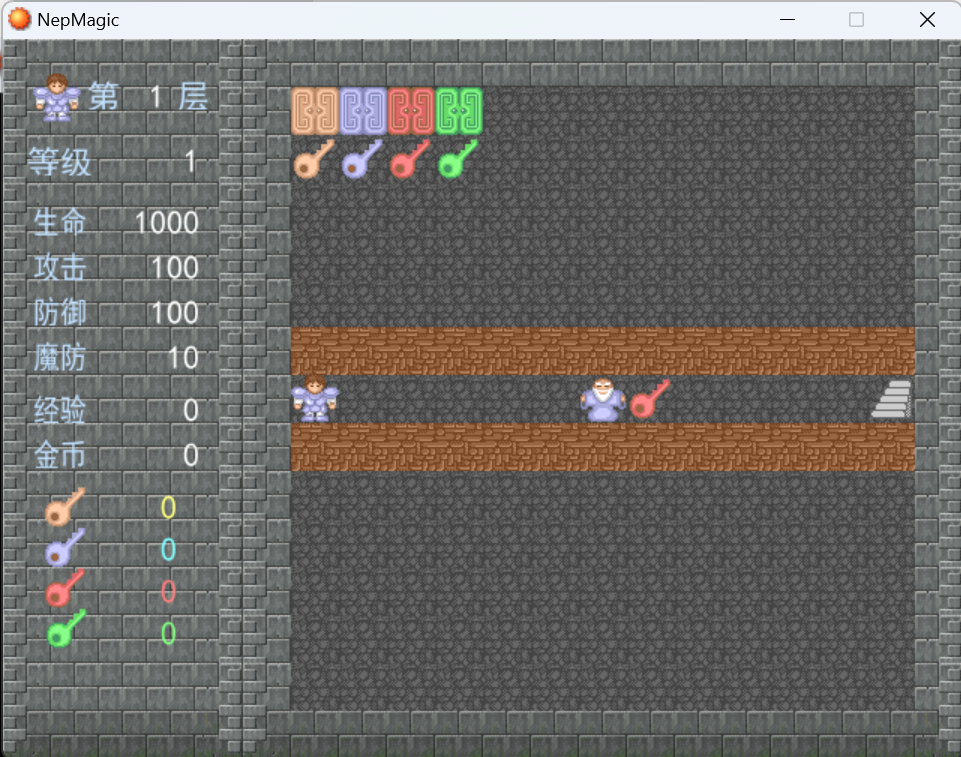
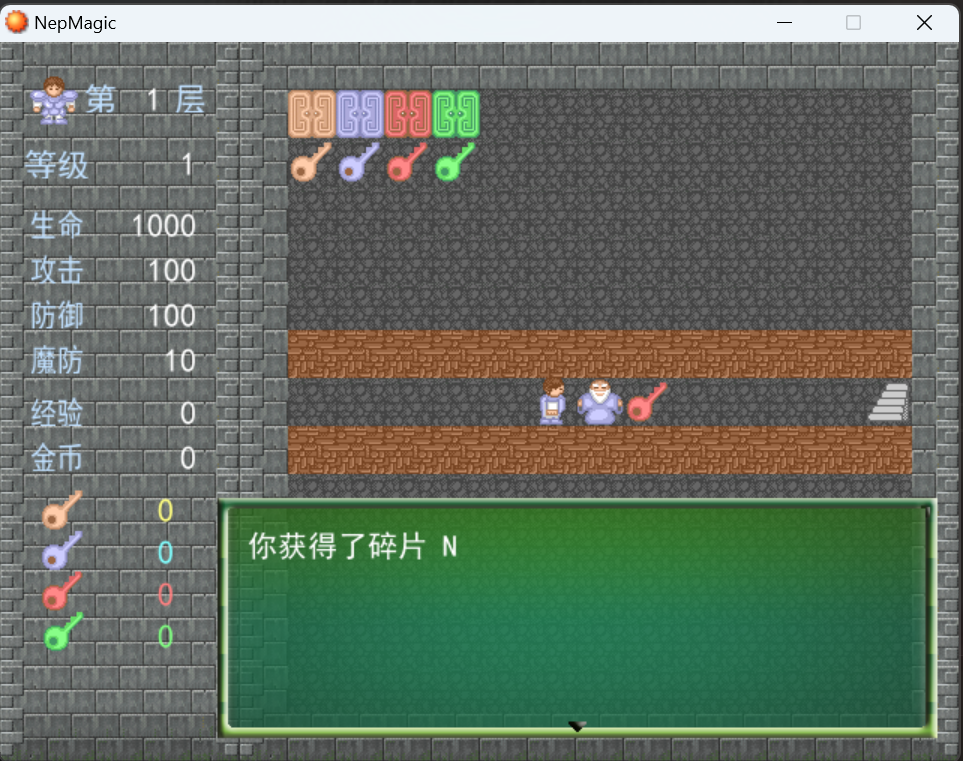
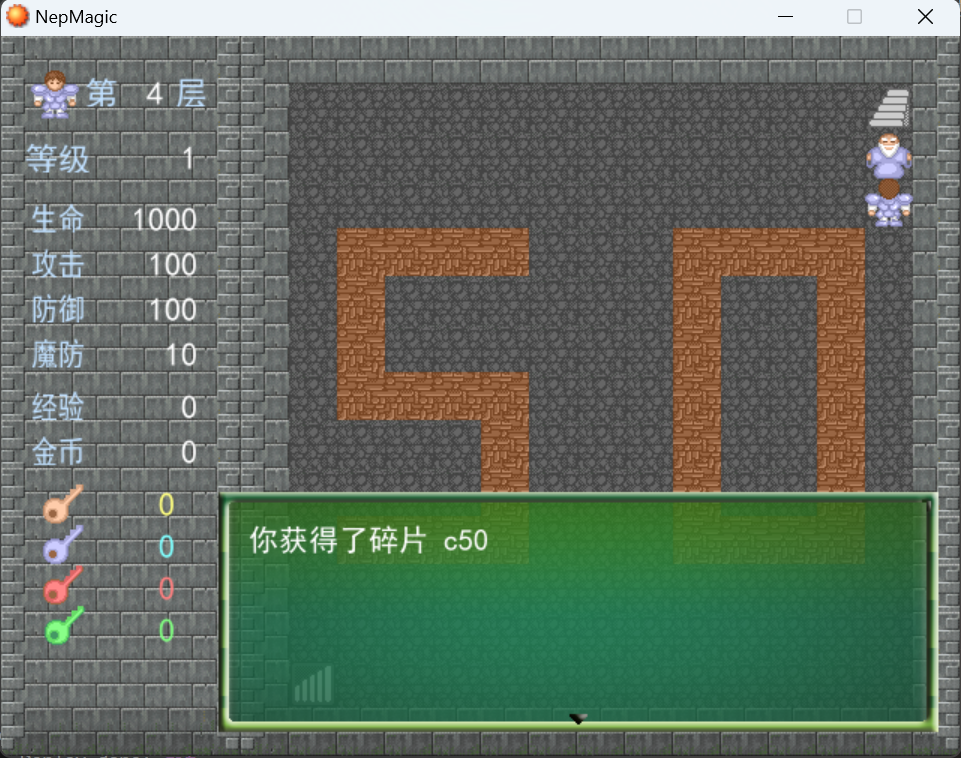
第一层
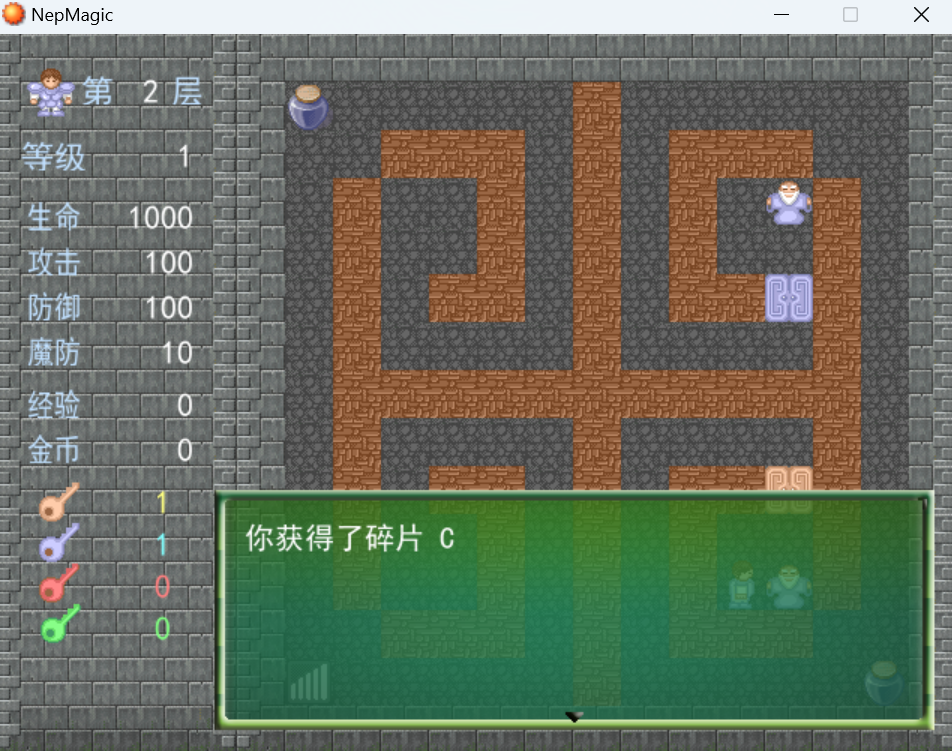
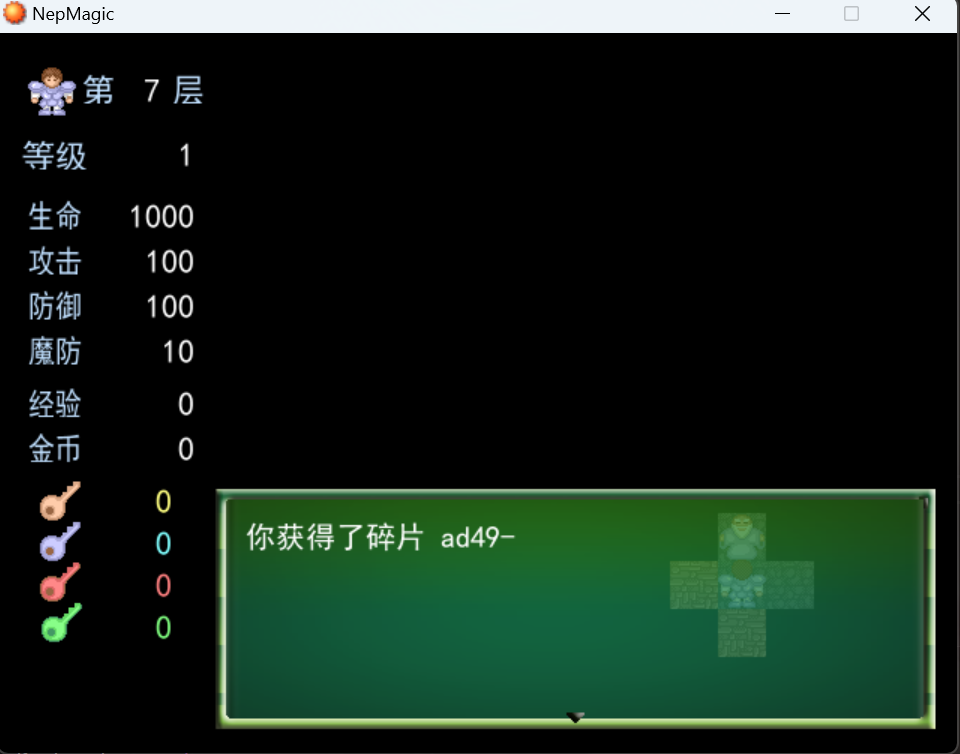
与NPC对话得到第一块碎片
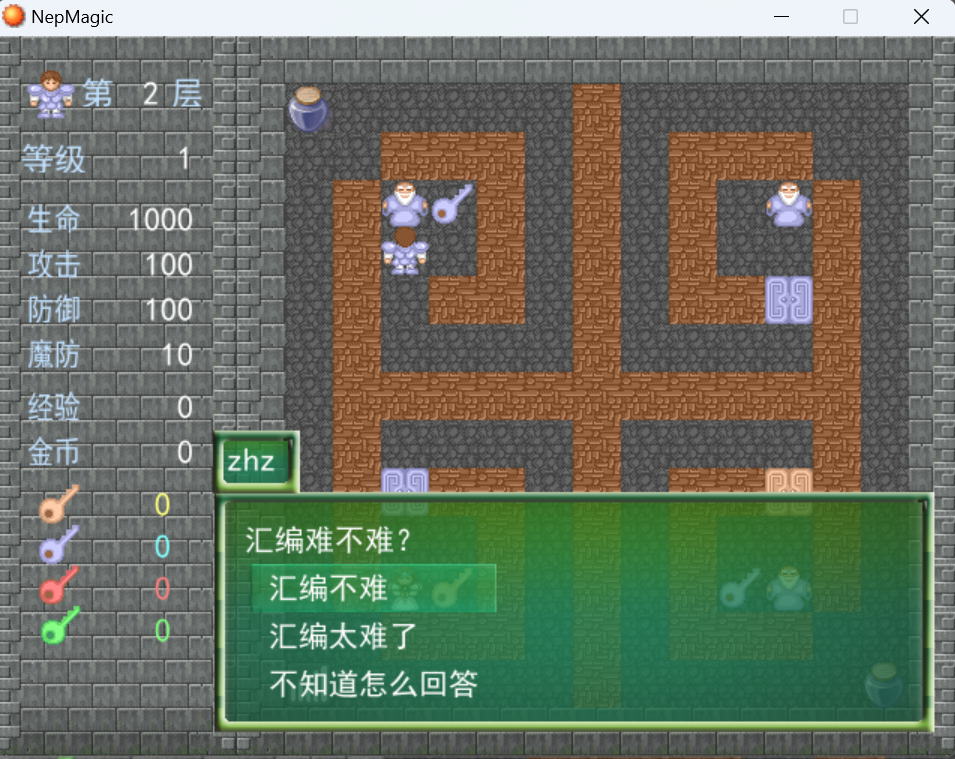
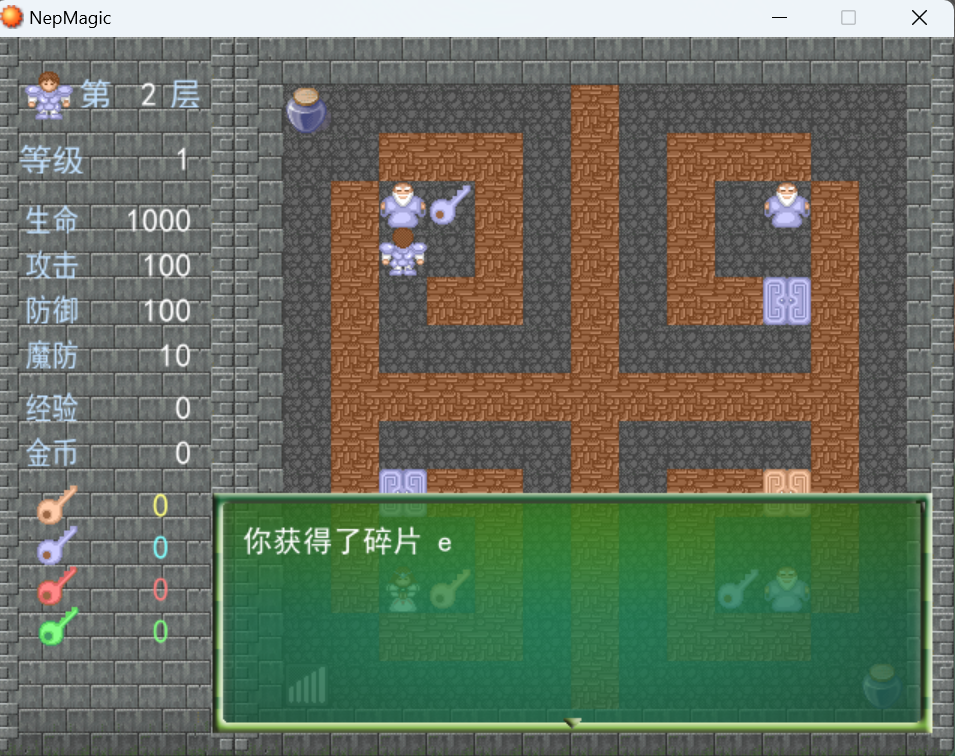
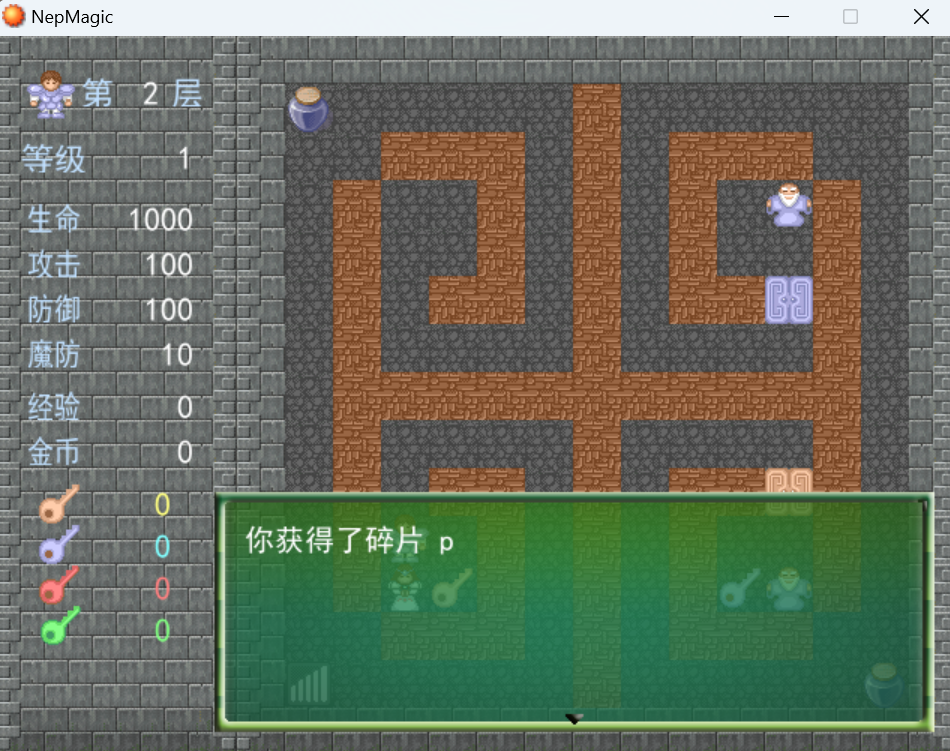
第二层
回答汇编不难得到第二块碎片
拿到蓝钥匙开门与天使NPC对话得到第三块碎片
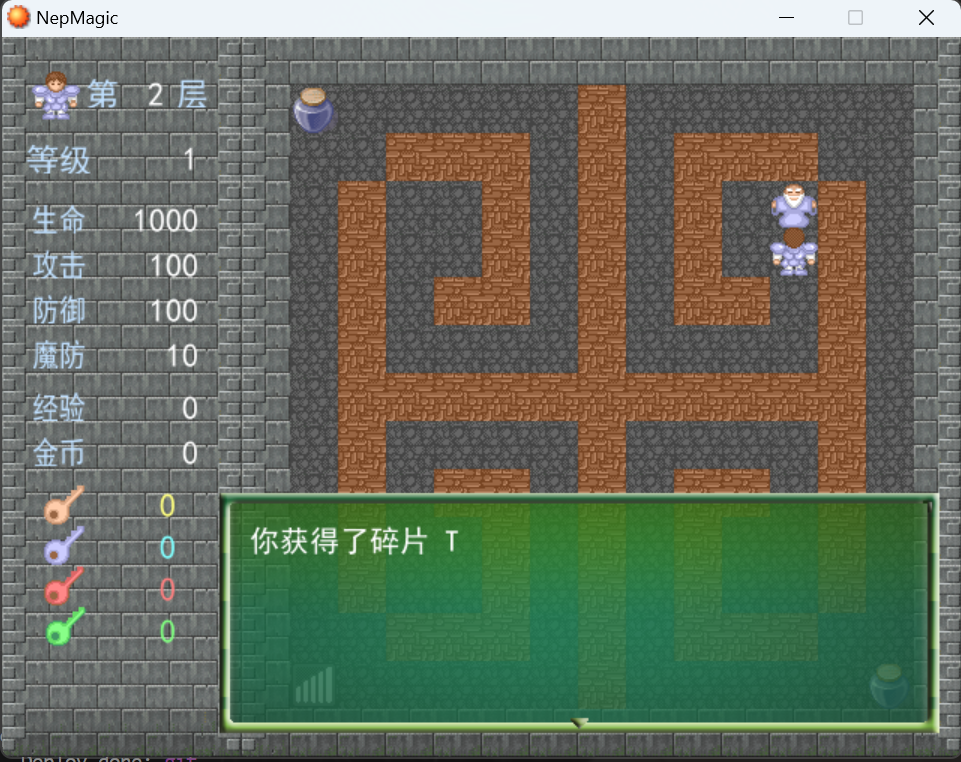
使用对称飞行器到指定位置与NPC对话回答问题,选择Linux是世界上最好的系统和windows是什么垃圾选项得到第四块碎片
再与上面的NPC对话得到第五块碎片
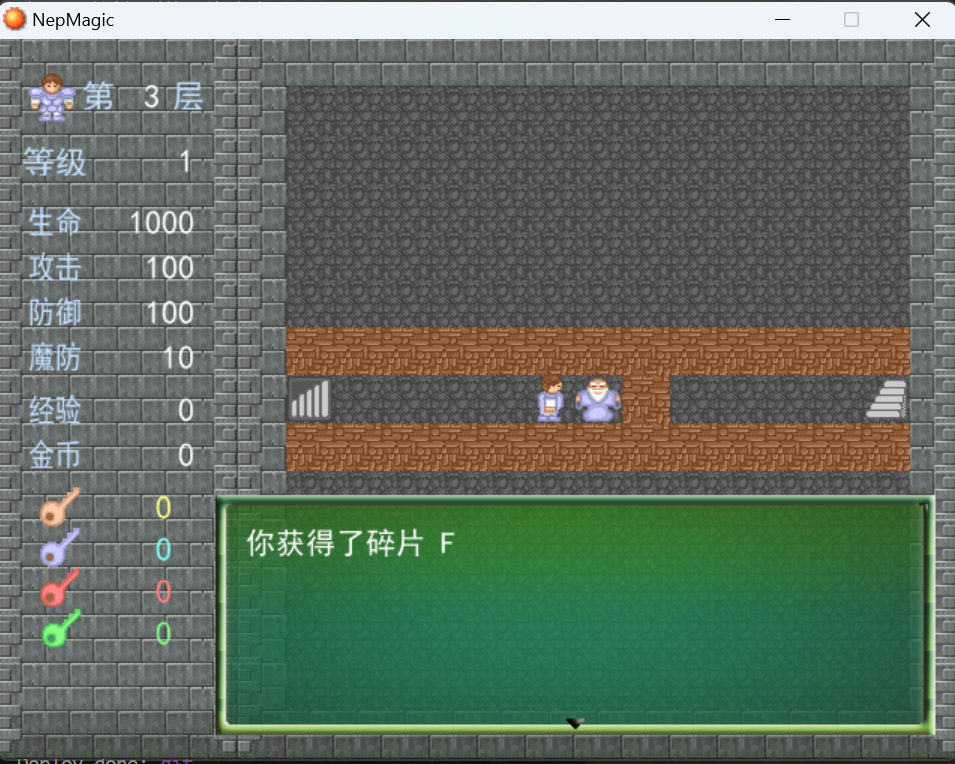
第三层
与NPC对话得到第六块碎片
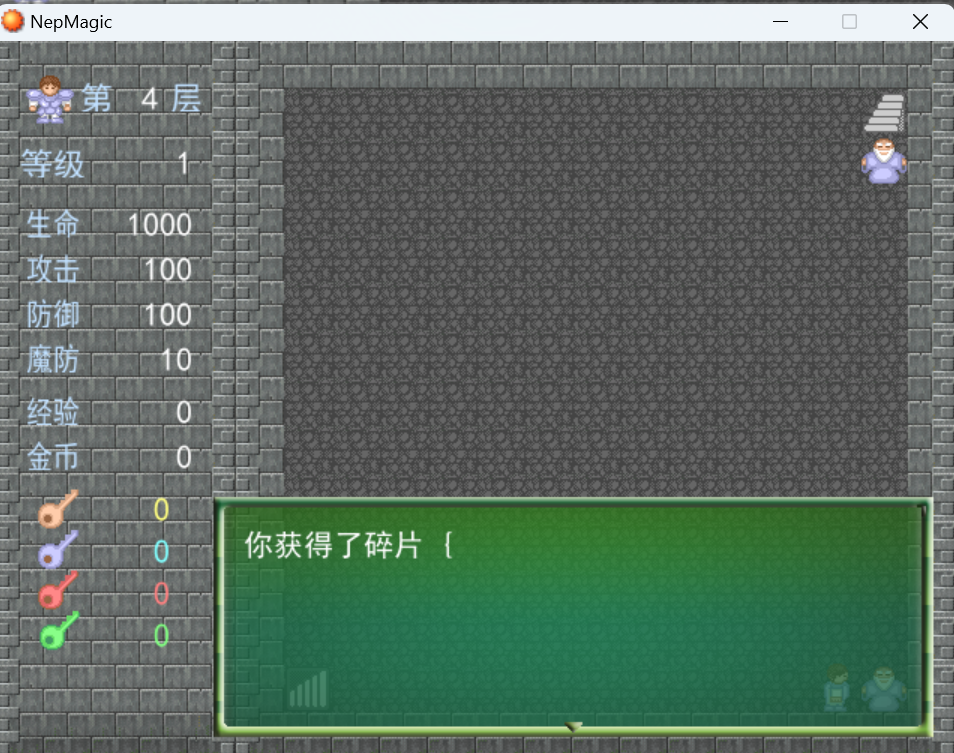
破墙镐进入第四层
与npc对话得到第七块碎片
四处碰壁得到第八块碎片
再与npc对话得到第九块碎片
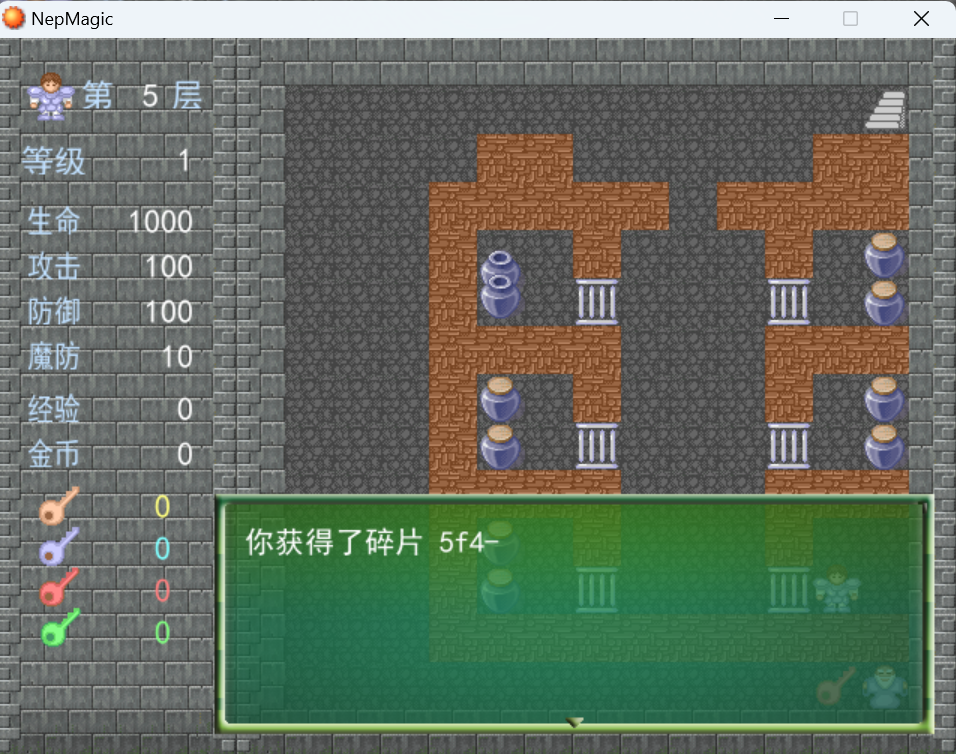
第五层,使用npc给的上楼器得到第十块碎片
与npc对话得到第十一块碎片
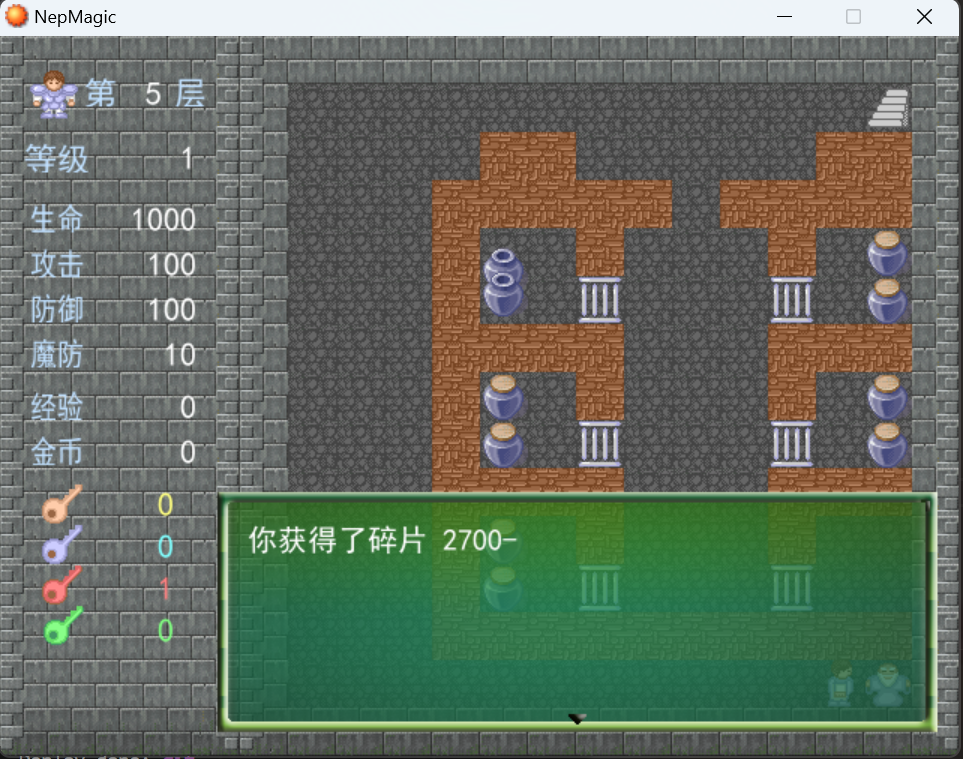
第六层使用红色钥匙开门与npc对话得到第十二块碎片
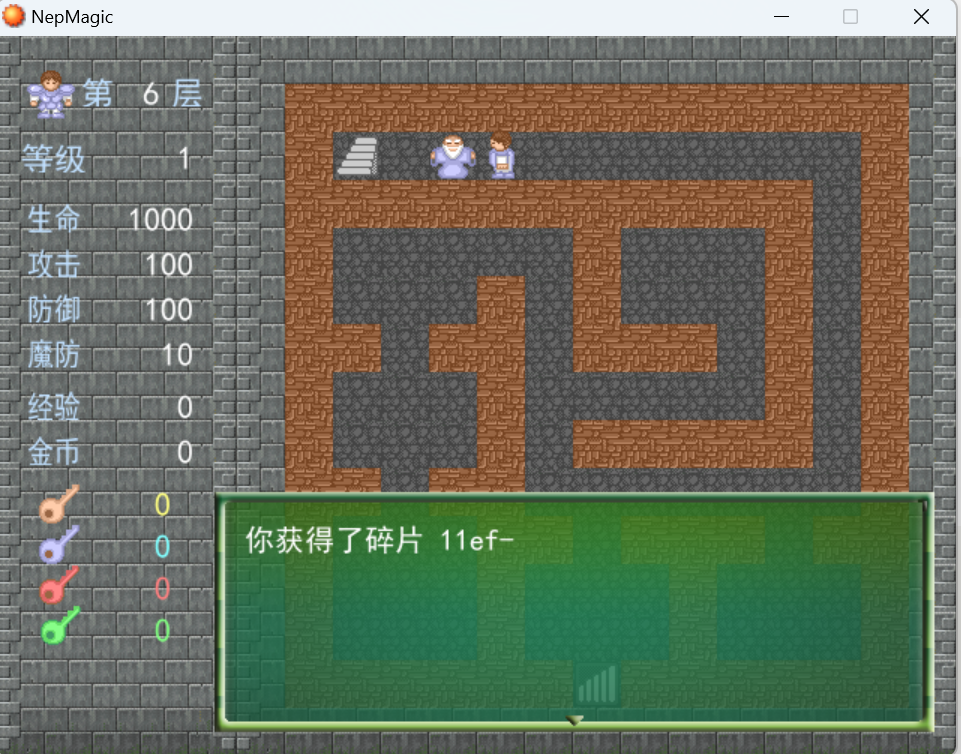
第七层摸黑找到npc与其对话得到第十三块碎片
第八层与npc对话得到第十四块碎片
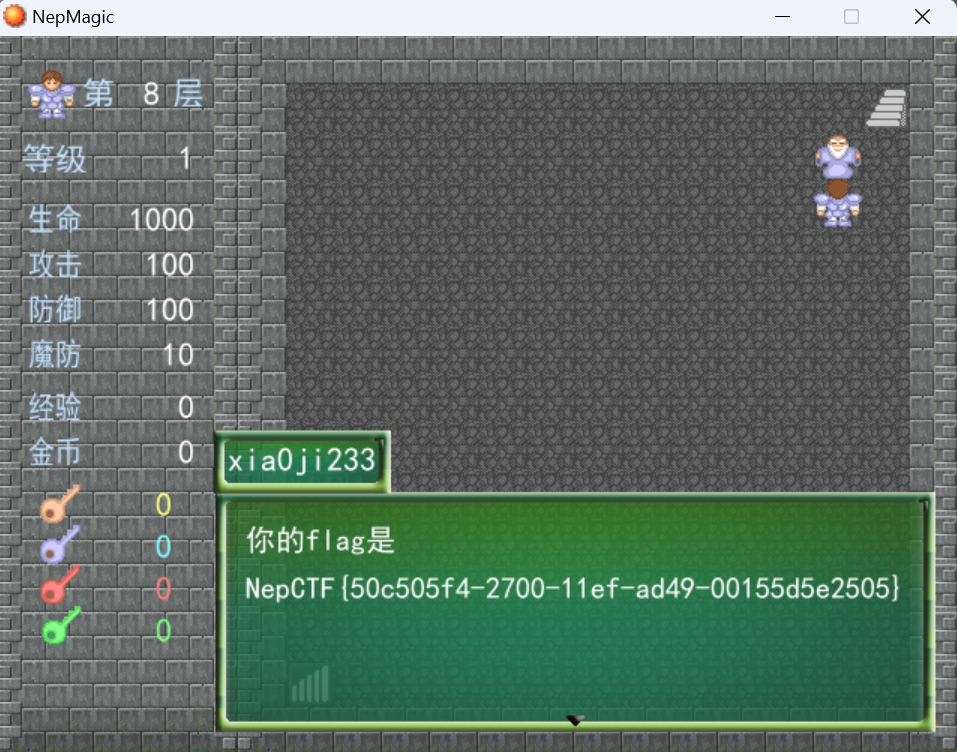
与最上面的npc对话得到最后flag
最后flag为NepCTF{50c505f4-2700-11ef-ad49-00155d5e2505}
Nemophila 题目描述:
下载附件
mimi.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import base64 print("这里有一个藏宝室,镇守着一个宝箱怪,当你说出正确的口令时,你也就快获得了这个屋子里最至高无上的宝物。") print("提示:宝箱怪只会提示你口令正确与否,请你试试吧!") flag = input('Turn in your guess: ') if len(flag) !=48: print("长度不对!") exit(1) if ord(flag.capitalize()[0]) != 83 or not flag[0].islower(): print("Please try again!") exit(1) if flag[-3:] != "ve}": print("Please try again!") exit(1) if flag.count(chr(95)) != 4: print("Please try again!") exit(1) if base64.b64encode((flag[10:13]+flag[28:31]).encode('utf-8')).decode() != 'RnJpSGlt': print("Please try again!") exit(1) if int(flag[24:26]) > 10 and int(flag[24:26]) < 20 and pow(int(flag[24:26]),2,5) != 0: print("好像有点不对!") exit(1) number = flag[33] + flag[41] + flag[43:45] if int(number) * 9_27 != 1028970 and not number.isnumeric(): print("还是不对呢!") exit(1) if flag[35:41].replace("e", "1") != "1t1rna": print("Please try again!") exit(1) if flag[31:33].swapcase() != "ME": print("这不是我!") exit(1) if list(map(len,flag.split("_"))) != [6, 12, 14, 7, 5] and list(map(len,flag.split("&"))) != [17, 9, 20]: print("换个顺序!") exit(1) if ord(min(flag[:2].swapcase())) != 69: print("Please try again!") exit(1) if flag[2] + flag[4:6] != "cet4"[:3]: print("我不想考四级!") exit(1) new="" for i in flag[7:10] + flag[18] + flag[26]: new += chr(ord(i) + 1) if new != "jt|Df": print("Please try again!") exit(1) if "SunR" in flag and "eren" in flag: print("好像对了!可以先去试试!") exit(1) print("恭喜你~发现了上个世纪的秘密~快去向冒险家协会索要报酬吧!")
分析代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 这段代码是一个有趣的寻宝游戏,其中玩家需要输入一个特定格式的字符串(即“口令”)来解锁一个宝箱怪的谜题。这个字符串必须满足多个条件才能被认为是正确的。下面是每个条件的解释和如何一步步解析这些条件: 长度要求: 口令的长度必须是48个字符。 首字母检查: 口令的首字母必须是's'(小写),并且第二个字符(首字母大写后)的ASCII码值必须是83(即'S')。 尾字符检查: 口令的最后三个字符必须是"ve}"。 下划线数量: 口令中必须包含4个下划线字符('_')。 Base64编码检查: 口令中第11到13个字符和第29到31个字符组成的字符串,经过Base64编码后,必须是"RnJpSGlt"。 数字范围及模运算: 口令中第25到26个字符组成的数字必须在10到19之间,且这个数字的平方对5取模的结果不能为0。 特定字符和数字运算: 口令中第34个字符、第42个字符、以及第44到45个字符组成的字符串,表示的数字乘以927(这里9_27应该理解为927,Python中数字间的下划线可以忽略)必须等于1028970,且这个字符串必须是数字。 字符替换检查: 口令中第36到41个字符组成的字符串,将'e'替换为'1'后,必须是"1t1rna"。 大小写交换检查: 口令中第32到33个字符的大小写交换后,必须是"ME"。 分割后的长度检查: 口令按"_"分割后的各段长度必须是[6, 12, 14, 7, 5];或者按"&"分割后的各段长度必须是[17, 9, 20]。 最小字符的ASCII码检查: 口令前两个字符大小写交换后的最小字符的ASCII码值必须是69(即'E')。 特定子字符串检查: 口令中第3个字符和第5到6个字符组成的字符串必须是"cet4"的前三个字符。 字符ASCII码加1后的结果: 口令中第8到10个字符、第19个字符、以及第27个字符组成的字符串,每个字符的ASCII码加1后,结果必须是"jt|Df"。 子字符串存在性检查: 口令中必须包含"SunR"和"eren"这两个子字符串。 如果输入的口令满足所有上述条件,则游戏会显示“恭喜你发现了上个世纪的秘密快去向冒险家协会索要报酬吧!”;否则,会根据不满足的条件给出相应的提示,并退出游戏。 这是一个结合了字符串处理、ASCII码操作、Base64编码、数学运算等知识的趣味编程挑战。
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import base64 # 补全 flag = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" # 将字符串转换为列表 flag_list = list(flag) flag_list[0] = chr(83).lower() flag_list[-3:] = "ve}" # base64解密带入 base64_code = list(base64.b64decode("RnJpSGlt").decode('utf-8')) flag_list[10:13] = base64_code[0:3] flag_list[28:31] = base64_code[3:] # 简单数学计算答案15 flag_list[24] = "1" flag_list[25] = "5" # 计算带入 number = str(int(1028970/927)) flag_list[33] = number[0] flag_list[41] = number[1] flag_list[43:45] = number[2:] str1 = "1t1rna".replace("1", "e") flag_list[35:41] = str1 # 转化大小写 flag_list[31:33] = "me" # 进行分割 flag_list[6] = "_" flag_list[19] = "_" flag_list[34] = "_" flag_list[42] = "_" flag_list[17] = "&" flag_list[27] = "&" flag_list[1] = chr(69).lower() flag_list[2] = "cet4"[0] flag_list[4:6] = "cet4"[1:3] flag_list[7] = chr(ord('j') - 1) flag_list[8] = chr(ord('t') - 1) flag_list[9] = chr(ord('|') - 1) flag_list[18] = chr(ord('D') - 1) flag_list[26] = chr(ord('f') - 1) # 前面的是芙莉莲后面的是辛美尔 flag_list[13:17] = "eren" flag_list[20:24] = "SunR" # 猜测是单词secret flag_list[3] = "r" flag = ''.join(flag_list) print(flag)
运行得到 secret_is{Frieren&C_SunR15e&Himme1_eterna1_10ve}
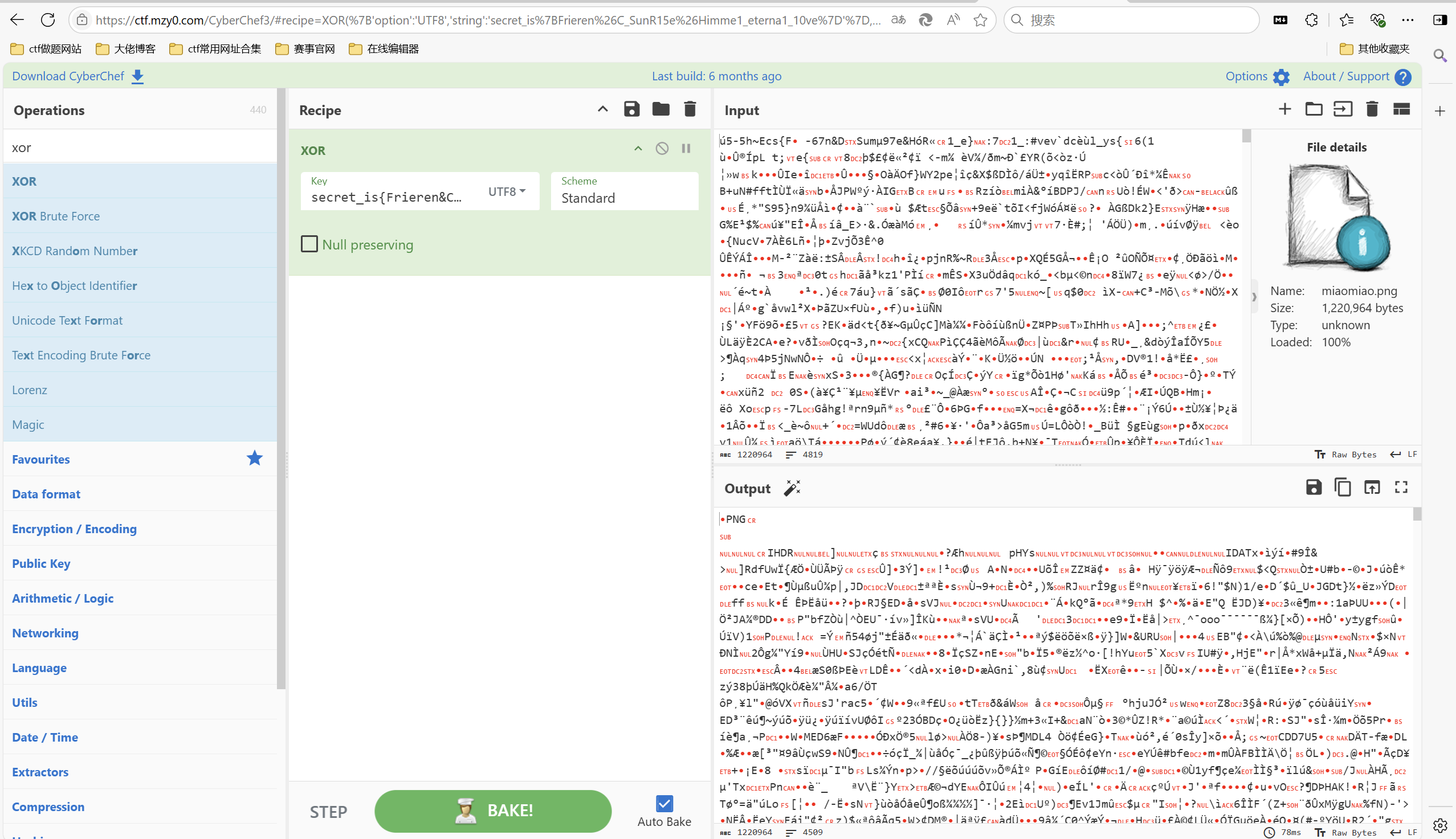
解压压缩包得到无显示图片,xor图片
下载并打开图片
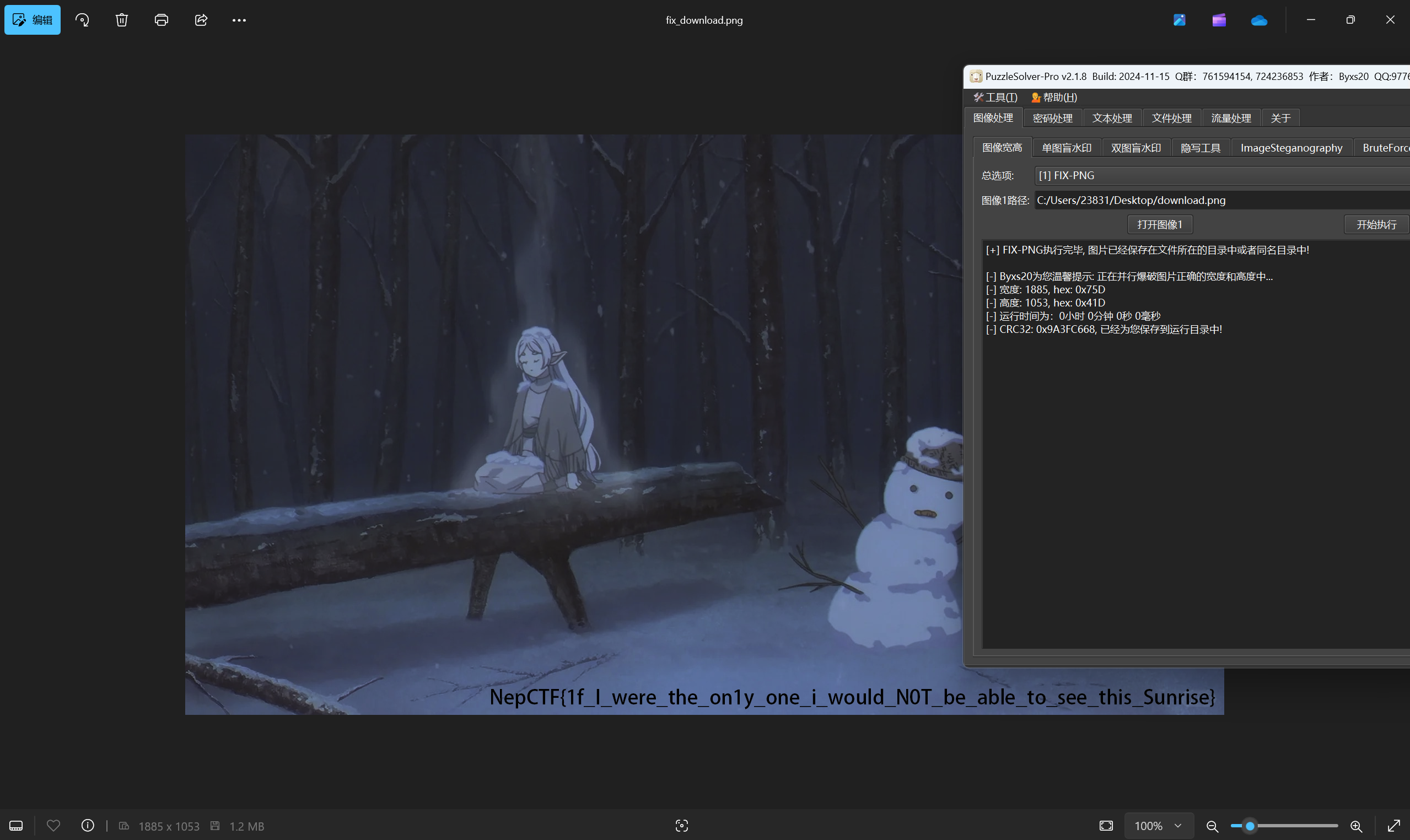
宽高一把梭
最后flag为NepCTF{1f_I_were_the_on1y_one_i_would_N0T_be_able_to_see_this_Sunrise}
3DNep 题目描述:
下载附件,010查看是glTF文件
随便找个glTF在线编辑器打开
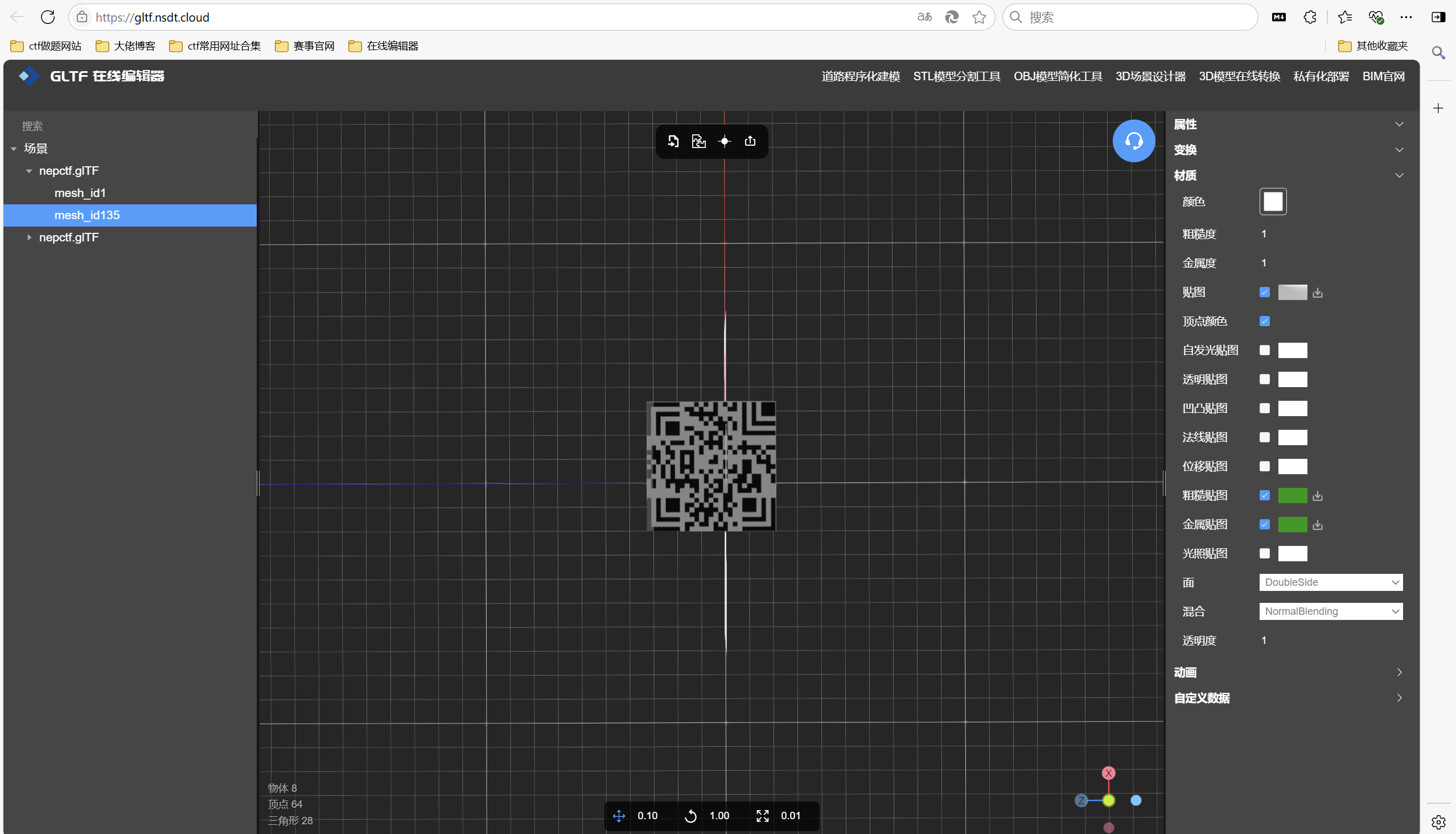
转移视角,发现底部是汉信码
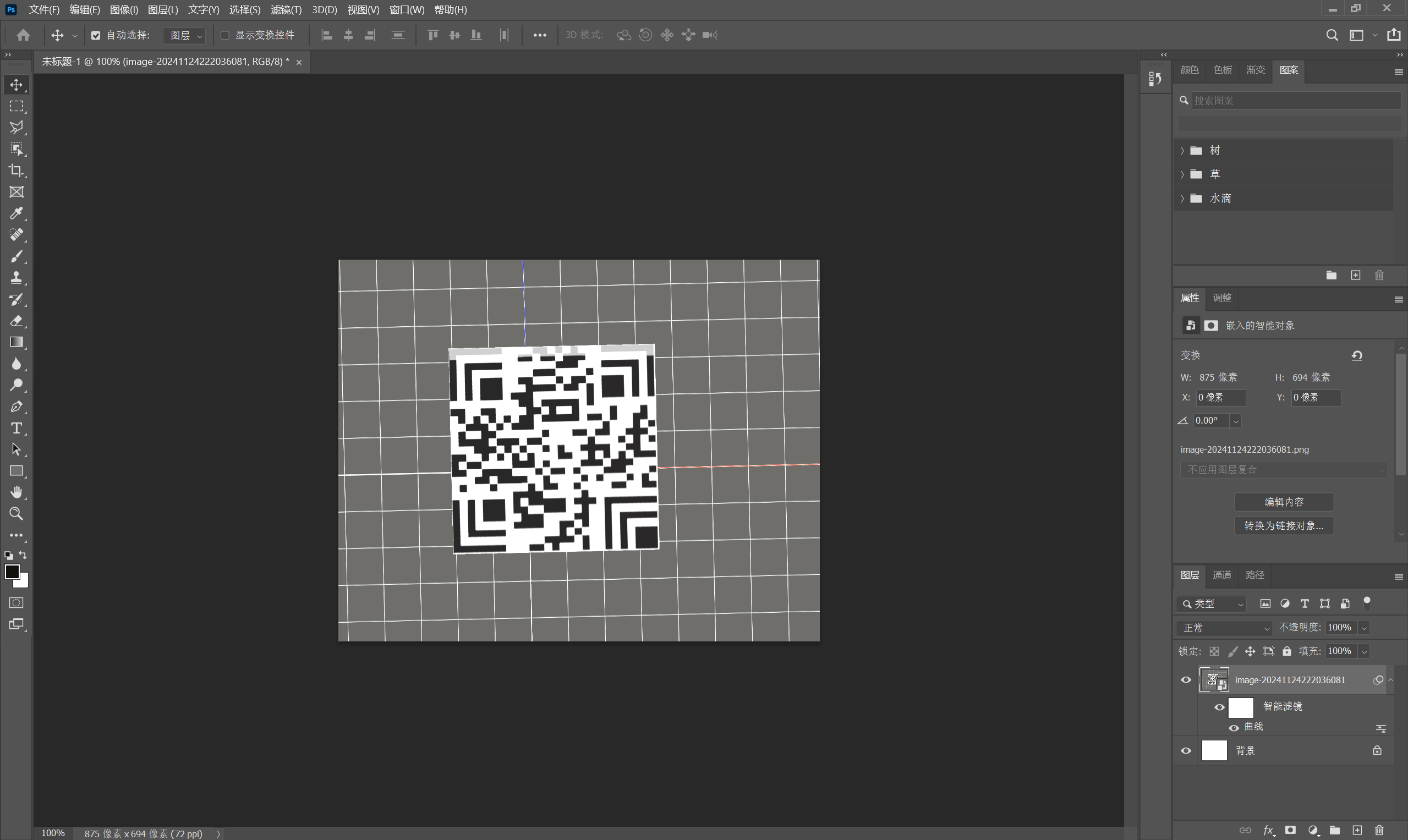
ps调整亮度
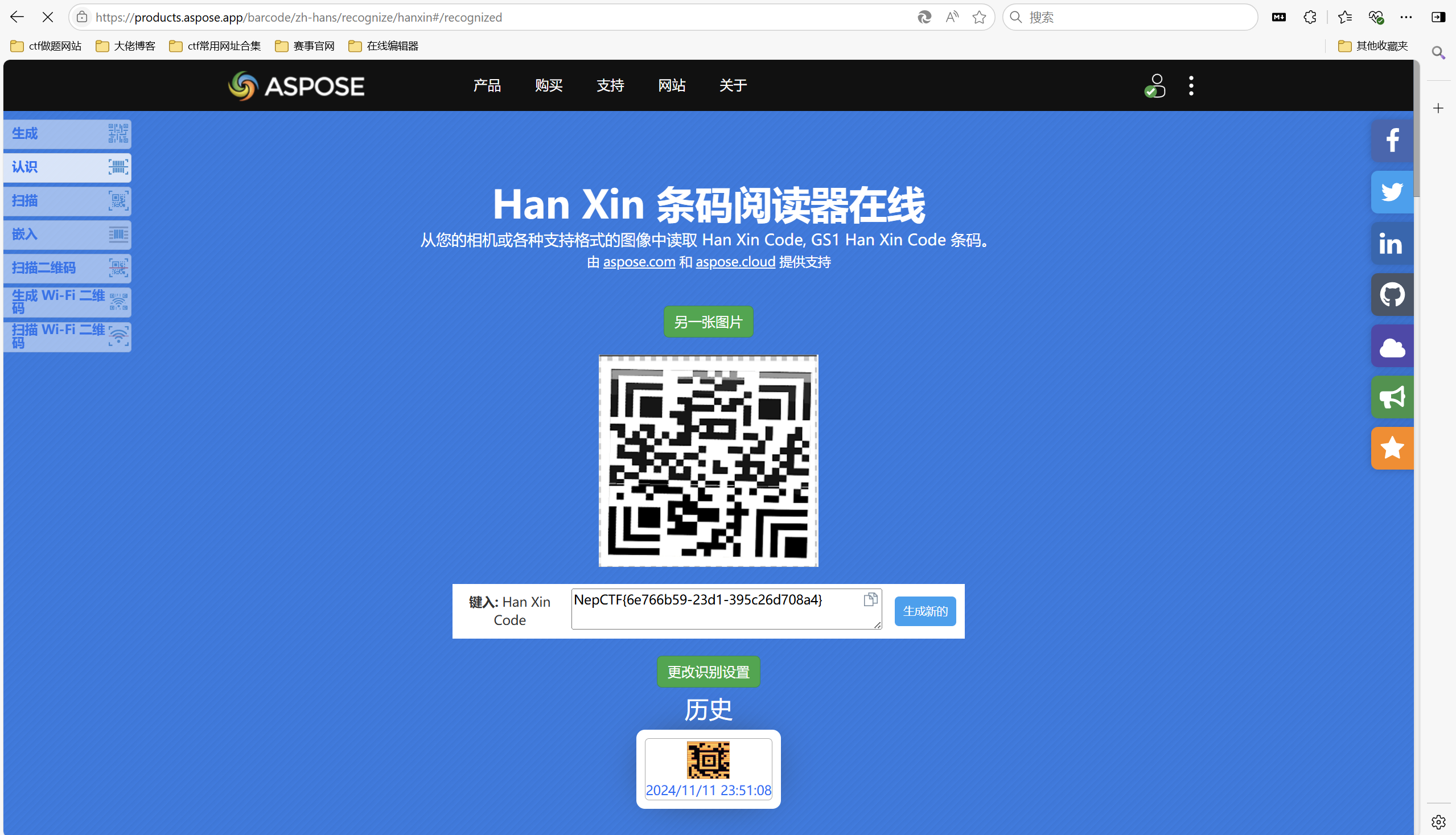
汉信码扫描得到flag
最后flag为NepCTF{6e766b59-23d1-395c26d708a4}
NepCamera 题目描述:
1 坏女人背着我们偷偷学习的证据被摄像头记录下来了,让我们看看她在学什么!
下载附件
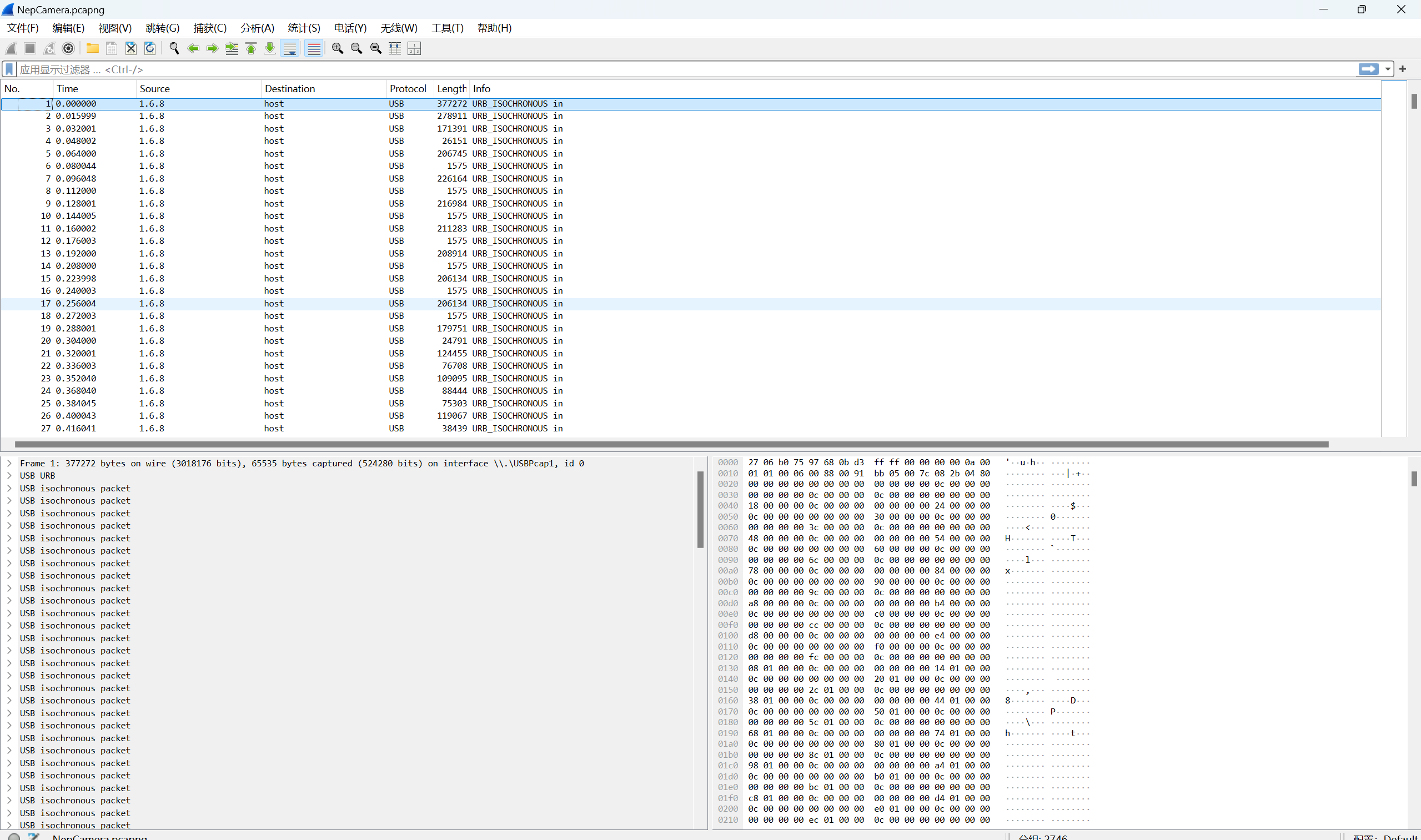
看到都是USB协议的数据,发现每个数据包中都能看到传输了JPG图片,定位每一帧传输的JPG图片,把所有摄像头视频流传输的图片提取出来
exp:
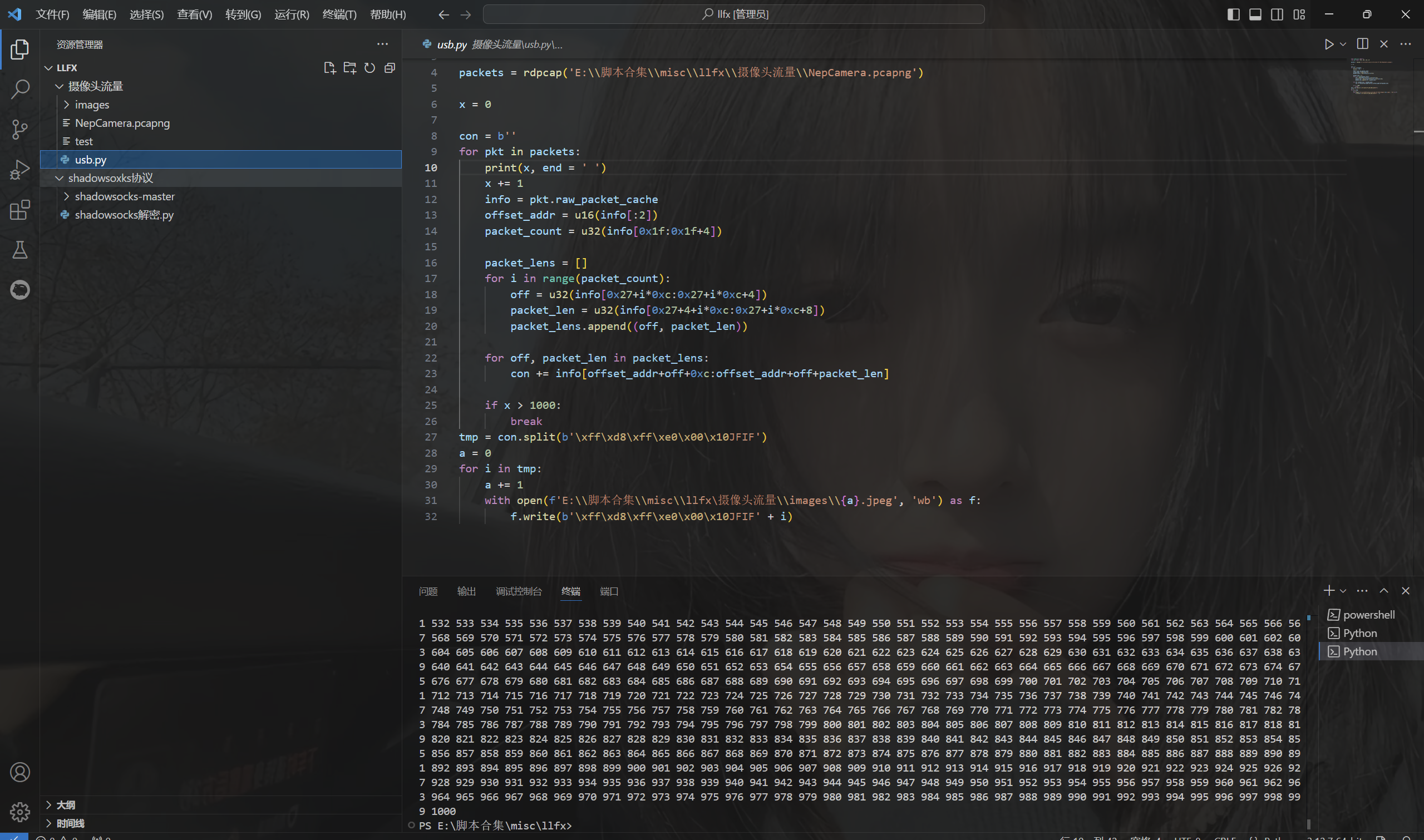
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from scapy.all import * from pwn import u32, u64, u16, u8 packets = rdpcap('E:\\脚本合集\\misc\\llfx\\摄像头流量\\NepCamera.pcapng') x = 0 con = b'' for pkt in packets: print(x, end = ' ') x += 1 info = pkt.raw_packet_cache offset_addr = u16(info[:2]) packet_count = u32(info[0x1f:0x1f+4]) packet_lens = [] for i in range(packet_count): off = u32(info[0x27+i*0xc:0x27+i*0xc+4]) packet_len = u32(info[0x27+4+i*0xc:0x27+i*0xc+8]) packet_lens.append((off, packet_len)) for off, packet_len in packet_lens: con += info[offset_addr+off+0xc:offset_addr+off+packet_len] if x > 1000: break tmp = con.split(b'\xff\xd8\xff\xe0\x00\x10JFIF') a = 0 for i in tmp: a += 1 with open(f'E:\\脚本合集\\misc\\llfx\摄像头流量\\images\\{a}.jpeg', 'wb') as f: f.write(b'\xff\xd8\xff\xe0\x00\x10JFIF' + i)
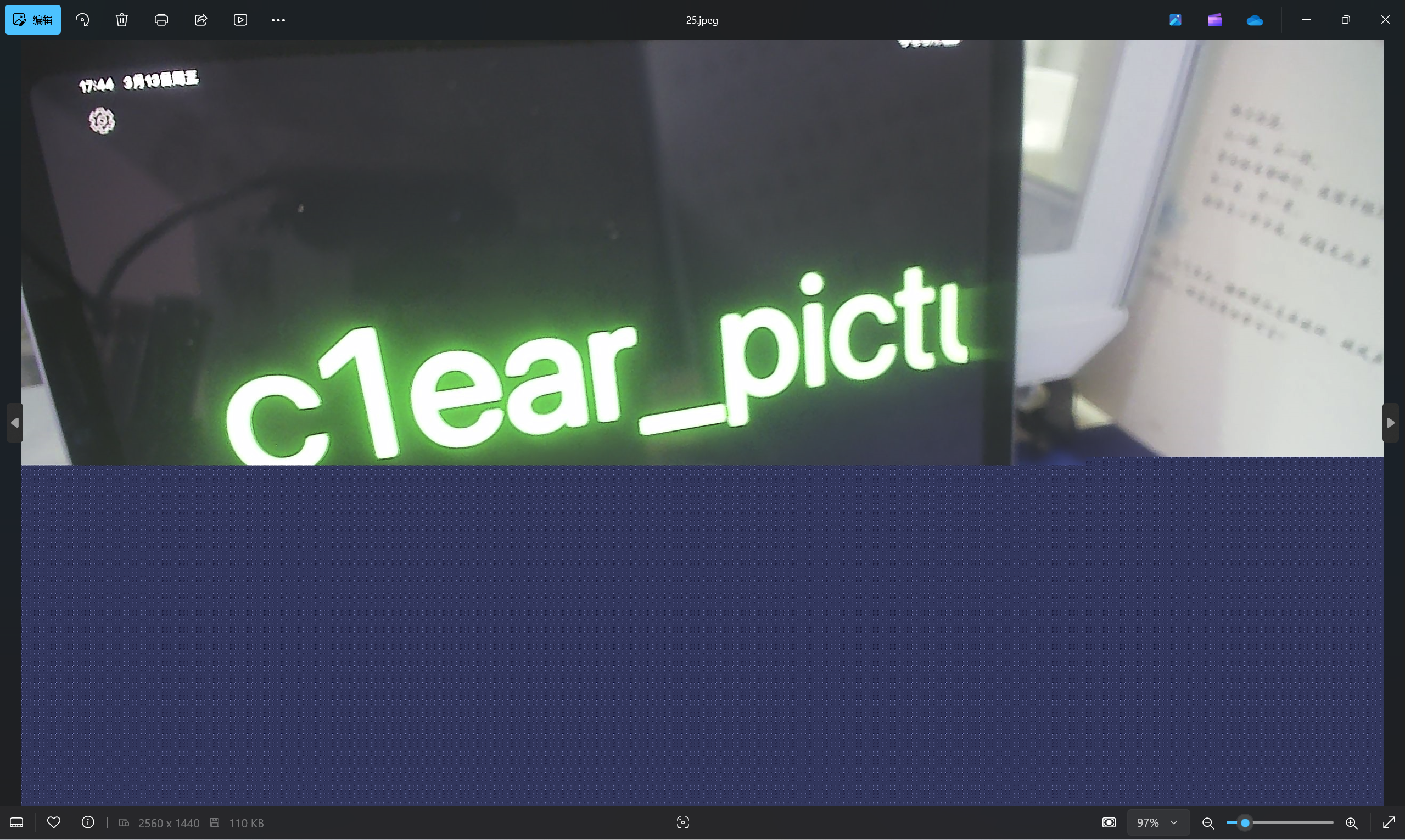
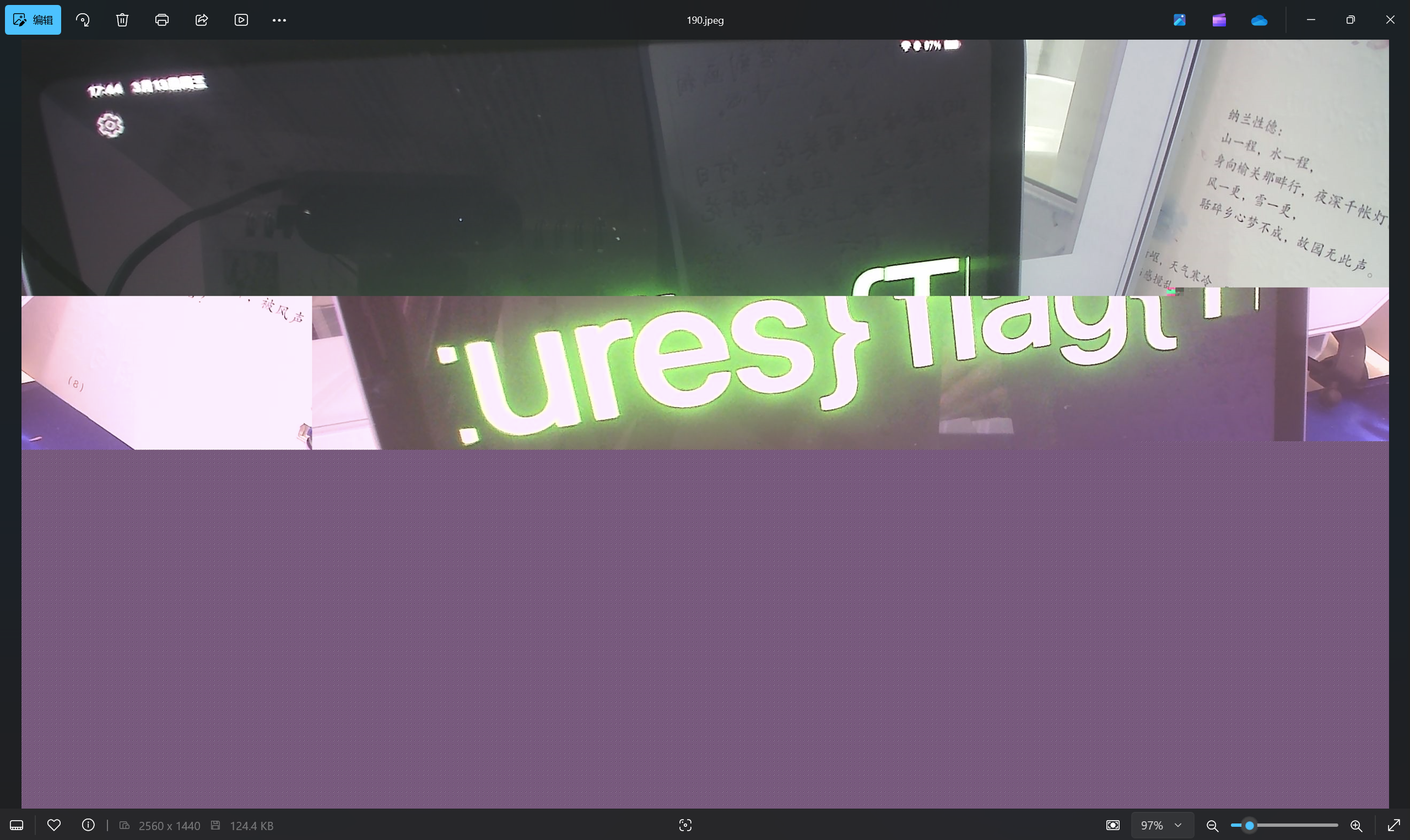
运行得到
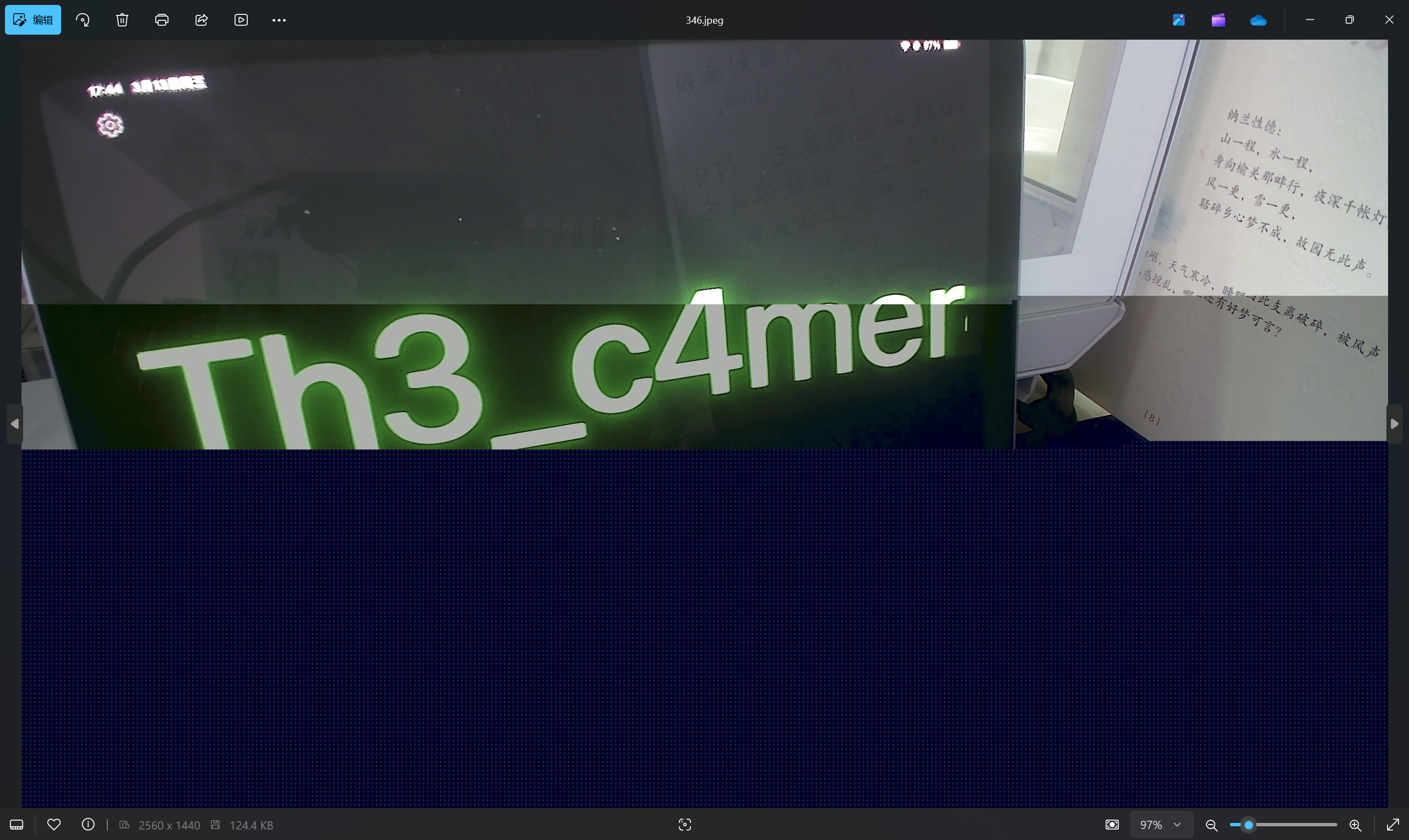
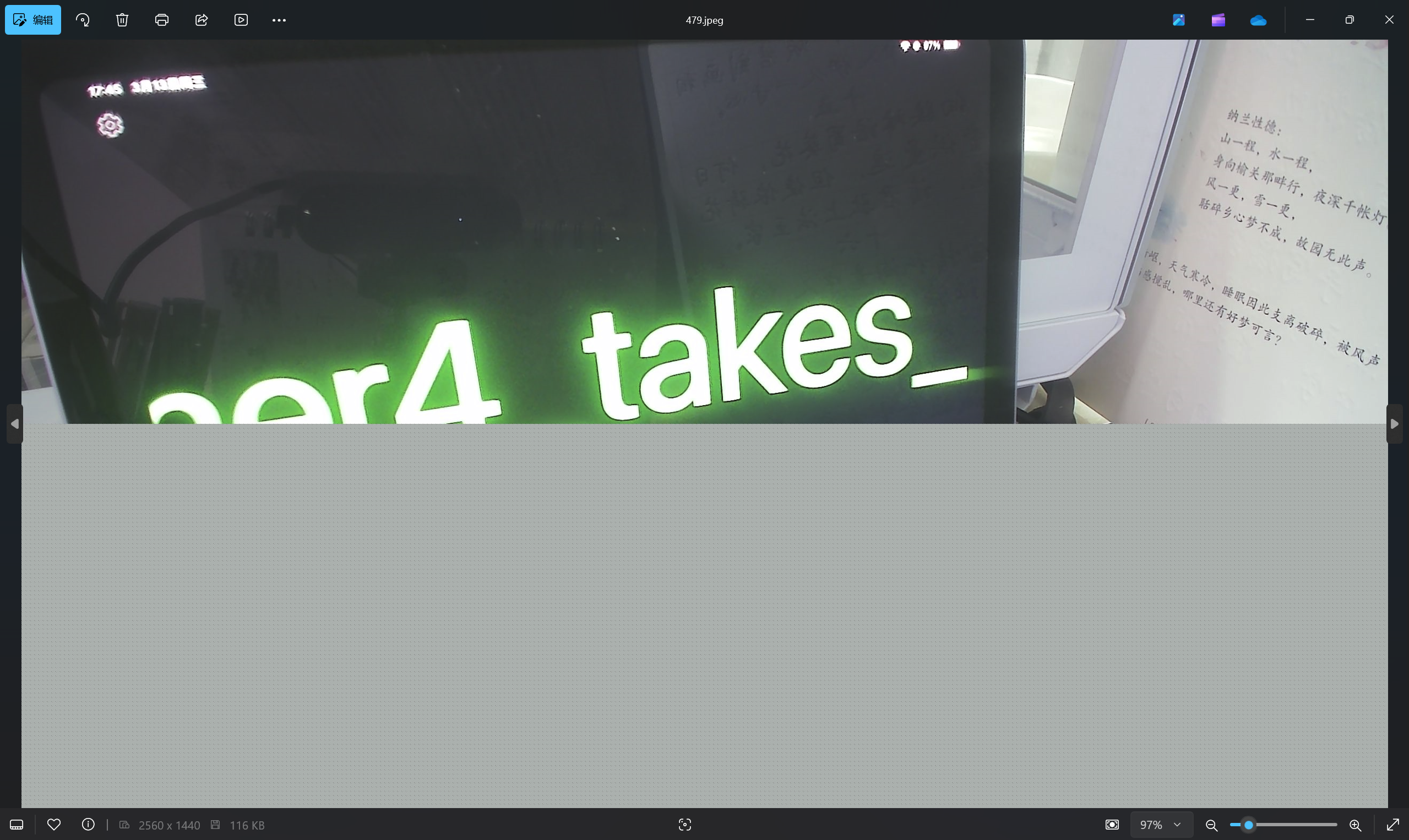
查看images文件夹
最后flag为NepCTF{Th3_c4mer4_takes_c1ear_pictures}